 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Weakly Supervised Audio-Visual Violence Detection in Hyperbolic Space
Paper and Code
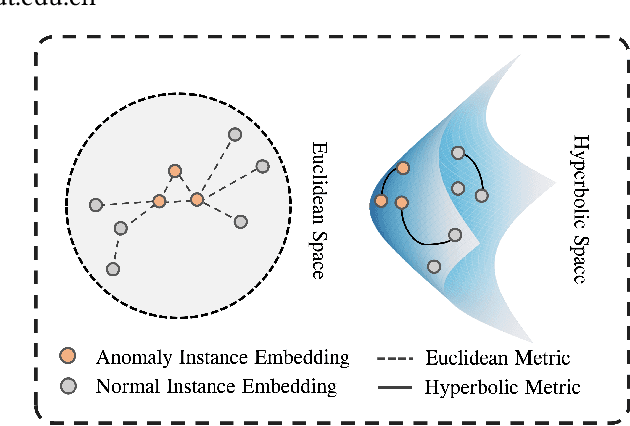
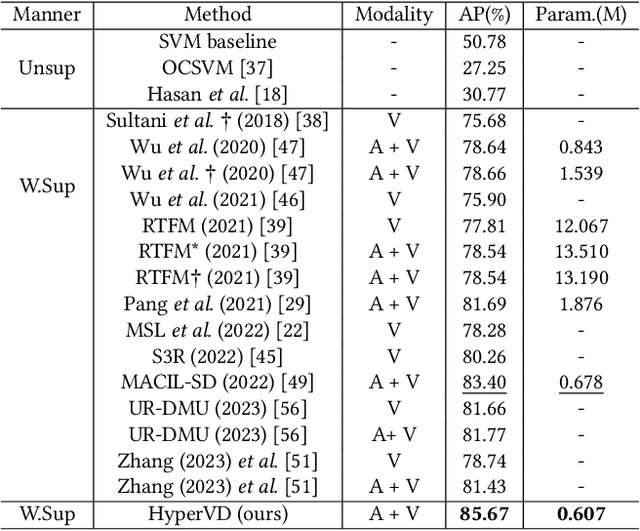
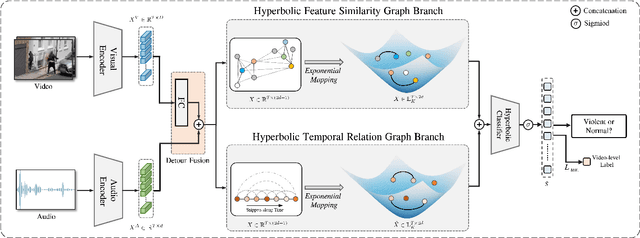
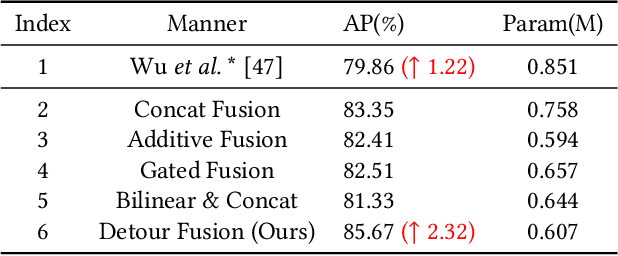
In recent years, the task of weakly supervised audio-visual violence detection has gained considerable attention. The goal of this task is to identify violent segments within multimodal data based on video-level labels. Despite advances in this field, traditional Euclidean neural networks, which have been used in prior research, encounter difficulties in capturing highly discriminative representations due to limitations of the feature space. To overcome this, we propose HyperVD, a novel framework that learns snippet embeddings in hyperbolic space to improve model discrimination. Our framework comprises a detour fusion module for multimodal fusion, effectively alleviating modality inconsistency between audio and visual signals. Additionally, we contribute two branches of fully hyperbolic graph convolutional networks that excavate feature similarities and temporal relationships among snippets in hyperbolic space. By learning snippet representations in this space, the framework effectively learns semantic discrepancies between violent and normal events. Extensive experiments on the XD-Violence benchmark demonstrate that our method outperforms state-of-the-art methods by a sizable margin.