 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting and Explaining Mobile UI Tappability with Vision Modeling and Saliency Analysis
Apr 05, 2022
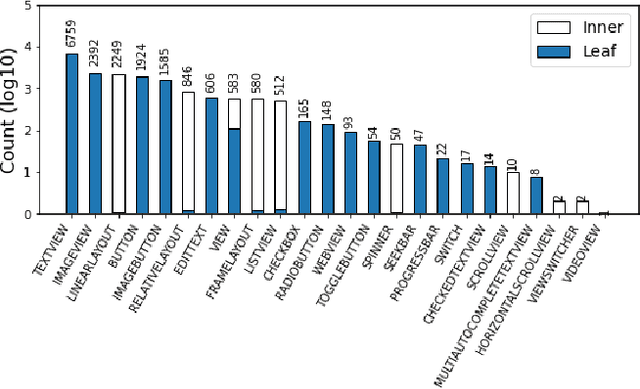
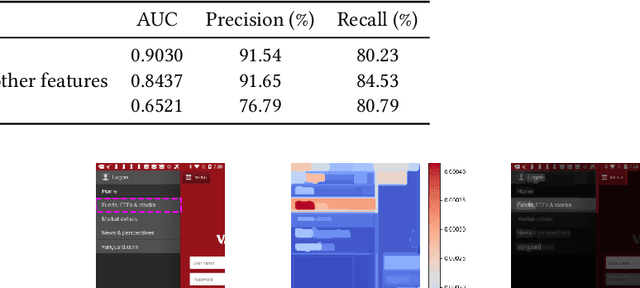
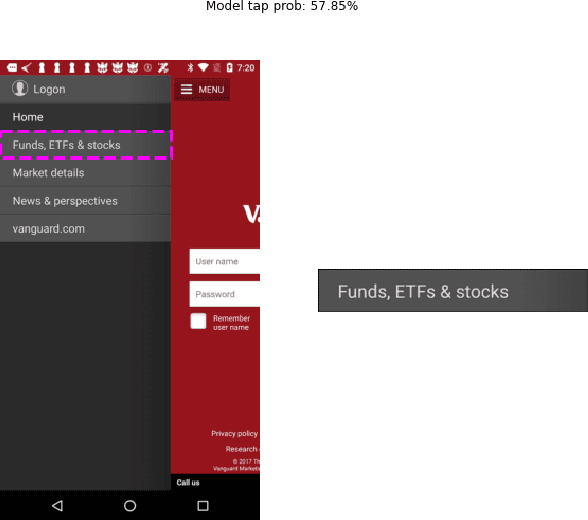
We use a deep learning based approach to predict whether a selected element in a mobile UI screenshot will be perceived by users as tappable, based on pixels only instead of view hierarchies required by previous work. To help designers better understand model predictions and to provide more actionable design feedback than predictions alone, we additionally use ML interpretability techniques to help explain the output of our model. We use XRAI to highlight areas in the input screenshot that most strongly influence the tappability prediction for the selected region, and use k-Nearest Neighbors to present the most similar mobile UIs from the dataset with opposing influences on tappability perception.
