 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSeg: An Iterative Refinement-based Framework for Training-free Segmentation
Paper and Code

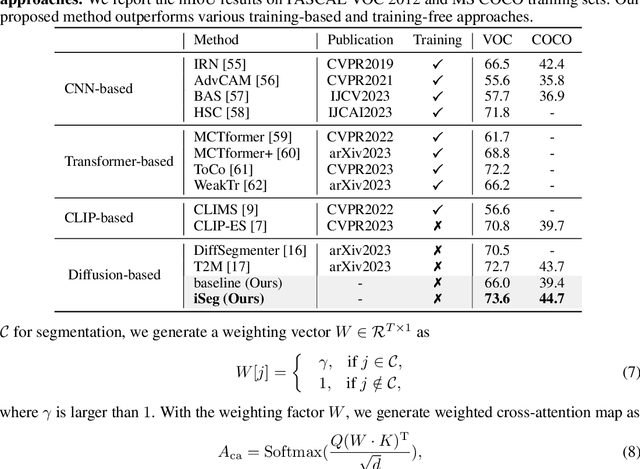
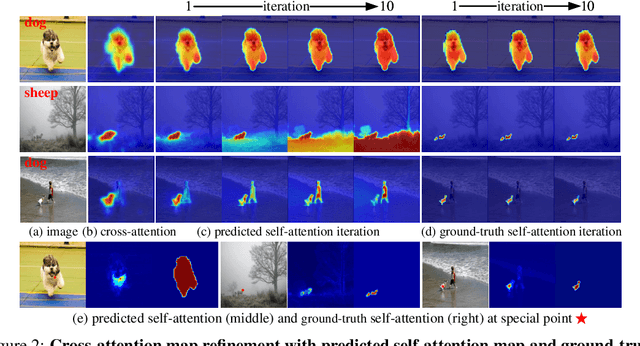
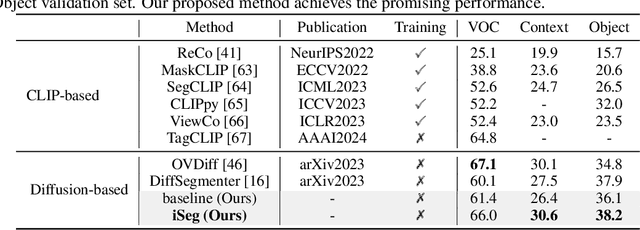
Stable diffusion has demonstrated strong image synthesis ability to given text descriptions, suggesting it to contain strong semantic clue for grouping objects. Inspired by this, researchers have explored employing stable diffusion for trainingfree segmentation. Most existing approaches either simply employ cross-attention map or refine it by self-attention map, to generate segmentation masks. We believe that iterative refinement with self-attention map would lead to better results. However, we mpirically demonstrate that such a refinement is sub-optimal likely due to the self-attention map containing irrelevant global information which hampers accurately refining cross-attention map with multiple iterations. To address this, we propose an iterative refinement framework for training-free segmentation, named iSeg, having an entropy-reduced self-attention module which utilizes a gradient descent scheme to reduce the entropy of self-attention map, thereby suppressing the weak responses corresponding to irrelevant global information. Leveraging the entropy-reduced self-attention module, our iSeg stably improves refined crossattention map with iterative refinement. Further, we design a category-enhanced cross-attention module to generate accurate cross-attention map, providing a better initial input for iterative refinement. Extensive experiments across different datasets and diverse segmentation tasks reveal the merits of proposed contributions, leading to promising performance on diverse segmentation tasks. For unsupervised semantic segmentation on Cityscapes, our iSeg achieves an absolute gain of 3.8% in terms of mIoU compared to the best existing training-free approach in literature. Moreover, our proposed iSeg can support segmentation with different kind of images and interactions.