 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust sensitivity control in digital pathology via tile score distribution matching
Feb 28, 2025



Deploying digital pathology models across medical centers is challenging due to distribution shifts. Recent advances in domain generalization improve model transferability in terms of aggregated performance measured by the Area Under Curve (AUC). However, clinical regulations often require to control the transferability of other metrics, such as prescribed sensitivity levels. We introduce a novel approach to control the sensitivity of whole slide image (WSI) classification models, based on optimal transport and Multiple Instance Learning (MIL). Validated across multiple cohorts and tasks, our method enables robust sensitivity control with only a handful of calibration samples, providing a practical solution for reliable deployment of computational pathology systems.
Legitimate ground-truth-free metrics for deep uncertainty classification scoring
Oct 30, 2024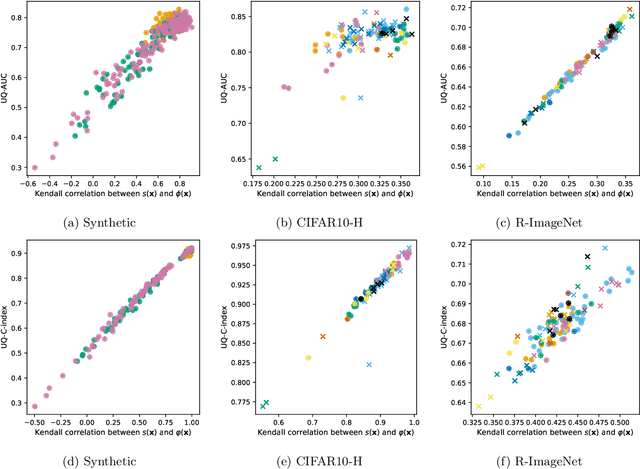

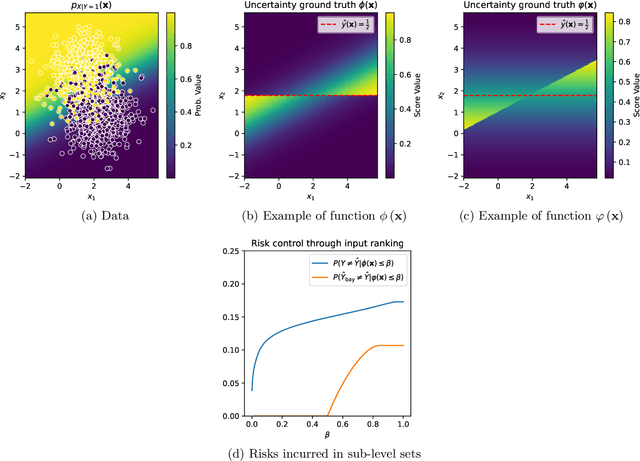
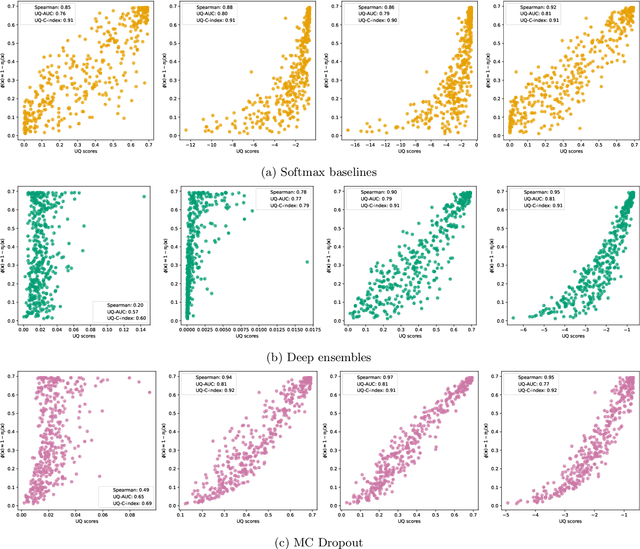
Despite the increasing demand for safer machine learning practices, the use of Uncertainty Quantification (UQ) methods in production remains limited. This limitation is exacerbated by the challenge of validating UQ methods in absence of UQ ground truth. In classification tasks, when only a usual set of test data is at hand, several authors suggested different metrics that can be computed from such test points while assessing the quality of quantified uncertainties. This paper investigates such metrics and proves that they are theoretically well-behaved and actually tied to some uncertainty ground truth which is easily interpretable in terms of model prediction trustworthiness ranking. Equipped with those new results, and given the applicability of those metrics in the usual supervised paradigm, we argue that our contributions will help promoting a broader use of UQ in deep learning.