Screen2Words: Automatic Mobile UI Summarization with Multimodal Learning
Aug 07, 2021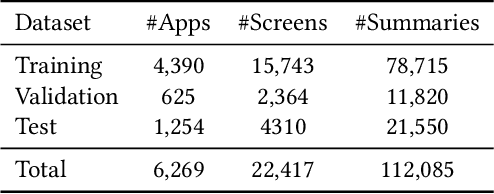

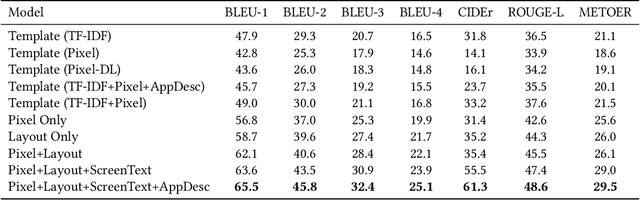
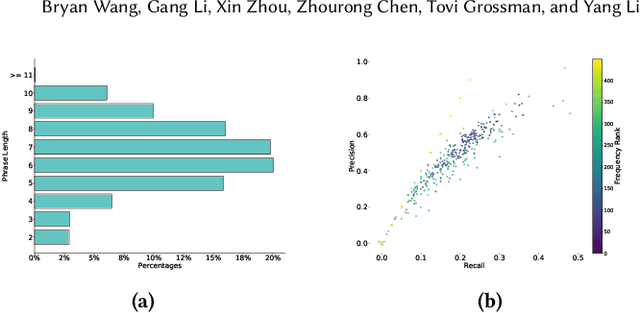
Mobile User Interface Summarization generates succinct language descriptions of mobile screens for conveying important contents and functionalities of the screen, which can be useful for many language-based application scenarios. We present Screen2Words, a novel screen summarization approach that automatically encapsulates essential information of a UI screen into a coherent language phrase. Summarizing mobile screens requires a holistic understanding of the multi-modal data of mobile UIs, including text, image, structures as well as UI semantics, motivating our multi-modal learning approach. We collected and analyzed a large-scale screen summarization dataset annotated by human workers. Our dataset contains more than 112k language summarization across $\sim$22k unique UI screens. We then experimented with a set of deep models with different configurations. Our evaluation of these models with both automatic accuracy metrics and human rating shows that our approach can generate high-quality summaries for mobile screens. We demonstrate potential use cases of Screen2Words and open-source our dataset and model to lay the foundations for further bridging language and user interfaces.
GaterNet: Dynamic Filter Selection in Convolutional Neural Network via a Dedicated Global Gating Network
Nov 27, 2018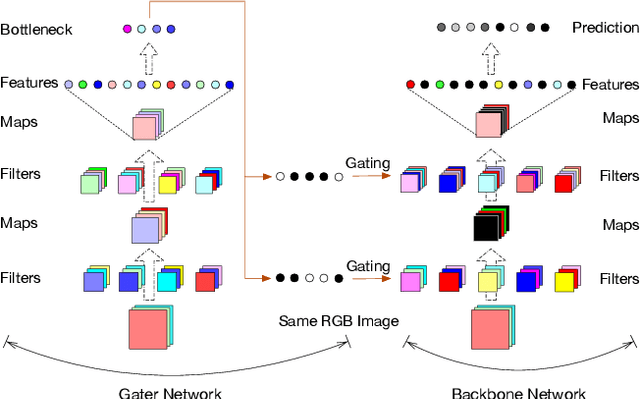
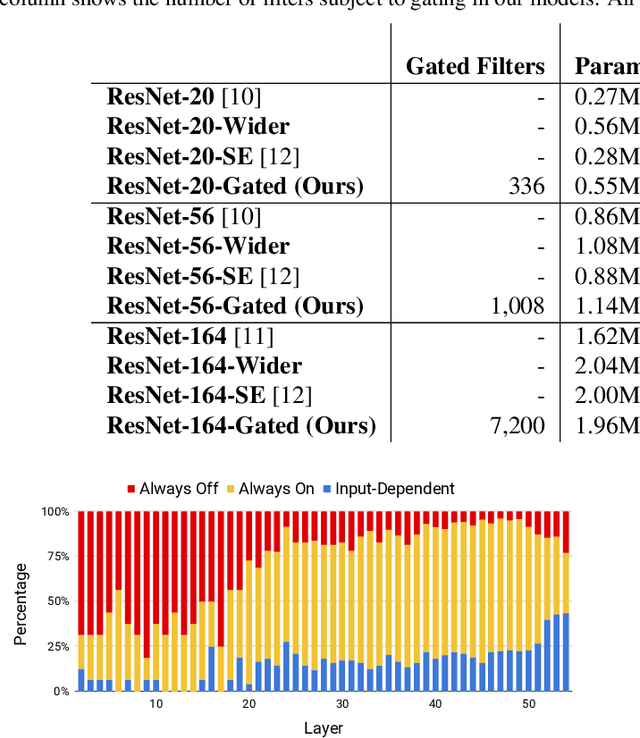
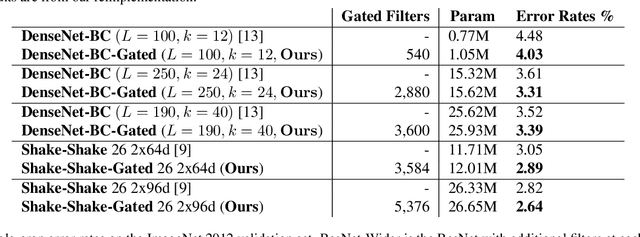

The concept of conditional computation for deep nets has been proposed previously to improve model performance by selectively using only parts of the model conditioned on the sample it is processing. In this paper, we investigate input-dependent dynamic filter selection in deep convolutional neural networks (CNNs). The problem is interesting because the idea of forcing different parts of the model to learn from different types of samples may help us acquire better filters in CNNs, improve the model generalization performance and potentially increase the interpretability of model behavior. We propose a novel yet simple framework called GaterNet, which involves a backbone and a gater network. The backbone network is a regular CNN that performs the major computation needed for making a prediction, while a global gater network is introduced to generate binary gates for selectively activating filters in the backbone network based on each input. Extensive experiments on CIFAR and ImageNet datasets show that our models consistently outperform the original models with a large margin. On CIFAR-10, our model also improves upon state-of-the-art results.
