 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Global Weather Models
Feb 26, 2026Data-driven models are revolutionizing weather forecasting. To optimize training efficiency and model performance, this paper analyzes empirical scaling laws within this domain. We investigate the relationship between model performance (validation loss) and three key factors: model size ($N$), dataset size ($D$), and compute budget ($C$). Across a range of models, we find that Aurora exhibits the strongest data-scaling behavior: increasing the training dataset by 10x reduces validation loss by up to 3.2x. GraphCast demonstrates the highest parameter efficiency, yet suffers from limited hardware utilization. Our compute-optimal analysis indicates that, under fixed compute budgets, allocating resources to longer training durations yields greater performance gains than increasing model size. Furthermore, we analyze model shape and uncover scaling behaviors that differ fundamentally from those observed in language models: weather forecasting models consistently favor increased width over depth. These findings suggest that future weather models should prioritize wider architectures and larger effective training datasets to maximize predictive performance.
DiffDA: a diffusion model for weather-scale data assimilation
Jan 11, 2024The generation of initial conditions via accurate data assimilation is crucial for reliable weather forecasting and climate modeling. We propose the DiffDA as a machine learning based data assimilation method capable of assimilating atmospheric variables using predicted states and sparse observations. We adapt the pretrained GraphCast weather forecast model as a denoising diffusion model. Our method applies two-phase conditioning: on the predicted state during both training and inference, and on sparse observations during inference only. As a byproduct, this strategy also enables the post-processing of predictions into the future, for which no observations are available.Through experiments based on a reanalysis dataset, we have verified that our method can produce assimilated global atmospheric data consistent with observations at 0.25degree resolution. The experiments also show that the initial conditions that are generated via our approach can be used for forecast models with a loss of lead time of at most 24 hours when compared to initial conditions of state-of-the-art data assimilation suites. This enables to apply the method to real world applications such as the creation of reanalysis datasets with autoregressive data assimilation.
Compressing multidimensional weather and climate data into neural networks
Oct 22, 2022Weather and climate simulations produce petabytes of high-resolution data that are later analyzed by researchers in order to understand climate change or severe weather. We propose a new method of compressing this multidimensional weather and climate data: a coordinate-based neural network is trained to overfit the data, and the resulting parameters are taken as a compact representation of the original grid-based data. While compression ratios range from 300x to more than 3,000x, our method outperforms the state-of-the-art compressor SZ3 in terms of weighted RMSE, MAE. It can faithfully preserve important large scale atmosphere structures and does not introduce artifacts. When using the resulting neural network as a 790x compressed dataloader to train the WeatherBench forecasting model, its RMSE increases by less than 2%. The three orders of magnitude compression democratizes access to high-resolution climate data and enables numerous new research directions.
ENS-10: A Dataset For Post-Processing Ensemble Weather Forecast
Jun 29, 2022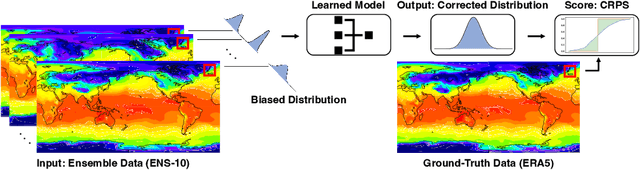
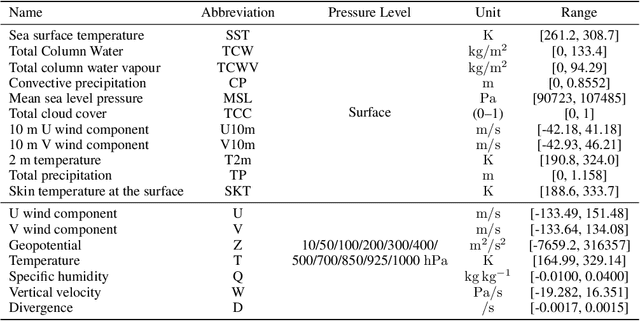
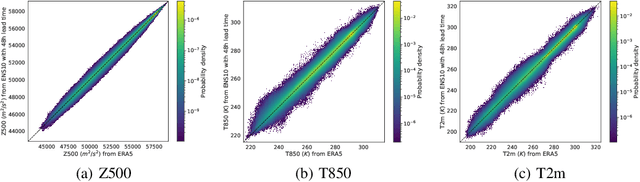
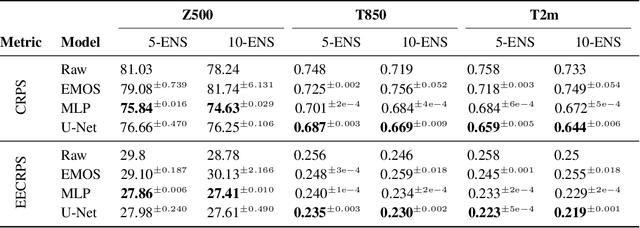
Post-processing ensemble prediction systems can improve weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of the post-processing step. However, these models heavily rely on the data and generating such ensemble members requires multiple runs of numerical weather prediction models, at high computational cost. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spread over 20 years (1998-2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables in 11 distinct pressure levels as well as the surface at 0.5-degree resolution. The dataset targets the prediction correction task at 48-hour lead time, which is essentially improving the forecast quality by removing the biases of the ensemble members. To this end, ENS-10 provides the weather variables for forecast lead times T=0, 24, and 48 hours (two data points per week). We provide a set of baselines for this task on ENS-10 and compare their performance in correcting the prediction of different weather variables. We also assess our baselines for predicting extreme events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) licence.