 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncomplete U-Statistics of Equireplicate Designs: Berry-Esseen Bound and Efficient Construction
Oct 23, 2025U-statistics are a fundamental class of estimators that generalize the sample mean and underpin much of nonparametric statistics. Although extensively studied in both statistics and probability, key challenges remain: their high computational cost - addressed partly through incomplete U-statistics - and their non-standard asymptotic behavior in the degenerate case, which typically requires resampling methods for hypothesis testing. This paper presents a novel perspective on U-statistics, grounded in hypergraph theory and combinatorial designs. Our approach bypasses the traditional Hoeffding decomposition, the main analytical tool in this literature but one highly sensitive to degeneracy. By characterizing the dependence structure of a U-statistic, we derive a Berry-Esseen bound that applies to all incomplete U-statistics of deterministic designs, yielding conditions under which Gaussian limiting distributions can be established even in the degenerate case and when the order diverges. We also introduce efficient algorithms to construct incomplete U-statistics of equireplicate designs, a subclass of deterministic designs that, in certain cases, achieve minimum variance. Finally, we apply our framework to kernel-based tests that use Maximum Mean Discrepancy (MMD) and Hilbert-Schmidt Independence Criterion. In a real data example with CIFAR-10, our permutation-free MMD test delivers substantial computational gains while retaining power and type I error control.
Motif Prediction with Graph Neural Networks
Jun 05, 2021
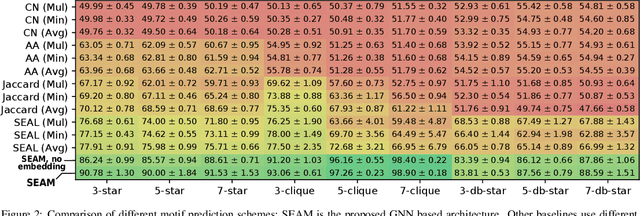
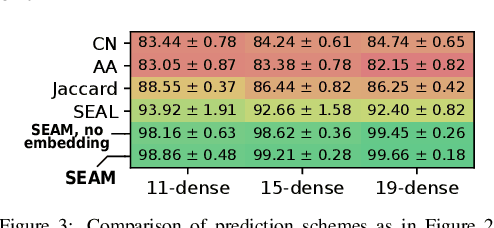
Link prediction is one of the central problems in graph mining. However, recent studies highlight the importance of higher-order network analysis, where complex structures called motifs are the first-class citizens. We first show that existing link prediction schemes fail to effectively predict motifs. To alleviate this, we establish a general motif prediction problem and we propose several heuristics that assess the chances for a specified motif to appear. To make the scores realistic, our heuristics consider - among others - correlations between links, i.e., the potential impact of some arriving links on the appearance of other links in a given motif. Finally, for highest accuracy, we develop a graph neural network (GNN) architecture for motif prediction. Our architecture offers vertex features and sampling schemes that capture the rich structural properties of motifs. While our heuristics are fast and do not need any training, GNNs ensure highest accuracy of predicting motifs, both for dense (e.g., k-cliques) and for sparse ones (e.g., k-stars). We consistently outperform the best available competitor by more than 10% on average and up to 32% in area under the curve. Importantly, the advantages of our approach over schemes based on uncorrelated link prediction increase with the increasing motif size and complexity. We also successfully apply our architecture for predicting more arbitrary clusters and communities, illustrating its potential for graph mining beyond motif analysis.
SWAG: A Wrapper Method for Sparse Learning
Jun 23, 2020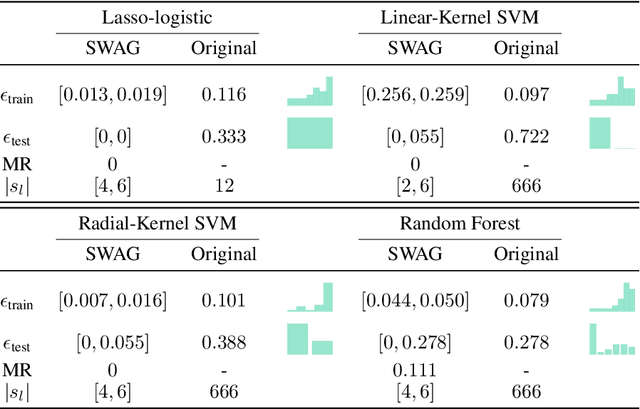

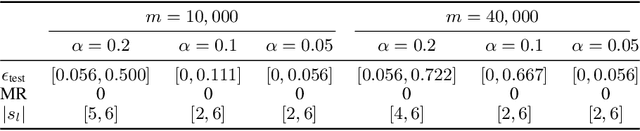

Predictive power has always been the main research focus of learning algorithms. While the general approach for these algorithms is to consider all possible attributes in a dataset to best predict the response of interest, an important branch of research is focused on sparse learning. Indeed, in many practical settings we believe that only an extremely small combination of different attributes affect the response. However even sparse-learning methods can still preserve a high number of attributes in high-dimensional settings and possibly deliver inconsistent prediction performance. The latter methods can also be hard to interpret for researchers and practitioners, a problem which is even more relevant for the ``black-box''-type mechanisms of many learning approaches. Finally, there is often a problem of replicability since not all data-collection procedures measure (or observe) the same attributes and therefore cannot make use of proposed learners for testing purposes. To address all the previous issues, we propose to study a procedure that combines screening and wrapper methods and aims to find a library of extremely low-dimensional attribute combinations (with consequent low data collection and storage costs) in order to (i) match or improve the predictive performance of any particular learning method which uses all attributes as an input (including sparse learners); (ii) provide a low-dimensional network of attributes easily interpretable by researchers and practitioners; and (iii) increase the potential replicability of results due to a diversity of attribute combinations defining strong learners with equivalent predictive power. We call this algorithm ``Sparse Wrapper AlGorithm'' (SWAG).