 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Structure of Auto-Encoding Recommenders
Aug 18, 2020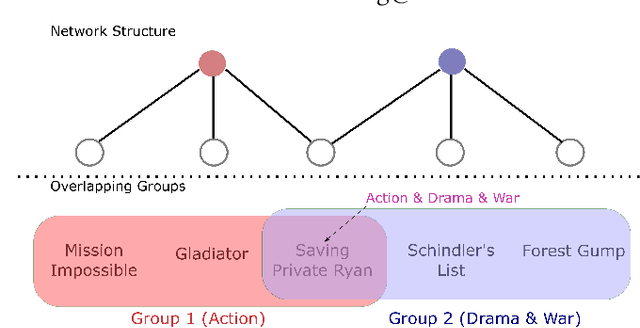
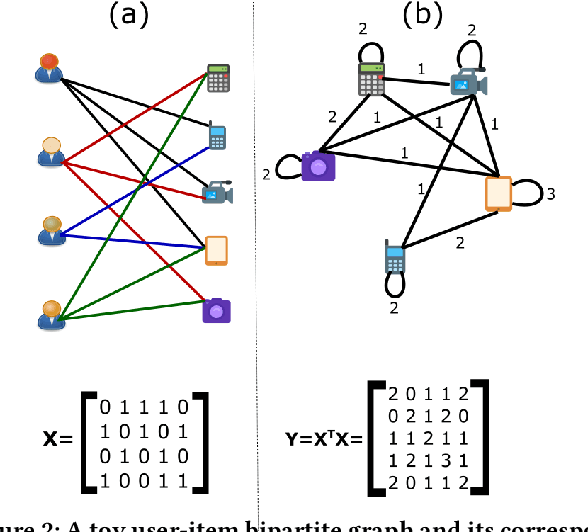
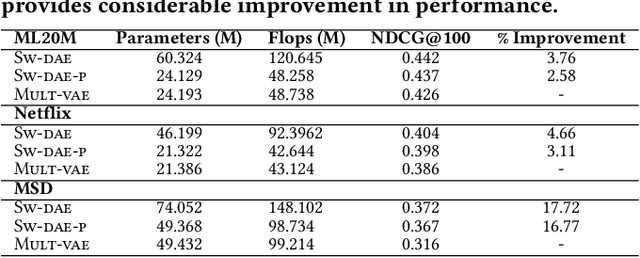
Autoencoder recommenders have recently shown state-of-the-art performance in the recommendation task due to their ability to model non-linear item relationships effectively. However, existing autoencoder recommenders use fully-connected neural network layers and do not employ structure learning. This can lead to inefficient training, especially when the data is sparse as commonly found in collaborative filtering. The aforementioned results in lower generalization ability and reduced performance. In this paper, we introduce structure learning for autoencoder recommenders by taking advantage of the inherent item groups present in the collaborative filtering domain. Due to the nature of items in general, we know that certain items are more related to each other than to other items. Based on this, we propose a method that first learns groups of related items and then uses this information to determine the connectivity structure of an auto-encoding neural network. This results in a network that is sparsely connected. This sparse structure can be viewed as a prior that guides the network training. Empirically we demonstrate that the proposed structure learning enables the autoencoder to converge to a local optimum with a much smaller spectral norm and generalization error bound than the fully-connected network. The resultant sparse network considerably outperforms the state-of-the-art methods like \textsc{Mult-vae/Mult-dae} on multiple benchmarked datasets even when the same number of parameters and flops are used. It also has a better cold-start performance.
