 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSakuga-42M Dataset: Scaling Up Cartoon Research
Paper and Code
May 13, 2024

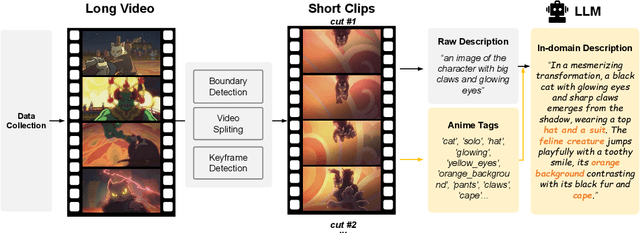
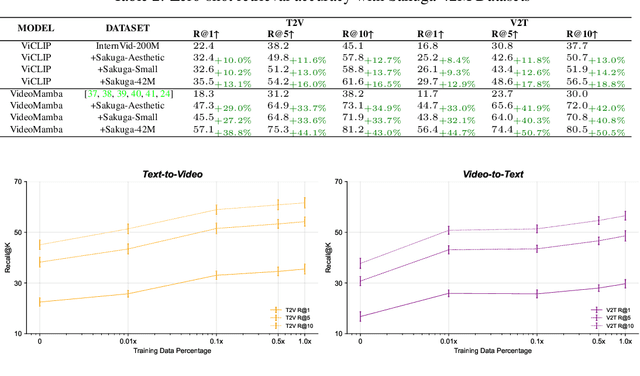
Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.