 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Higher-Order Graph Neural Networks
Jun 18, 2024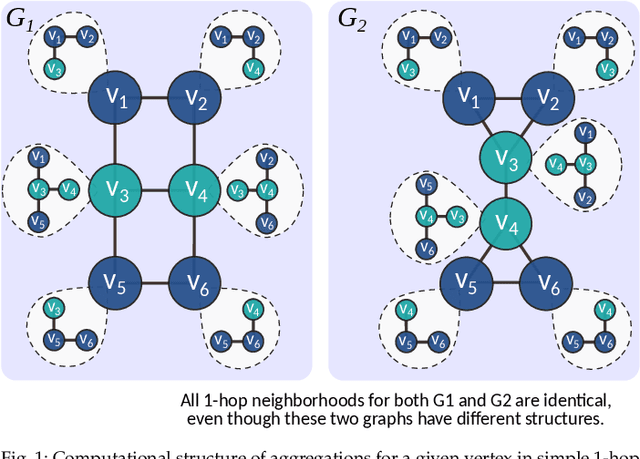

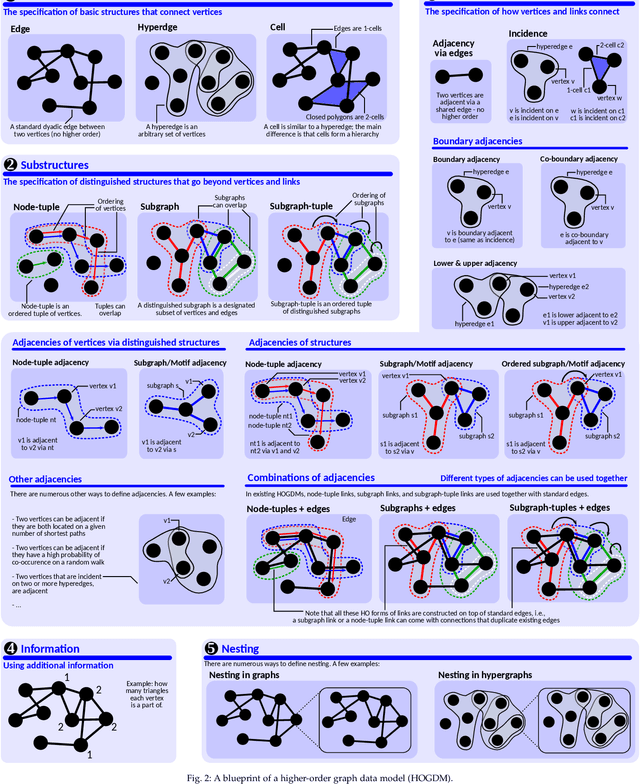
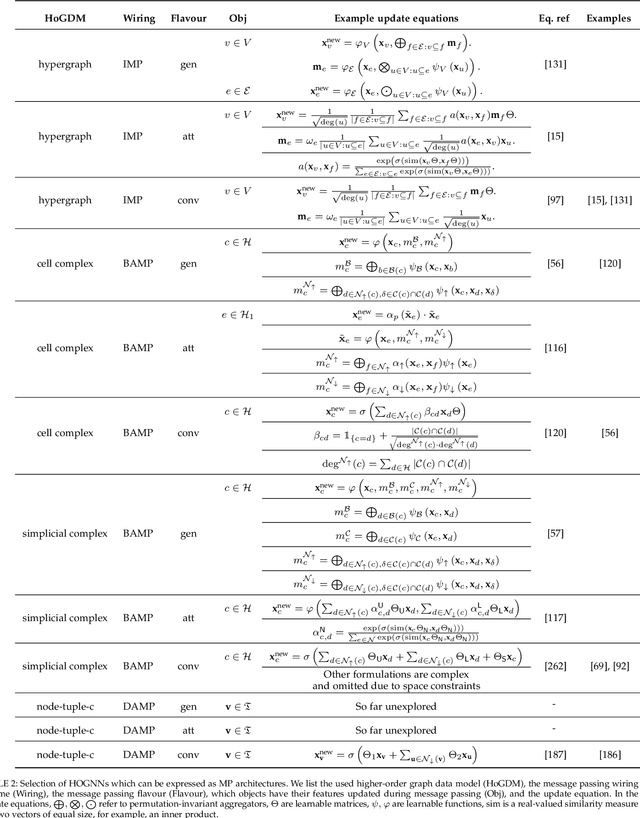
Higher-order graph neural networks (HOGNNs) are an important class of GNN models that harness polyadic relations between vertices beyond plain edges. They have been used to eliminate issues such as over-smoothing or over-squashing, to significantly enhance the accuracy of GNN predictions, to improve the expressiveness of GNN architectures, and for numerous other goals. A plethora of HOGNN models have been introduced, and they come with diverse neural architectures, and even with different notions of what the "higher-order" means. This richness makes it very challenging to appropriately analyze and compare HOGNN models, and to decide in what scenario to use specific ones. To alleviate this, we first design an in-depth taxonomy and a blueprint for HOGNNs. This facilitates designing models that maximize performance. Then, we use our taxonomy to analyze and compare the available HOGNN models. The outcomes of our analysis are synthesized in a set of insights that help to select the most beneficial GNN model in a given scenario, and a comprehensive list of challenges and opportunities for further research into more powerful HOGNNs.