Sparse Boltzmann Machines with Structure Learning as Applied to Text Analysis
Aug 05, 2018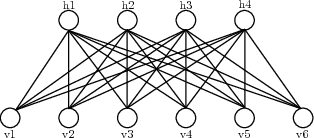
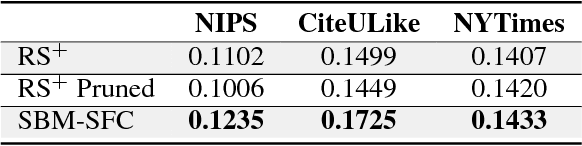
We are interested in exploring the possibility and benefits of structure learning for deep models. As the first step, this paper investigates the matter for Restricted Boltzmann Machines (RBMs). We conduct the study with Replicated Softmax, a variant of RBMs for unsupervised text analysis. We present a method for learning what we call Sparse Boltzmann Machines, where each hidden unit is connected to a subset of the visible units instead of all of them. Empirical results show that the method yields models with significantly improved model fit and interpretability as compared with RBMs where each hidden unit is connected to all visible units.
Building Sparse Deep Feedforward Networks using Tree Receptive Fields
Jul 17, 2018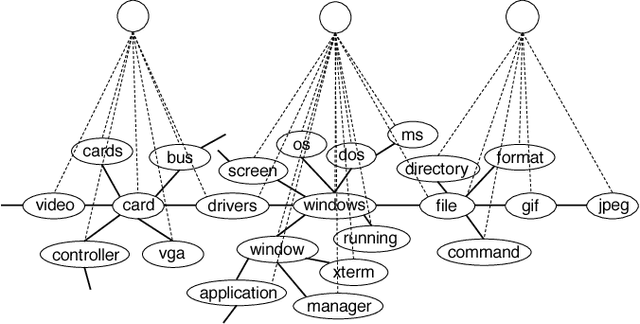

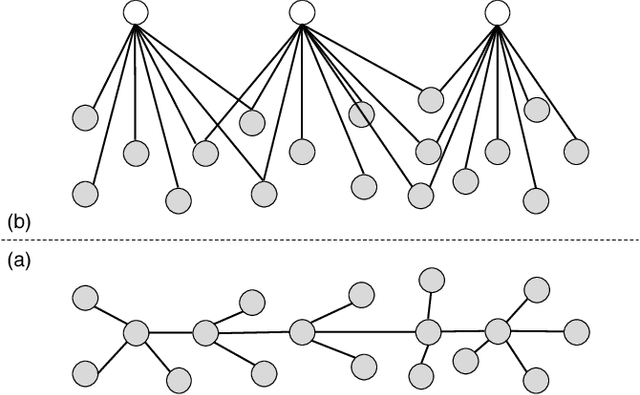
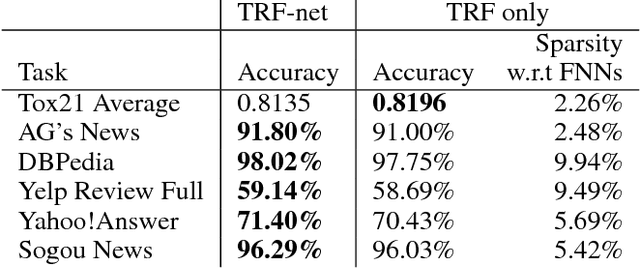
Sparse connectivity is an important factor behind the success of convolutional neural networks and recurrent neural networks. In this paper, we consider the problem of learning sparse connectivity for feedforward neural networks (FNNs). The key idea is that a unit should be connected to a small number of units at the next level below that are strongly correlated. We use Chow-Liu's algorithm to learn a tree-structured probabilistic model for the units at the current level, use the tree to identify subsets of units that are strongly correlated, and introduce a new unit with receptive field over the subsets. The procedure is repeated on the new units to build multiple layers of hidden units. The resulting model is called a TRF-net. Empirical results show that, when compared to dense FNNs, TRF-net achieves better or comparable classification performance with much fewer parameters and sparser structures. They are also more interpretable.