Self-supervised U-net for few-shot learning of object segmentation in microscopy images
May 22, 2022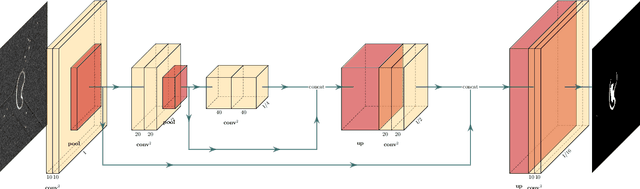
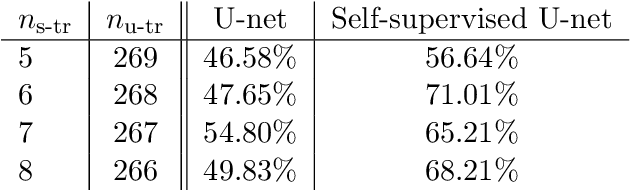
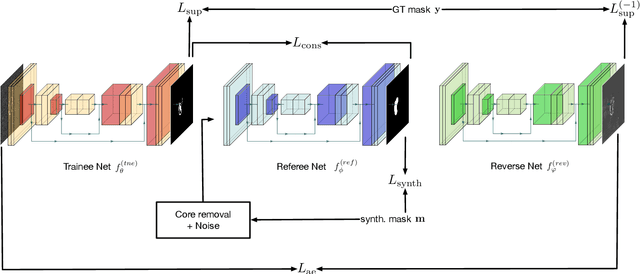

State-of-the-art segmentation performances are achieved by deep neural networks. Training these networks from only a few training examples is challenging while producing annotated images that provide supervision is tedious. Recently, self-supervision, i.e. designing a neural pipeline providing synthetic or indirect supervision, has proved to significantly increase generalization performances of models trained on few shots. This paper introduces one such neural pipeline in the context of microscopic image segmentation. By leveraging the rather simple content of these images a trainee network can be mentored by a referee network which has been previously trained on synthetically generated pairs of corrupted/correct region masks.
State space partitioning based on constrained spectral clustering for block particle filtering
Mar 07, 2022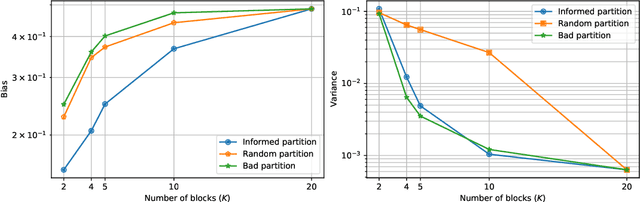
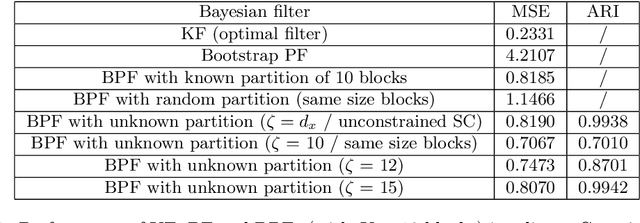
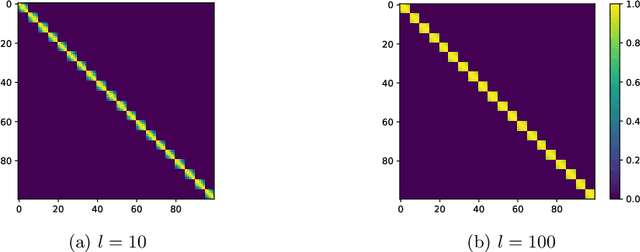

The particle filter (PF) is a powerful inference tool widely used to estimate the filtering distribution in non-linear and/or non-Gaussian problems. To overcome the curse of dimensionality of PF, the block PF (BPF) inserts a blocking step to partition the state space into several subspaces or blocks of smaller dimension so that the correction and resampling