Topologies of Reasoning: Demystifying Chains, Trees, and Graphs of Thoughts
Jan 25, 2024The field of natural language processing (NLP) has witnessed significant progress in recent years, with a notable focus on improving large language models' (LLM) performance through innovative prompting techniques. Among these, prompt engineering coupled with structures has emerged as a promising paradigm, with designs such as Chain-of-Thought, Tree of Thoughts, or Graph of Thoughts, in which the overall LLM reasoning is guided by a structure such as a graph. As illustrated with numerous examples, this paradigm significantly enhances the LLM's capability to solve numerous tasks, ranging from logical or mathematical reasoning to planning or creative writing. To facilitate the understanding of this growing field and pave the way for future developments, we devise a general blueprint for effective and efficient LLM reasoning schemes. For this, we conduct an in-depth analysis of the prompt execution pipeline, clarifying and clearly defining different concepts. We then build the first taxonomy of structure-enhanced LLM reasoning schemes. We focus on identifying fundamental classes of harnessed structures, and we analyze the representations of these structures, algorithms executed with these structures, and many others. We refer to these structures as reasoning topologies, because their representation becomes to a degree spatial, as they are contained within the LLM context. Our study compares existing prompting schemes using the proposed taxonomy, discussing how certain design choices lead to different patterns in performance and cost. We also outline theoretical underpinnings, relationships between prompting and others parts of the LLM ecosystem such as knowledge bases, and the associated research challenges. Our work will help to advance future prompt engineering techniques.
DiffDA: a diffusion model for weather-scale data assimilation
Jan 11, 2024The generation of initial conditions via accurate data assimilation is crucial for reliable weather forecasting and climate modeling. We propose the DiffDA as a machine learning based data assimilation method capable of assimilating atmospheric variables using predicted states and sparse observations. We adapt the pretrained GraphCast weather forecast model as a denoising diffusion model. Our method applies two-phase conditioning: on the predicted state during both training and inference, and on sparse observations during inference only. As a byproduct, this strategy also enables the post-processing of predictions into the future, for which no observations are available.Through experiments based on a reanalysis dataset, we have verified that our method can produce assimilated global atmospheric data consistent with observations at 0.25degree resolution. The experiments also show that the initial conditions that are generated via our approach can be used for forecast models with a loss of lead time of at most 24 hours when compared to initial conditions of state-of-the-art data assimilation suites. This enables to apply the method to real world applications such as the creation of reanalysis datasets with autoregressive data assimilation.
HOT: Higher-Order Dynamic Graph Representation Learning with Efficient Transformers
Nov 30, 2023
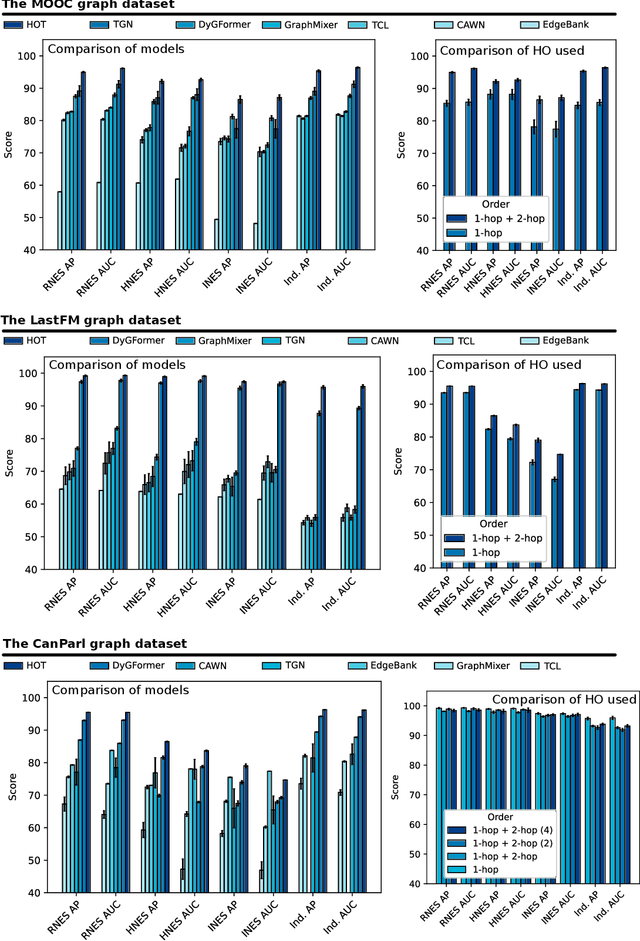

