 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuietPrint: Protecting 3D Printers Against Acoustic Side-Channel Attacks
Feb 02, 2026The 3D printing market has experienced significant growth in recent years, with an estimated revenue of 15 billion USD for 2025. Cyber-attacks targeting the 3D printing process whether through the machine itself, the supply chain, or the fabricated components are becoming increasingly common. One major concern is intellectual property (IP) theft, where a malicious attacker gains access to the design file. One method for carrying out such theft is through side-channel attacks. In this work, we investigate the possibility of IP theft via acoustic side channels and propose a novel method to protect 3D printers against such attacks. The primary advantage of our approach is that it requires no additional hardware, such as large speakers or noise-canceling devices. Instead, it secures printed parts by minimal modifications to the G-code.
Fast Forward: Accelerating LLM Prefill with Predictive FFN Sparsity
Jan 30, 2026The prefill stage of large language model (LLM) inference is a key computational bottleneck for long-context workloads. At short-to-moderate context lengths (1K--16K tokens), Feed-Forward Networks (FFNs) dominate this cost, accounting for most of the total FLOPs. Existing FFN sparsification methods, designed for autoregressive decoding, fail to exploit the prefill stage's parallelism and often degrade accuracy. To address this, we introduce FastForward, a predictive sparsity framework that accelerates LLM prefill through block-wise, context-aware FFN sparsity. FastForward combines (1) a lightweight expert predictor to select high-importance neurons per block, (2) an error compensation network to correct sparsity-induced errors, and (3) a layer-wise sparsity scheduler to allocate compute based on token-mixing importance. Across LLaMA and Qwen models up to 8B parameters, FastForward delivers up to 1.45$\times$ compute-bound speedup at 50% FFN sparsity with $<$ 6% accuracy loss compared to the dense baseline on LongBench, substantially reducing Time-to-First-Token (TTFT) for efficient, long-context LLM inference on constrained hardware.
Polar Sparsity: High Throughput Batched LLM Inferencing with Scalable Contextual Sparsity
May 20, 2025Accelerating large language model (LLM) inference is critical for real-world deployments requiring high throughput and low latency. Contextual sparsity, where each token dynamically activates only a small subset of the model parameters, shows promise but does not scale to large batch sizes due to union of active neurons quickly approaching dense computation. We introduce Polar Sparsity, highlighting a key shift in sparsity importance from MLP to Attention layers as we scale batch size and sequence length. While MLP layers become more compute-efficient under batching, their sparsity vanishes. In contrast, attention becomes increasingly more expensive at scale, while their head sparsity remains stable and batch-invariant. We develop hardware-efficient, sparsity-aware GPU kernels for selective MLP and Attention computations, delivering up to \(2.2\times\) end-to-end speedups for models like OPT, LLaMA-2 \& 3, across various batch sizes and sequence lengths without compromising accuracy. To our knowledge, this is the first work to demonstrate that contextual sparsity can scale effectively to large batch sizes, delivering substantial inference acceleration with minimal changes, making Polar Sparsity practical for large-scale, high-throughput LLM deployment systems. Our code is available at: https://github.com/susavlsh10/Polar-Sparsity.
ESPN: Memory-Efficient Multi-Vector Information Retrieval
Dec 09, 2023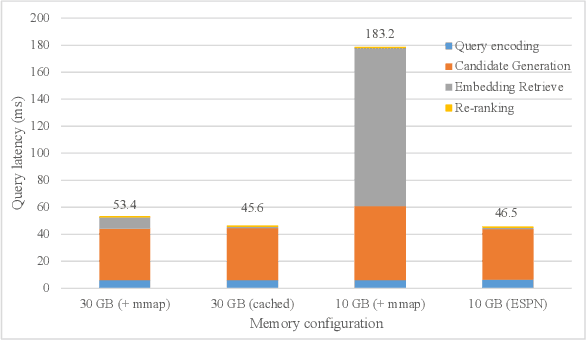



Recent advances in large language models have demonstrated remarkable effectiveness in information retrieval (IR) tasks. While many neural IR systems encode queries and documents into single-vector representations, multi-vector models elevate the retrieval quality by producing multi-vector representations and facilitating similarity searches at the granularity of individual tokens. However, these models significantly amplify memory and storage requirements for retrieval indices by an order of magnitude. This escalation in index size renders the scalability of multi-vector IR models progressively challenging due to their substantial memory demands. We introduce Embedding from Storage Pipelined Network (ESPN) where we offload the entire re-ranking embedding tables to SSDs and reduce the memory requirements by 5-16x. We design a software prefetcher with hit rates exceeding 90%, improving SSD based retrieval up to 6.4x, and demonstrate that we can maintain near memory levels of query latency even for large query batch sizes.