steps can be performed independently on each subspace. Using blocks of small size reduces the variance of the filtering distribution estimate, but in turn the correlation between blocks is broken and a bias is introduced. When the dependence relationships between state variables are unknown, it is not obvious to decide how to split the state space into blocks and a significant error overhead may arise from a poor choice of partitioning. In this paper, we formulate the partitioning problem in the BPF as a clustering problem and we propose a state space partitioning method based on spectral clustering (SC). We design a generalized BPF algorithm that contains two new steps: (i) estimation of the state vector correlation matrix from predicted particles, (ii) SC using this estimate as the similarity matrix to determine an appropriate partition. In addition, a constraint is imposed on the maximal cluster size to prevent SC from providing too large blocks. We show that the proposed method can bring together in the same blocks the most correlated state variables while successfully escaping the curse of dimensionality.
SODA: Self-organizing data augmentation in deep neural networks -- Application to biomedical image segmentation tasks
Feb 07, 2022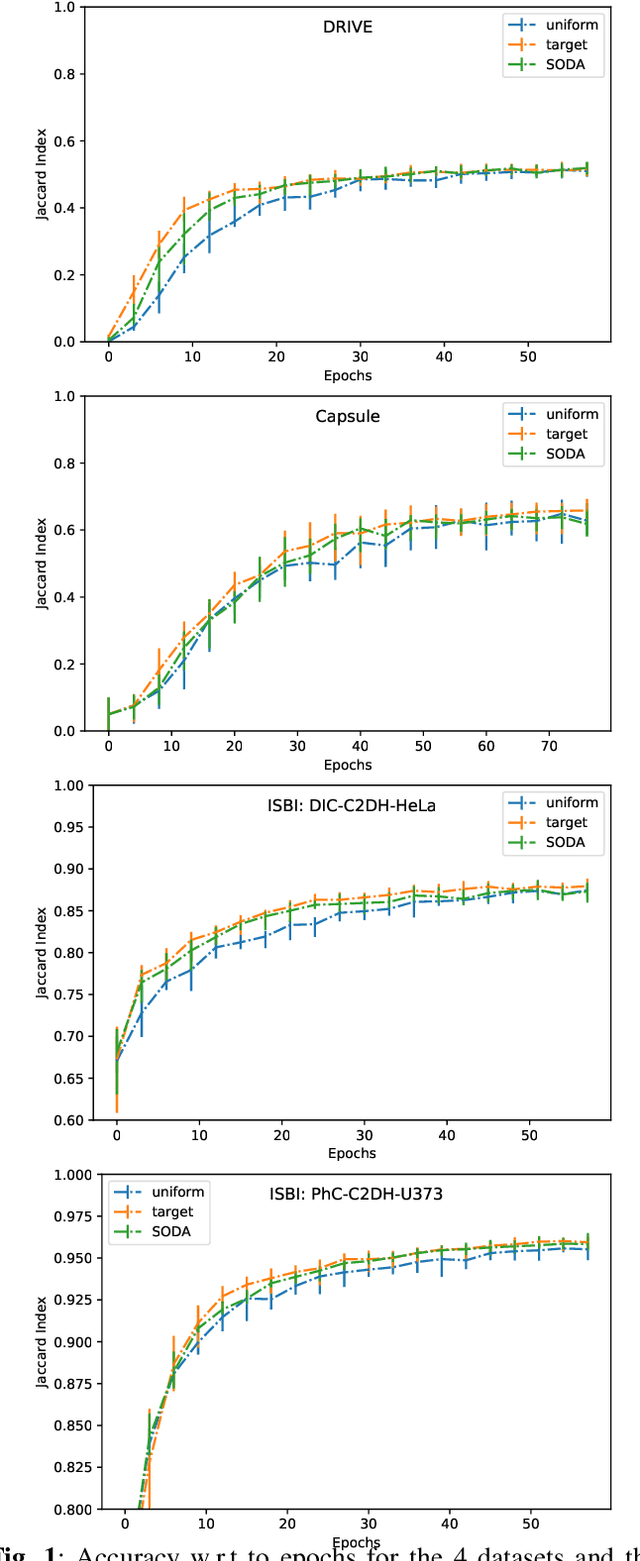

In practice, data augmentation is assigned a predefined budget in terms of newly created samples per epoch. When using several types of data augmentation, the budget is usually uniformly distributed over the set of augmentations but one can wonder