 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegitimate ground-truth-free metrics for deep uncertainty classification scoring
Paper and Code
Oct 30, 2024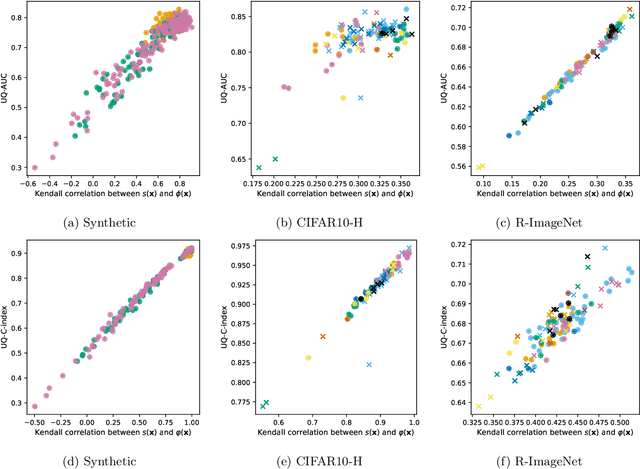

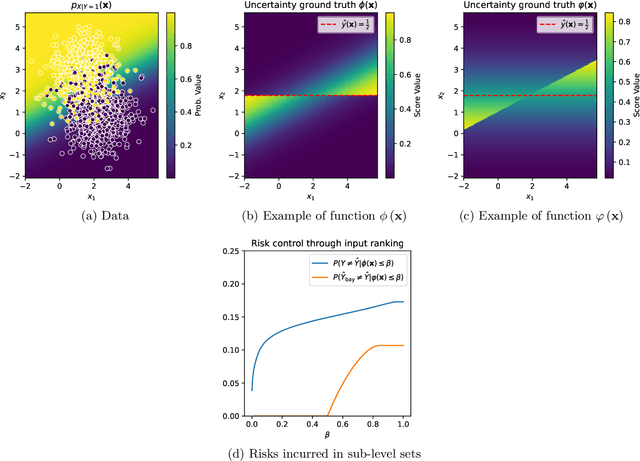
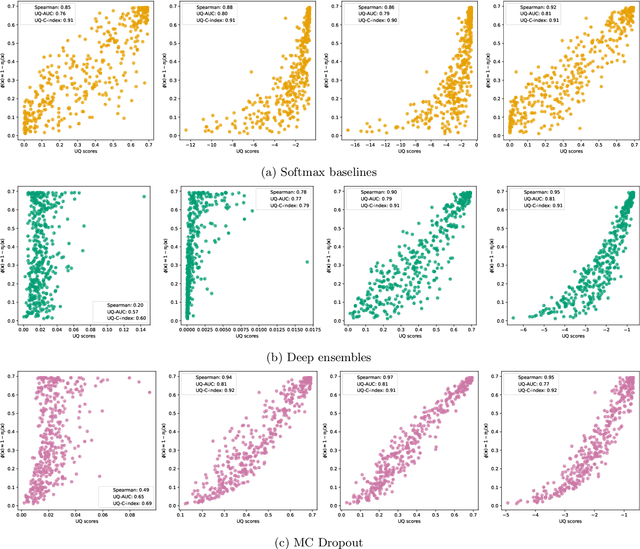
Despite the increasing demand for safer machine learning practices, the use of Uncertainty Quantification (UQ) methods in production remains limited. This limitation is exacerbated by the challenge of validating UQ methods in absence of UQ ground truth. In classification tasks, when only a usual set of test data is at hand, several authors suggested different metrics that can be computed from such test points while assessing the quality of quantified uncertainties. This paper investigates such metrics and proves that they are theoretically well-behaved and actually tied to some uncertainty ground truth which is easily interpretable in terms of model prediction trustworthiness ranking. Equipped with those new results, and given the applicability of those metrics in the usual supervised paradigm, we argue that our contributions will help promoting a broader use of UQ in deep learning.