Many graph representation learning (GRL) problems are dynamic, with millions of edges added or removed per second. A fundamental workload in this setting is dynamic link prediction: using a history of graph updates to predict whether a given pair of vertices will become connected. Recent schemes for link prediction in such dynamic settings employ Transformers, modeling individual graph updates as single tokens. In this work, we propose HOT: a model that enhances this line of works by harnessing higher-order (HO) graph structures; specifically, k-hop neighbors and more general subgraphs containing a given pair of vertices. Harnessing such HO structures by encoding them into the attention matrix of the underlying Transformer results in higher accuracy of link prediction outcomes, but at the expense of increased memory pressure. To alleviate this, we resort to a recent class of schemes that impose hierarchy on the attention matrix, significantly reducing memory footprint. The final design offers a sweetspot between high accuracy and low memory utilization. HOT outperforms other dynamic GRL schemes, for example achieving 9%, 7%, and 15% higher accuracy than - respectively - DyGFormer, TGN, and GraphMixer, for the MOOC dataset. Our design can be seamlessly extended towards other dynamic GRL workloads.
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Aug 21, 2023



We introduce Graph of Thoughts (GoT): a framework that advances prompting capabilities in large language models (LLMs) beyond those offered by paradigms such as Chain-of-Thought or Tree of Thoughts (ToT). The key idea and primary advantage of GoT is the ability to model the information generated by an LLM as an arbitrary graph, where units of information ("LLM thoughts") are vertices, and edges correspond to dependencies between these vertices. This approach enables combining arbitrary LLM thoughts into synergistic outcomes, distilling the essence of whole networks of thoughts, or enhancing thoughts using feedback loops. We illustrate that GoT offers advantages over state of the art on different tasks, for example increasing the quality of sorting by 62% over ToT, while simultaneously reducing costs by >31%. We ensure that GoT is extensible with new thought transformations and thus can be used to spearhead new prompting schemes. This work brings the LLM reasoning closer to human thinking or brain mechanisms such as recurrence, both of which form complex networks.
ENS-10: A Dataset For Post-Processing Ensemble Weather Forecast
Jun 29, 2022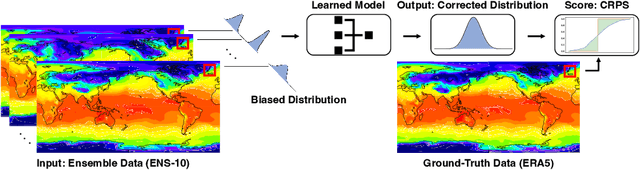
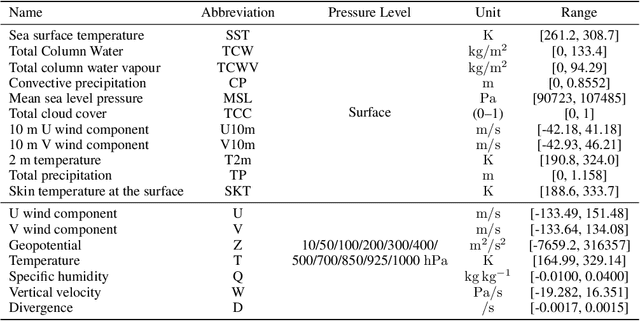
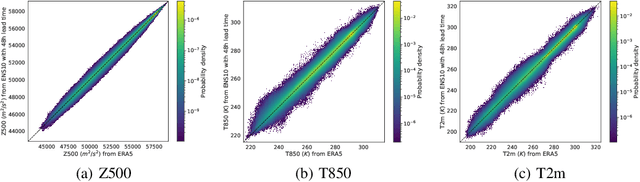
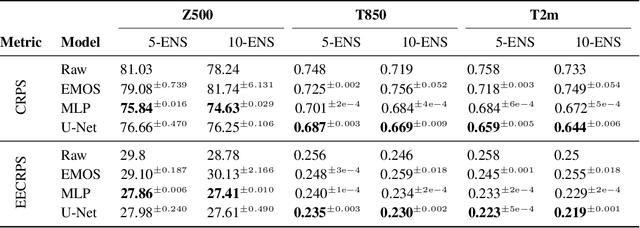
Post-processing ensemble prediction systems can improve weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of the post-processing step. However, these models heavily rely on the data and generating such ensemble members requires multiple runs of numerical weather prediction models, at high computational cost. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spread over 20 years (1998-2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables in 11 distinct pressure levels as well as the surface at 0.5-degree resolution. The dataset targets the prediction correction task at 48-hour lead time, which is essentially improving the forecast quality by removing the biases of the ensemble members. To this end, ENS-10 provides the weather variables for forecast lead times T=0, 24, and 48 hours (two data points per week). We provide a set of baselines for this task on ENS-10 and compare their performance in correcting the prediction of different weather variables. We also assess our baselines for predicting extreme events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) licence.
