 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphWalk: Enabling Reasoning in Large Language Models through Tool-Based Graph Navigation
Apr 02, 2026The use of knowledge graphs for grounding agents in real-world Q&A applications has become increasingly common. Answering complex queries often requires multi-hop reasoning and the ability to navigate vast relational structures. Standard approaches rely on prompting techniques that steer large language models to reason over raw graph context, or retrieval-augmented generation pipelines where relevant subgraphs are injected into the context. These, however, face severe limitations with enterprise-scale KGs that cannot fit in even the largest context windows available today. We present GraphWalk, a problem-agnostic, training-free, tool-based framework that allows off-the-shelf LLMs to reason through sequential graph navigation, dramatically increasing performance across different tasks. Unlike task-specific agent frameworks that encode domain knowledge into specialized tools, GraphWalk equips the LLM with a minimal set of orthogonal graph operations sufficient to traverse any graph structure. We evaluate whether models equipped with GraphWalk can compose these operations into correct multi-step reasoning chains, where each tool call represents a verifiable step creating a transparent execution trace. We first demonstrate our approach on maze traversal, a problem non-reasoning models are completely unable to solve, then present results on graphs resembling real-world enterprise knowledge graphs. To isolate structural reasoning from world knowledge, we evaluate on entirely synthetic graphs with random, non-semantic labels. Our benchmark spans 12 query templates from basic retrieval to compound first-order logic queries. Results show that tool-based traversal yields substantial and consistent gains over in-context baselines across all model families tested, with gains becoming more pronounced as scale increases, precisely where in-context approaches fail catastrophically.
GraphSeek: Next-Generation Graph Analytics with LLMs
Feb 11, 2026Graphs are foundational across domains but remain hard to use without deep expertise. LLMs promise accessible natural language (NL) graph analytics, yet they fail to process industry-scale property graphs effectively and efficiently: such datasets are large, highly heterogeneous, structurally complex, and evolve dynamically. To address this, we devise a novel abstraction for complex multi-query analytics over such graphs. Its key idea is to replace brittle generation of graph queries directly from NL with planning over a Semantic Catalog that describes both the graph schema and the graph operations. Concretely, this induces a clean separation between a Semantic Plane for LLM planning and broader reasoning, and an Execution Plane for deterministic, database-grade query execution over the full dataset and tool implementations. This design yields substantial gains in both token efficiency and task effectiveness even with small-context LLMs. We use this abstraction as the basis of the first LLM-enhanced graph analytics framework called GraphSeek. GraphSeek achieves substantially higher success rates (e.g., 86% over enhanced LangChain) and points toward the next generation of affordable and accessible graph analytics that unify LLM reasoning with database-grade execution over large and complex property graphs.