Learning Sparse Deep Feedforward Networks via Tree Skeleton Expansion
Mar 16, 2018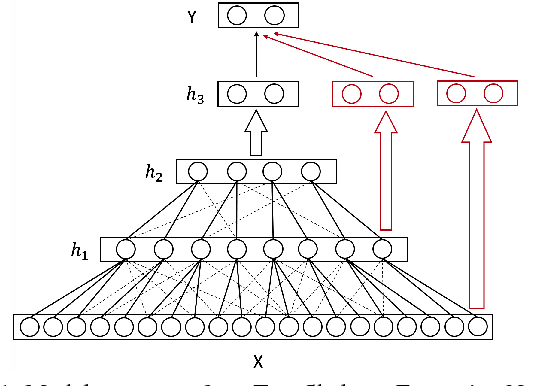

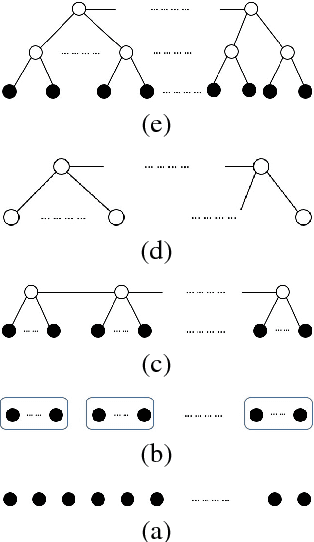
Despite the popularity of deep learning, structure learning for deep models remains a relatively under-explored area. In contrast, structure learning has been studied extensively for probabilistic graphical models (PGMs). In particular, an efficient algorithm has been developed for learning a class of tree-structured PGMs called hierarchical latent tree models (HLTMs), where there is a layer of observed variables at the bottom and multiple layers of latent variables on top. In this paper, we propose a simple method for learning the structures of feedforward neural networks (FNNs) based on HLTMs. The idea is to expand the connections in the tree skeletons from HLTMs and to use the resulting structures for FNNs. An important characteristic of FNN structures learned this way is that they are sparse. We present extensive empirical results to show that, compared with standard FNNs tuned-manually, sparse FNNs learned by our method achieve better or comparable classification performance with much fewer parameters. They are also more interpretable.
