 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocReader: Bounding-Box Free Training of a Document Information Extraction Model
Paper and Code
May 10, 2021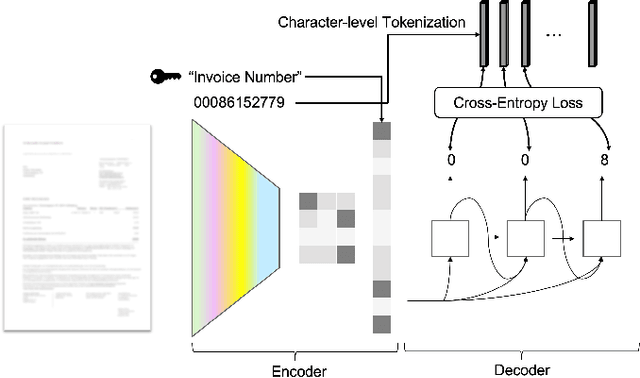

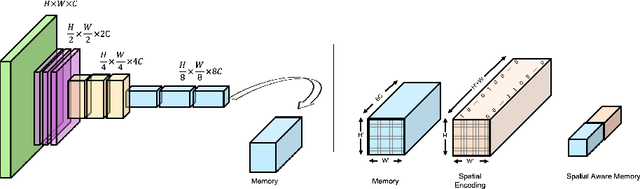
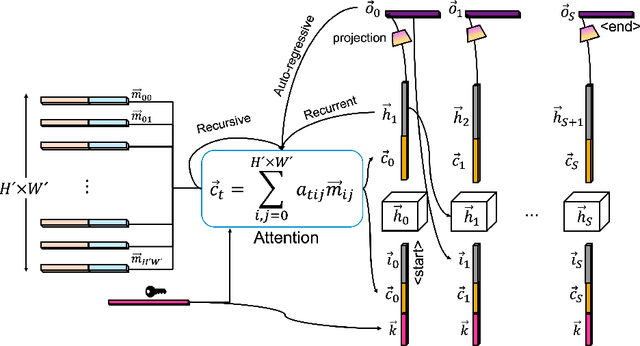
Information extraction from documents is a ubiquitous first step in many business applications. During this step, the entries of various fields must first be read from the images of scanned documents before being further processed and inserted into the corresponding databases. While many different methods have been developed over the past years in order to automate the above extraction step, they all share the requirement of bounding-box or text segment annotations of their training documents. In this work we present DocReader, an end-to-end neural-network-based information extraction solution which can be trained using solely the images and the target values that need to be read. The DocReader can thus leverage existing historical extraction data, completely eliminating the need for any additional annotations beyond what is naturally available in existing human-operated service centres. We demonstrate that the DocReader can reach and surpass other methods which require bounding-boxes for training, as well as provide a clear path for continual learning during its deployment in production.