Demystifying Higher-Order Graph Neural Networks
Jun 18, 2024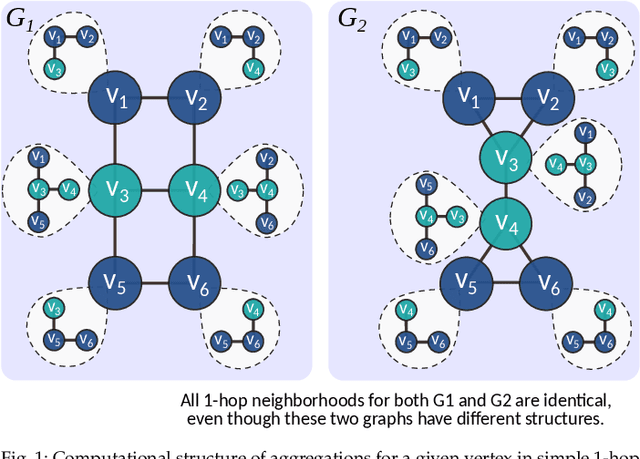

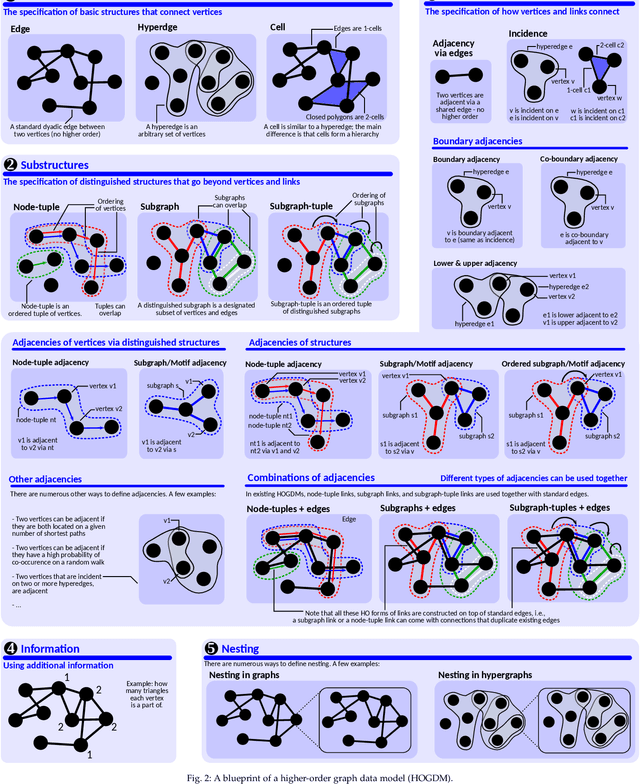
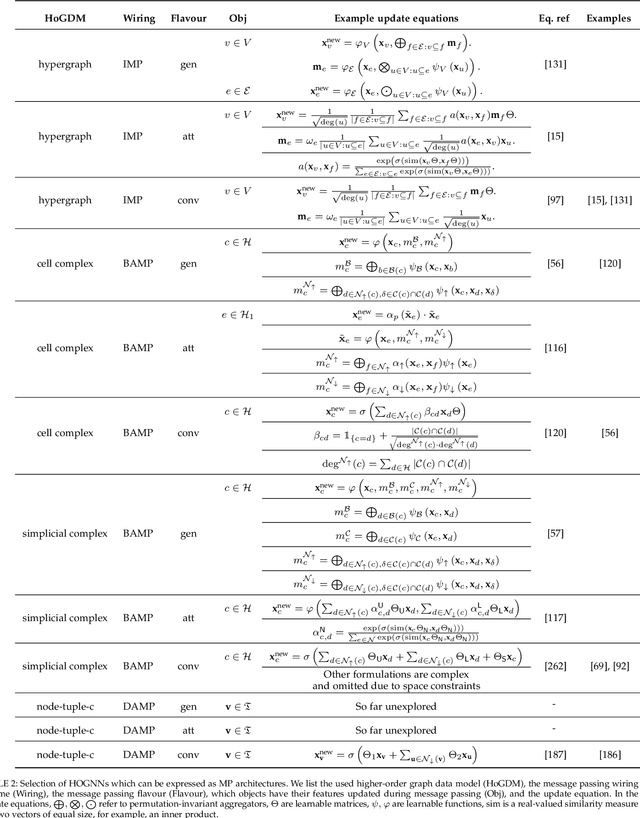
Higher-order graph neural networks (HOGNNs) are an important class of GNN models that harness polyadic relations between vertices beyond plain edges. They have been used to eliminate issues such as over-smoothing or over-squashing, to significantly enhance the accuracy of GNN predictions, to improve the expressiveness of GNN architectures, and for numerous other goals. A plethora of HOGNN models have been introduced, and they come with diverse neural architectures, and even with different notions of what the "higher-order" means. This richness makes it very challenging to appropriately analyze and compare HOGNN models, and to decide in what scenario to use specific ones. To alleviate this, we first design an in-depth taxonomy and a blueprint for HOGNNs. This facilitates designing models that maximize performance. Then, we use our taxonomy to analyze and compare the available HOGNN models. The outcomes of our analysis are synthesized in a set of insights that help to select the most beneficial GNN model in a given scenario, and a comprehensive list of challenges and opportunities for further research into more powerful HOGNNs.
DocReader: Bounding-Box Free Training of a Document Information Extraction Model
May 10, 2021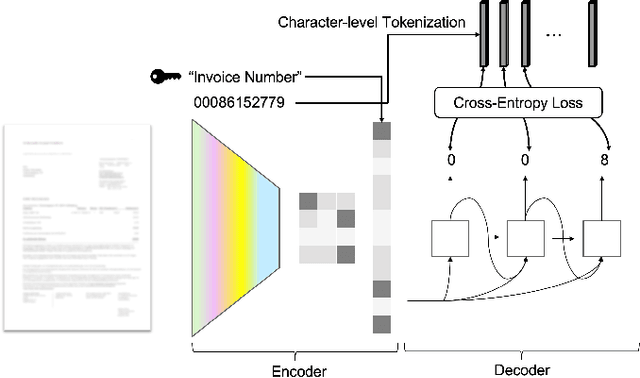

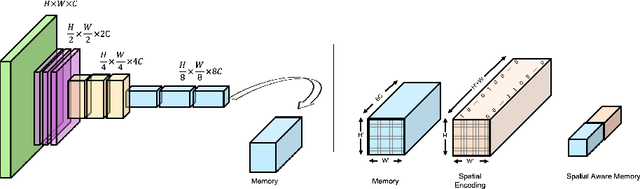
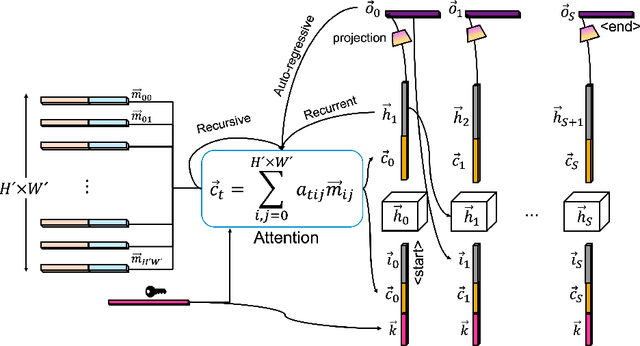
Information extraction from documents is a ubiquitous first step in many business applications. During this step, the entries of various fields must first be read from the images of scanned documents before being further processed and inserted into the corresponding databases. While many different methods have been developed over the past years in order to automate the above extraction step, they all share the requirement of bounding-box or text segment annotations of their training documents. In this work we present DocReader, an end-to-end neural-network-based information extraction solution which can be trained using solely the images and the target values that need to be read. The DocReader can thus leverage existing historical extraction data, completely eliminating the need for any additional annotations beyond what is naturally available in existing human-operated service centres. We demonstrate that the DocReader can reach and surpass other methods which require bounding-boxes for training, as well as provide a clear path for continual learning during its deployment in production.