Latent Tree Variational Autoencoder for Joint Representation Learning and Multidimensional Clustering
Mar 14, 2018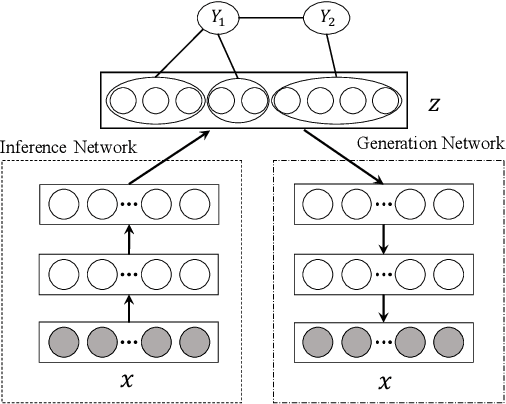

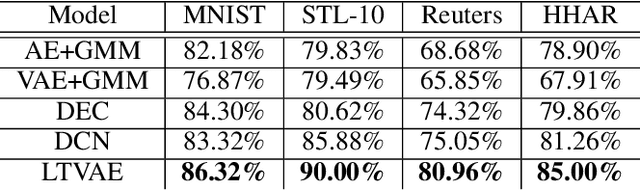
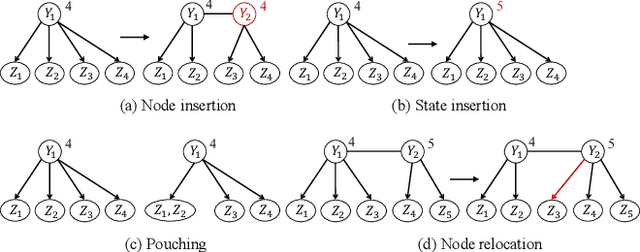
Recently, deep learning based clustering methods are shown superior to traditional ones by jointly conducting representation learning and clustering. These methods rely on the assumptions that the number of clusters is known, and that there is one single partition over the data and all attributes define that partition. However, in real-world applications, prior knowledge of the number of clusters is usually unavailable and there are multiple ways to partition the data based on subsets of attributes. To resolve the issues, we propose latent tree variational autoencoder (LTVAE), which simultaneously performs representation learning and multidimensional clustering. LTVAE learns latent embeddings from data, discovers multi-facet clustering structures based on subsets of latent features, and automatically determines the number of clusters in each facet. Experiments show that the proposed method achieves state-of-the-art clustering performance and reals reasonable multifacet structures of the data.
Document Generation with Hierarchical Latent Tree Models
Dec 13, 2017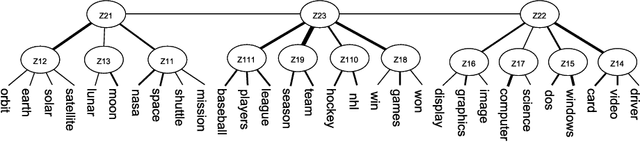

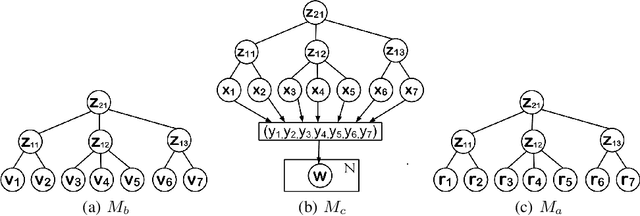
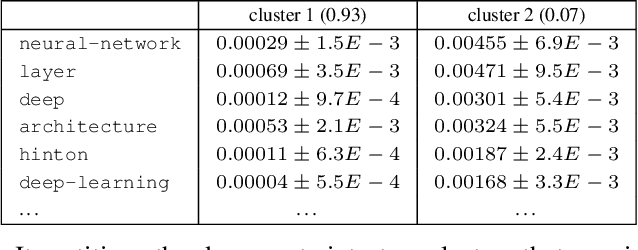
In most probabilistic topic models, a document is viewed as a collection of tokens and each token is a variable whose values are all the words in a vocabulary. One exception is hierarchical latent tree models (HLTMs), where a document is viewed as a binary vector over the vocabulary and each word is regarded as a binary variable. The use of word variables allows the detection and representation of patterns of word co-occurrences and co-occurrences of those patterns qualitatively using multiple levels of latent variables, and naturally leads to a method for hierarchical topic detection. In this paper, we assume that an HLTM has been learned from binary data and we extend it to take word frequencies into consideration. The idea is to replace each binary word variable with a real-valued variable that represents the relative frequency of the word in a document. A document generation process is proposed and an algorithm is given for estimating the model parameters by inverting the generation process. Empirical results show that our method significantly outperforms the commonly-used LDA-based methods for hierarchical topic detection, in terms of model quality and meaningfulness of topics and topic hierarchies.