Learning Combinatorial Node Labeling Algorithms
Jun 15, 2021
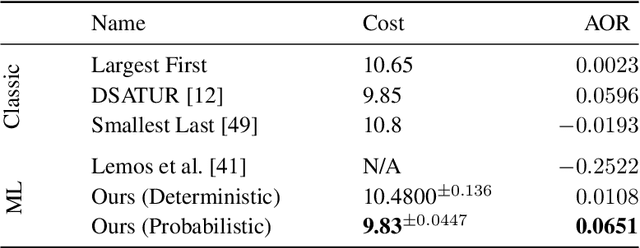
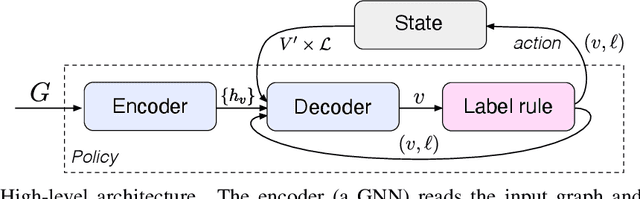

We present a graph neural network to learn graph coloring heuristics using reinforcement learning. Our learned deterministic heuristics give better solutions than classical degree-based greedy heuristics and only take seconds to evaluate on graphs with tens of thousands of vertices. As our approach is based on policy-gradients, it also learns a probabilistic policy as well. These probabilistic policies outperform all greedy coloring baselines and a machine learning baseline. Our approach generalizes several previous machine-learning frameworks, which applied to problems like minimum vertex cover. We also demonstrate that our approach outperforms two greedy heuristics on minimum vertex cover.
Motif Prediction with Graph Neural Networks
Jun 05, 2021
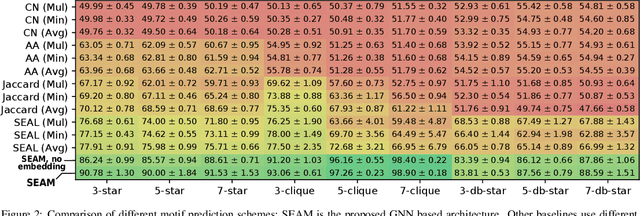
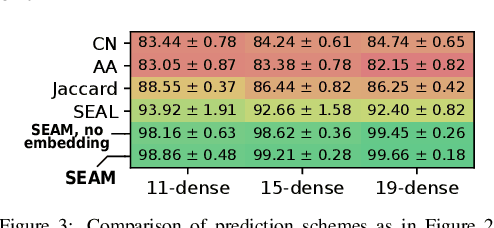
Link prediction is one of the central problems in graph mining. However, recent studies highlight the importance of higher-order network analysis, where complex structures called motifs are the first-class citizens. We first show that existing link prediction schemes fail to effectively predict motifs. To alleviate this, we establish a general motif prediction problem and we propose several heuristics that assess the chances for a specified motif to appear. To make the scores realistic, our heuristics consider - among others - correlations between links, i.e., the potential impact of some arriving links on the appearance of other links in a given motif. Finally, for highest accuracy, we develop a graph neural network (GNN) architecture for motif prediction. Our architecture offers vertex features and sampling schemes that capture the rich structural properties of motifs. While our heuristics are fast and do not need any training, GNNs ensure highest accuracy of predicting motifs, both for dense (e.g., k-cliques) and for sparse ones (e.g., k-stars). We consistently outperform the best available competitor by more than 10% on average and up to 32% in area under the curve. Importantly, the advantages of our approach over schemes based on uncorrelated link prediction increase with the increasing motif size and complexity. We also successfully apply our architecture for predicting more arbitrary clusters and communities, illustrating its potential for graph mining beyond motif analysis.