Cleaned Similarity for Better Memory-Based Recommenders
May 17, 2019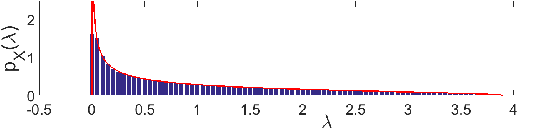
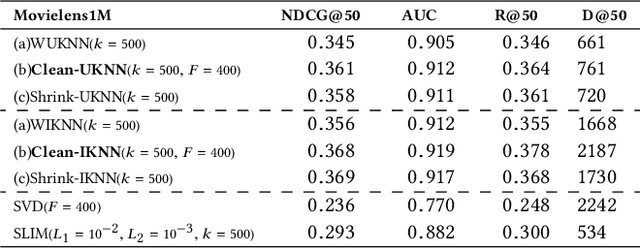
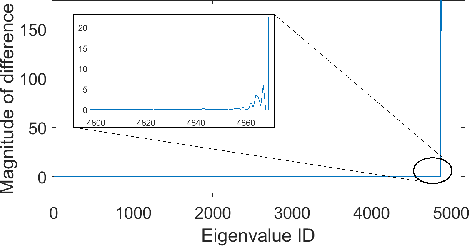

Memory-based collaborative filtering methods like user or item k-nearest neighbors (kNN) are a simple yet effective solution to the recommendation problem. The backbone of these methods is the estimation of the empirical similarity between users/items. In this paper, we analyze the spectral properties of the Pearson and the cosine similarity estimators, and we use tools from random matrix theory to argue that they suffer from noise and eigenvalues spreading. We argue that, unlike the Pearson correlation, the cosine similarity naturally possesses the desirable property of eigenvalue shrinkage for large eigenvalues. However, due to its zero-mean assumption, it overestimates the largest eigenvalues. We quantify this overestimation and present a simple re-scaling and noise cleaning scheme. This results in better performance of the memory-based methods compared to their vanilla counterparts.
Using Taste Groups for Collaborative Filtering
Aug 28, 2018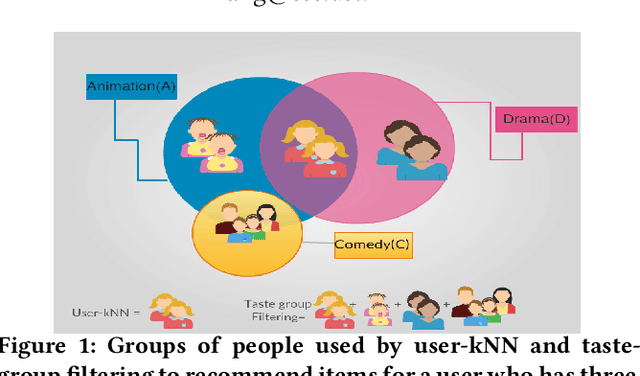
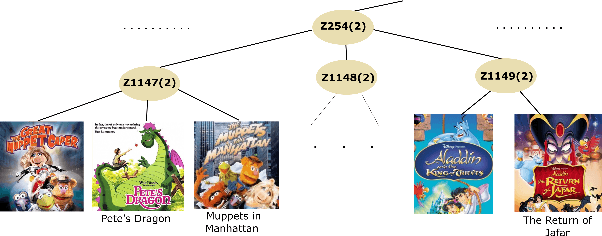
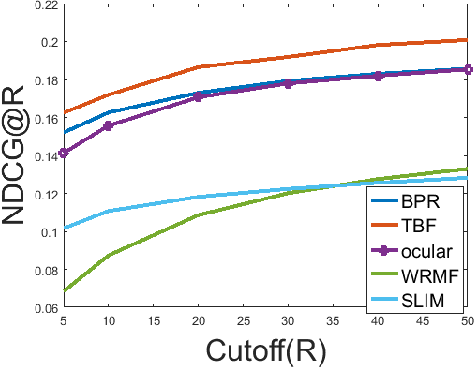
Implicit feedback is the simplest form of user feedback that can be used for item recommendation. It is easy to collect and domain independent. However, there is a lack of negative examples. Existing works circumvent this problem by making various assumptions regarding the unconsumed items, which fail to hold when the user did not consume an item because she was unaware of it. In this paper, we propose as a novel method for addressing the lack of negative examples in implicit feedback. The motivation is that if there is a large group of users who share the same taste and none of them consumed an item, then it is highly likely that the item is irrelevant to this taste. We use Hierarchical Latent Tree Analysis(HLTA) to identify taste-based user groups and make recommendations for a user based on her memberships in the groups.