Latent Tree Models for Hierarchical Topic Detection
Dec 21, 2016
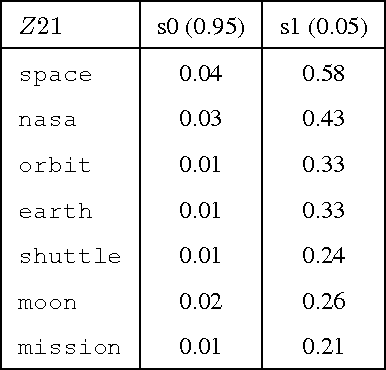
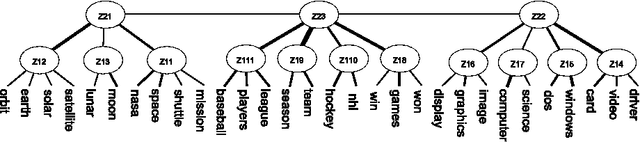

We present a novel method for hierarchical topic detection where topics are obtained by clustering documents in multiple ways. Specifically, we model document collections using a class of graphical models called hierarchical latent tree models (HLTMs). The variables at the bottom level of an HLTM are observed binary variables that represent the presence/absence of words in a document. The variables at other levels are binary latent variables, with those at the lowest latent level representing word co-occurrence patterns and those at higher levels representing co-occurrence of patterns at the level below. Each latent variable gives a soft partition of the documents, and document clusters in the partitions are interpreted as topics. Latent variables at high levels of the hierarchy capture long-range word co-occurrence patterns and hence give thematically more general topics, while those at low levels of the hierarchy capture short-range word co-occurrence patterns and give thematically more specific topics. Unlike LDA-based topic models, HLTMs do not refer to a document generation process and use word variables instead of token variables. They use a tree structure to model the relationships between topics and words, which is conducive to the discovery of meaningful topics and topic hierarchies.
Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
Sep 19, 2015

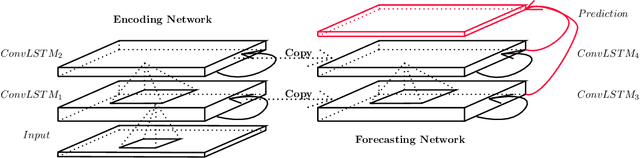
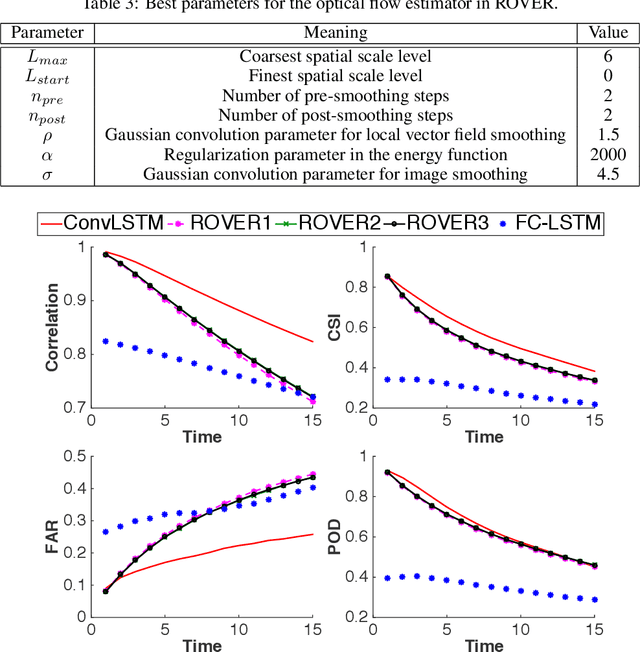
The goal of precipitation nowcasting is to predict the future rainfall intensity in a local region over a relatively short period of time. Very few previous studies have examined this crucial and challenging weather forecasting problem from the machine learning perspective. In this paper, we formulate precipitation nowcasting as a spatiotemporal sequence forecasting problem in which both the input and the prediction target are spatiotemporal sequences. By extending the fully connected LSTM (FC-LSTM) to have convolutional structures in both the input-to-state and state-to-state transitions, we propose the convolutional LSTM (ConvLSTM) and use it to build an end-to-end trainable model for the precipitation nowcasting problem. Experiments show that our ConvLSTM network captures spatiotemporal correlations better and consistently outperforms FC-LSTM and the state-of-the-art operational ROVER algorithm for precipitation nowcasting.