Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODA: Self-organizing data augmentation in deep neural networks -- Application to biomedical image segmentation tasks
Paper and Code
Feb 07, 2022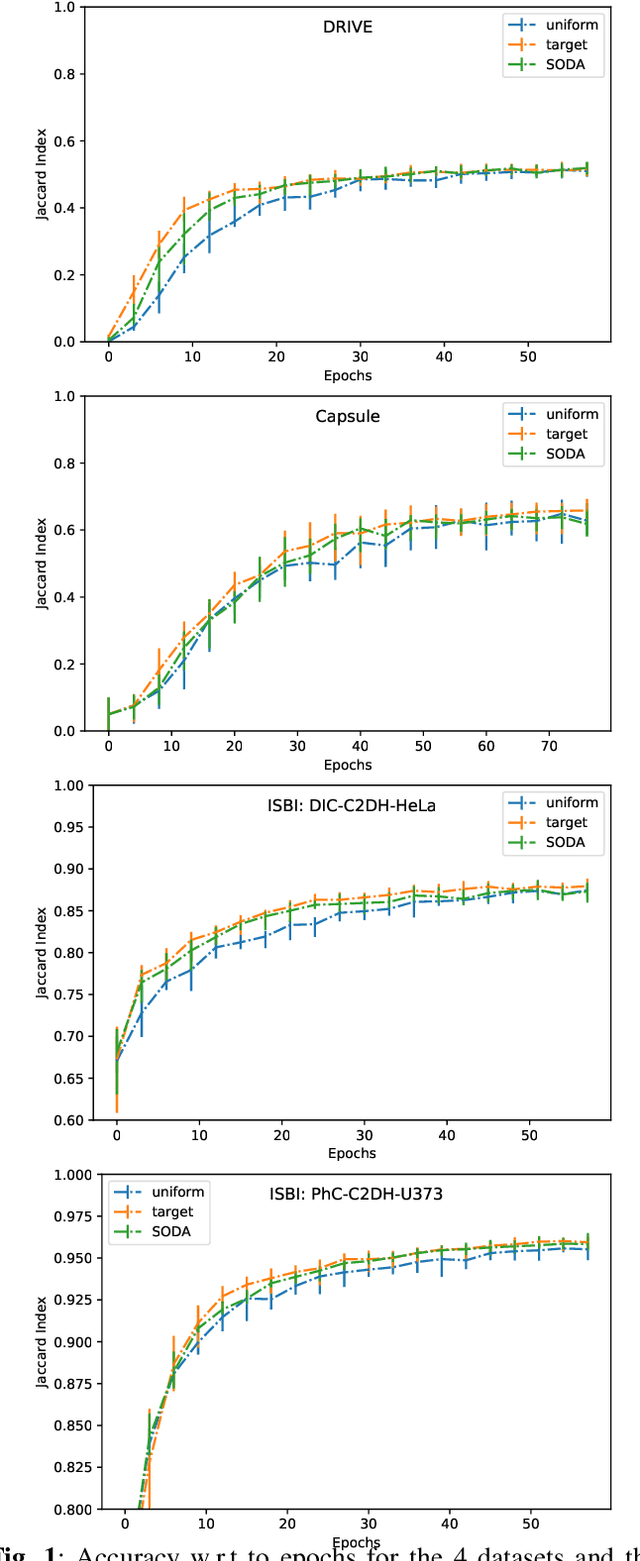

In practice, data augmentation is assigned a predefined budget in terms of newly created samples per epoch. When using several types of data augmentation, the budget is usually uniformly distributed over the set of augmentations but one can wonder if this budget should not be allocated to each type in a more efficient way. This paper leverages online learning to allocate on the fly this budget as part of neural network training. This meta-algorithm can be run at almost no extra cost as it exploits gradient based signals to determine which type of data augmentation should be preferred. Experiments suggest that this strategy can save computation time and thus goes in the way of greener machine learning practices.
View paper on