Matrix Factorization Equals Efficient Co-occurrence Representation
Aug 28, 2018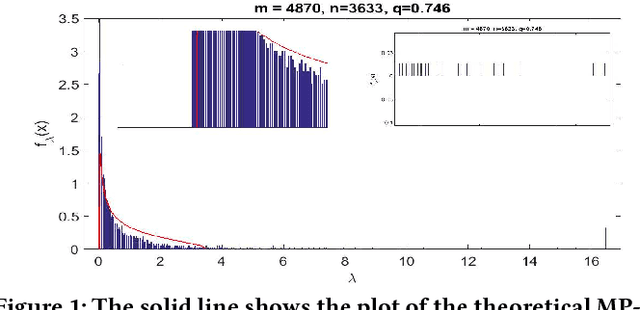


Matrix factorization is a simple and effective solution to the recommendation problem. It has been extensively employed in the industry and has attracted much attention from the academia. However, it is unclear what the low-dimensional matrices represent. We show that matrix factorization can actually be seen as simultaneously calculating the eigenvectors of the user-user and item-item sample co-occurrence matrices. We then use insights from random matrix theory (RMT) to show that picking the top eigenvectors corresponds to removing sampling noise from user/item co-occurrence matrices. Therefore, the low-dimension matrices represent a reduced noise user and item co-occurrence space. We also analyze the structure of the top eigenvector and show that it corresponds to global effects and removing it results in less popular items being recommended. This increases the diversity of the items recommended without affecting the accuracy.
Learning Hierarchical Item Categories from Implicit Feedback Data for Efficient Recommendations and Browsing
Jun 06, 2018
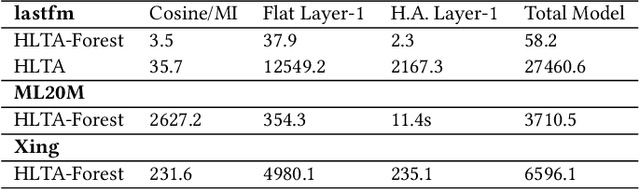
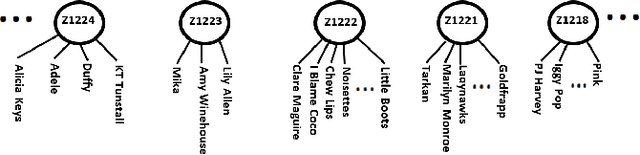
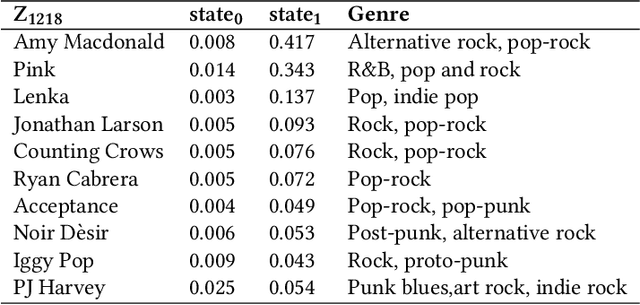
Searching, browsing, and recommendations are common ways in which the "choice overload" faced by users in the online marketplace can be mitigated. In this paper we propose the use of hierarchical item categories, obtained from implicit feedback data, to enable efficient browsing and recommendations. We present a method of creating hierarchical item categories from implicit feedback data only i.e., without any other information on the items like name, genre etc. Categories created in this fashion are based on users' co-consumption of items. Thus, they can be more useful for users in finding interesting and relevant items while they are browsing through the hierarchy. We also show that this item hierarchy can be useful in making category based recommendations, which makes the recommendations more explainable and increases the diversity of the recommendations without compromising much on the accuracy. Item hierarchy can also be useful in the creation of an automatic item taxonomy skeleton by bypassing manual labeling and annotation. This can especially be useful for small vendors. Our data-driven hierarchical categories are based on hierarchical latent tree analysis (HLTA) which has been previously used for text analysis. We present a scaled up learning algorithm \emph{HLTA-Forest} so that HLTA can be applied to implicit feedback data.