GraphMineSuite: Enabling High-Performance and Programmable Graph Mining Algorithms with Set Algebra
Mar 05, 2021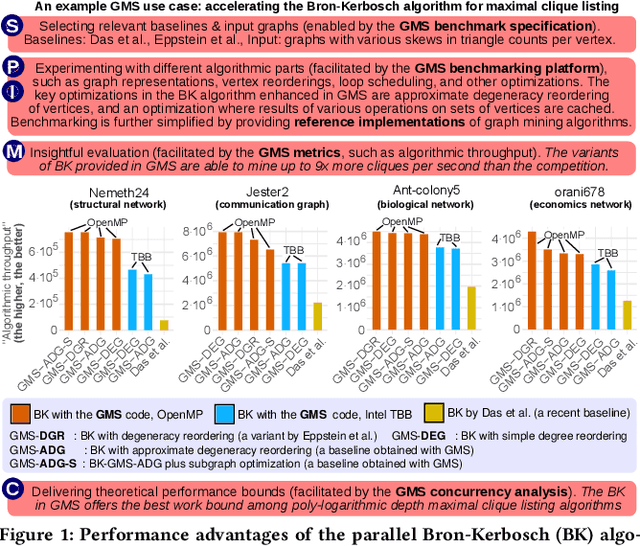

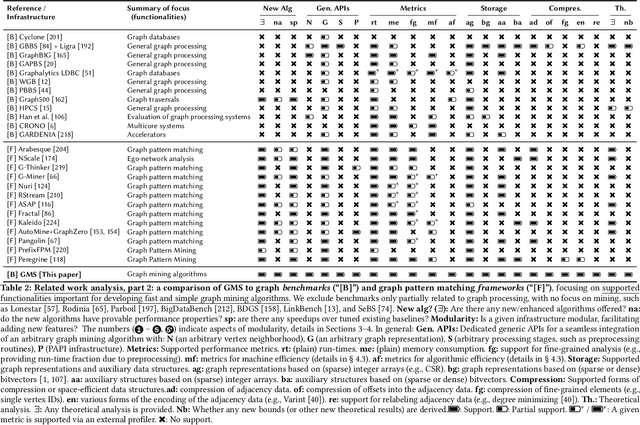
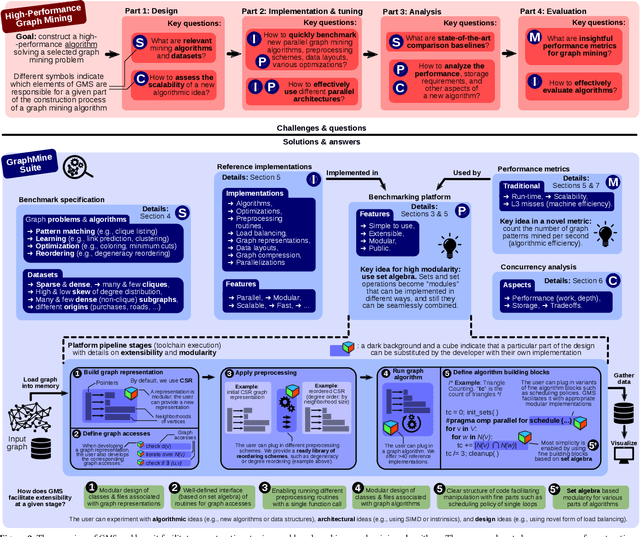
We propose GraphMineSuite (GMS): the first benchmarking suite for graph mining that facilitates evaluating and constructing high-performance graph mining algorithms. First, GMS comes with a benchmark specification based on extensive literature review, prescribing representative problems, algorithms, and datasets. Second, GMS offers a carefully designed software platform for seamless testing of different fine-grained elements of graph mining algorithms, such as graph representations or algorithm subroutines. The platform includes parallel implementations of more than 40 considered baselines, and it facilitates developing complex and fast mining algorithms. High modularity is possible by harnessing set algebra operations such as set intersection and difference, which enables breaking complex graph mining algorithms into simple building blocks that can be separately experimented with. GMS is supported with a broad concurrency analysis for portability in performance insights, and a novel performance metric to assess the throughput of graph mining algorithms, enabling more insightful evaluation. As use cases, we harness GMS to rapidly redesign and accelerate state-of-the-art baselines of core graph mining problems: degeneracy reordering (by up to >2x), maximal clique listing (by up to >9x), k-clique listing (by 1.1x), and subgraph isomorphism (by up to 2.5x), also obtaining better theoretical performance bounds.