 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning, Solving and Optimizing PDEs with TensorGalerkin: an efficient high-performance Galerkin assembly algorithm
Feb 04, 2026We present a unified algorithmic framework for the numerical solution, constrained optimization, and physics-informed learning of PDEs with a variational structure. Our framework is based on a Galerkin discretization of the underlying variational forms, and its high efficiency stems from a novel highly-optimized and GPU-compliant TensorGalerkin framework for linear system assembly (stiffness matrices and load vectors). TensorGalerkin operates by tensorizing element-wise operations within a Python-level Map stage and then performs global reduction with a sparse matrix multiplication that performs message passing on the mesh-induced sparsity graph. It can be seamlessly employed downstream as i) a highly-efficient numerical PDEs solver, ii) an end-to-end differentiable framework for PDE-constrained optimization, and iii) a physics-informed operator learning algorithm for PDEs. With multiple benchmarks, including 2D and 3D elliptic, parabolic, and hyperbolic PDEs on unstructured meshes, we demonstrate that the proposed framework provides significant computational efficiency and accuracy gains over a variety of baselines in all the targeted downstream applications.
torch-sla: Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch
Jan 20, 2026Industrial scientific computing predominantly uses sparse matrices to represent unstructured data -- finite element meshes, graphs, point clouds. We present \torchsla{}, an open-source PyTorch library that enables GPU-accelerated, scalable, and differentiable sparse linear algebra. The library addresses three fundamental challenges: (1) GPU acceleration for sparse linear solves, nonlinear solves (Newton, Picard, Anderson), and eigenvalue computation; (2) Multi-GPU scaling via domain decomposition with halo exchange, reaching \textbf{400 million DOF linear solve on 3 GPUs}; and (3) Adjoint-based differentiation} achieving $\mathcal{O}(1)$ computational graph nodes (for autograd) and $\mathcal{O}(\text{nnz})$ memory -- independent of solver iterations. \torchsla{} supports multiple backends (SciPy, cuDSS, PyTorch-native) and seamlessly integrates with PyTorch autograd for end-to-end differentiable simulations. Code is available at https://github.com/walkerchi/torch-sla.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Multi-Head RAG: Solving Multi-Aspect Problems with LLMs
Jun 07, 2024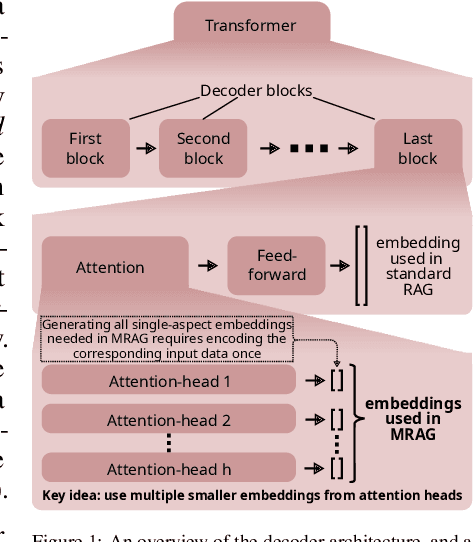

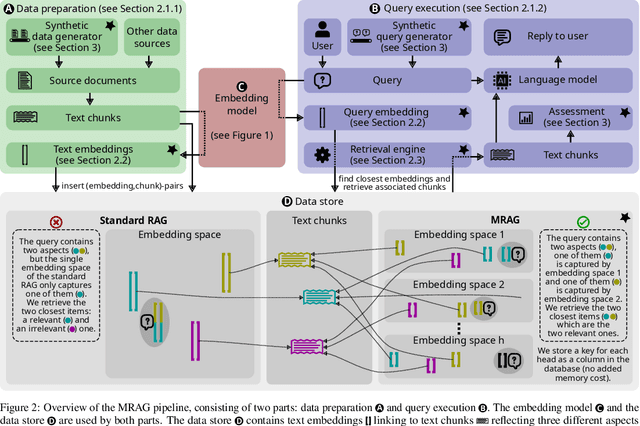

Retrieval Augmented Generation (RAG) enhances the abilities of Large Language Models (LLMs) by enabling the retrieval of documents into the LLM context to provide more accurate and relevant responses. Existing RAG solutions do not focus on queries that may require fetching multiple documents with substantially different contents. Such queries occur frequently, but are challenging because the embeddings of these documents may be distant in the embedding space, making it hard to retrieve them all. This paper introduces Multi-Head RAG (MRAG), a novel scheme designed to address this gap with a simple yet powerful idea: leveraging activations of Transformer's multi-head attention layer, instead of the decoder layer, as keys for fetching multi-aspect documents. The driving motivation is that different attention heads can learn to capture different data aspects. Harnessing the corresponding activations results in embeddings that represent various facets of data items and queries, improving the retrieval accuracy for complex queries. We provide an evaluation methodology and metrics, synthetic datasets, and real-world use cases to demonstrate MRAG's effectiveness, showing improvements of up to 20% in relevance over standard RAG baselines. MRAG can be seamlessly integrated with existing RAG frameworks and benchmarking tools like RAGAS as well as different classes of data stores.
Model Cascades for Efficient Image Search
Mar 27, 2023Modern neural encoders offer unprecedented text-image retrieval (TIR) accuracy. However, their high computational cost impedes an adoption to large-scale image searches. We propose a novel image ranking algorithm that uses a cascade of increasingly powerful neural encoders to progressively filter images by how well they match a given text. Our algorithm reduces lifetime TIR costs by over 3x.