Conformative Filtering for Implicit Feedback Data
Apr 06, 2017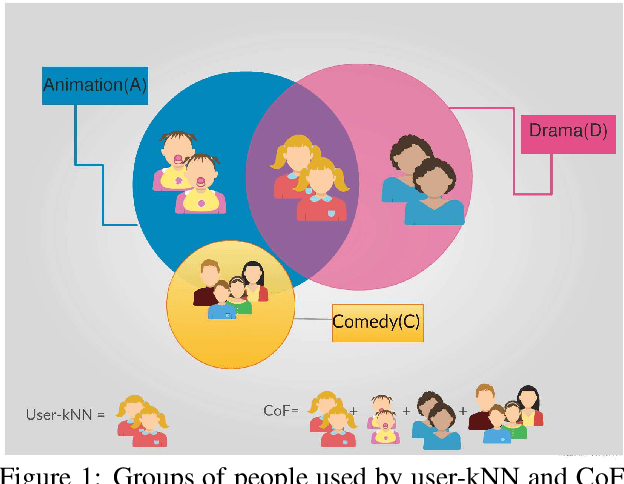
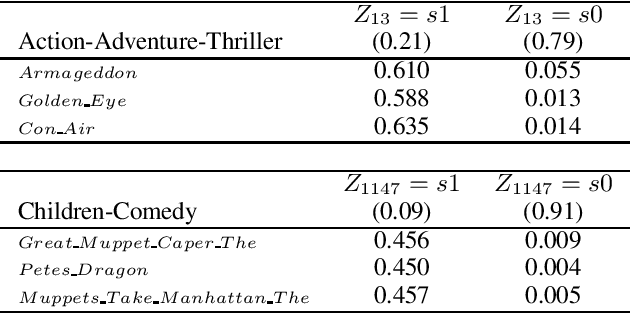
Implicit feedback is the simplest form of user feedback that can be used for item recommendation. It is easy to collect and domain independent. However, there is a lack of negative examples. Existing works circumvent this problem by making various assumptions regarding the unconsumed items, which fail to hold when the user did not consume an item because she was unaware of it. In this paper we propose Conformative Filtering (CoF) as a novel method for addressing the lack of negative examples in implicit feedback. The motivation is that if there is a large group of users who share the same taste and none of them consumed an item, then it is highly likely that the item is irrelevant to this taste. We use Hierarchical Latent Tree Analysis (HLTA) to identify taste-based user groups, and make recommendations for a user based on her memberships in the groups. Experiments on real-world datasets from different domains show that CoF has superior performance compared to other baselines and more than 10% improvement in Recall@5 and Recall@10 is observed.
Latent Tree Models for Hierarchical Topic Detection
Dec 21, 2016
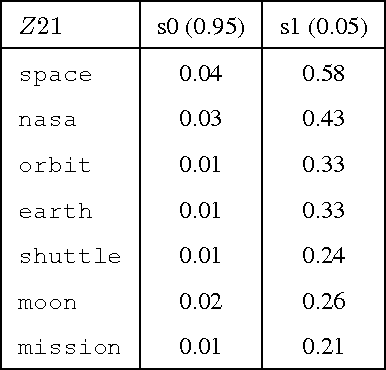
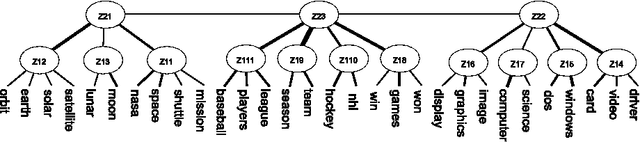

We present a novel method for hierarchical topic detection where topics are obtained by clustering documents in multiple ways. Specifically, we model document collections using a class of graphical models called hierarchical latent tree models (HLTMs). The variables at the bottom level of an HLTM are observed binary variables that represent the presence/absence of words in a document. The variables at other levels are binary latent variables, with those at the lowest latent level representing word co-occurrence patterns and those at higher levels representing co-occurrence of patterns at the level below. Each latent variable gives a soft partition of the documents, and document clusters in the partitions are interpreted as topics. Latent variables at high levels of the hierarchy capture long-range word co-occurrence patterns and hence give thematically more general topics, while those at low levels of the hierarchy capture short-range word co-occurrence patterns and give thematically more specific topics. Unlike LDA-based topic models, HLTMs do not refer to a document generation process and use word variables instead of token variables. They use a tree structure to model the relationships between topics and words, which is conducive to the discovery of meaningful topics and topic hierarchies.