if this budget should not be allocated to each type in a more efficient way. This paper leverages online learning to allocate on the fly this budget as part of neural network training. This meta-algorithm can be run at almost no extra cost as it exploits gradient based signals to determine which type of data augmentation should be preferred. Experiments suggest that this strategy can save computation time and thus goes in the way of greener machine learning practices.
SPOCC: Scalable POssibilistic Classifier Combination -- toward robust aggregation of classifiers
Aug 18, 2019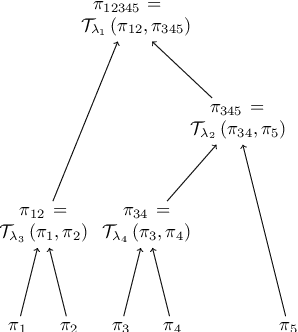
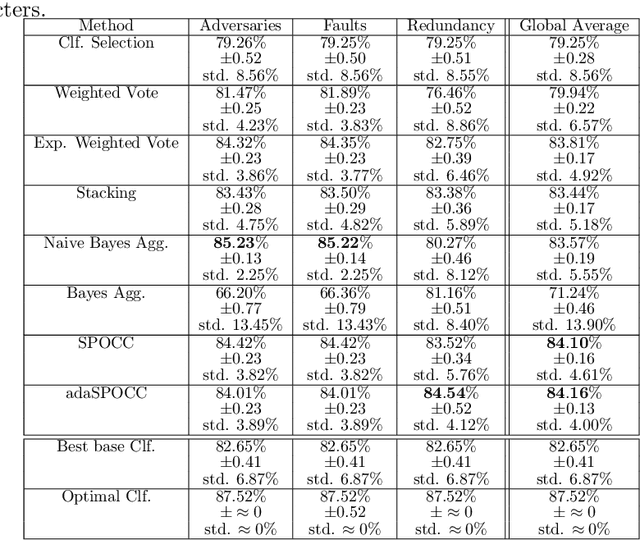
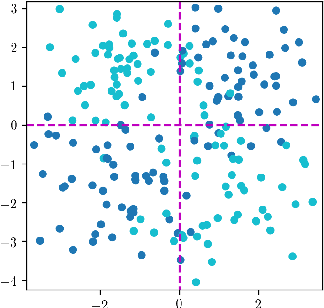
We investigate a problem in which each member of a group of learners is trained separately to solve the same classification task. Each learner has access to a training dataset (possibly with overlap across learners) but each trained classifier can be evaluated on a validation dataset. We propose a new approach to aggregate the learner predictions in the possibility theory framework. For each classifier prediction, we build a possibility distribution assessing how likely the classifier prediction is correct using frequentist probabilities estimated on the validation set. The possibility distributions are aggregated using an adaptive t-norm that can accommodate dependency and poor accuracy of the classifier predictions. We prove that the proposed approach possesses a number of desirable classifier combination robustness properties.
Decentralized learning with budgeted network load using Gaussian copulas and classifier ensembles
Apr 26, 2018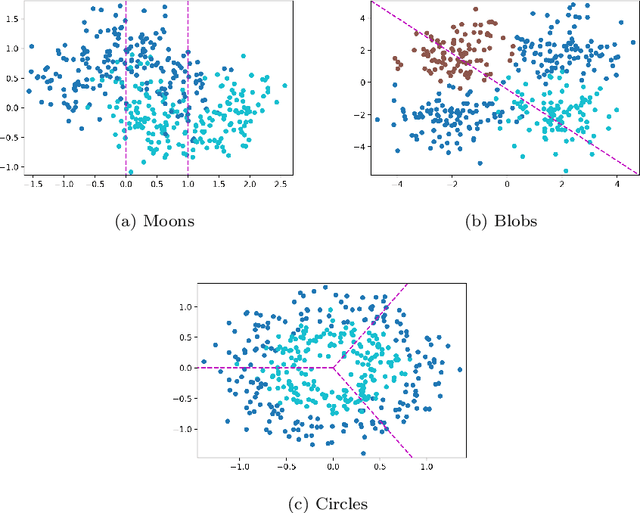
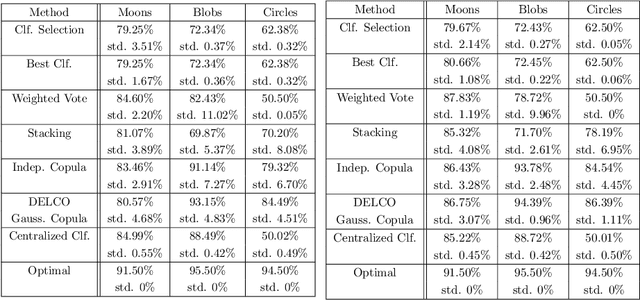
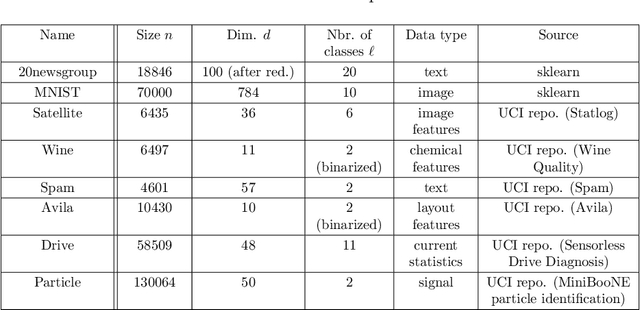
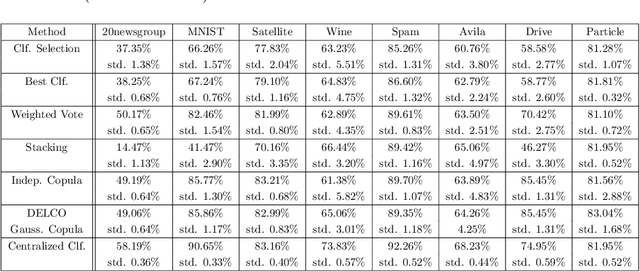
We examine a network of learners which address the same classification task but must learn from different data sets. The learners can share a limited portion of their data sets so as to preserve the network load. We introduce DELCO (standing for Decentralized Ensemble Learning with COpulas), a new approach in which the shared data and the trained models are sent to a central machine that allows to build an ensemble of classifiers. The proposed method aggregates the base classifiers using a probabilistic model relying on Gaussian copulas. Experiments on logistic regressor ensembles demonstrate competing accuracy and increased robustness as compared to gold standard approaches. A companion python implementation can be downloaded at https://github.com/john-klein/DELCO