 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers
May 06, 2025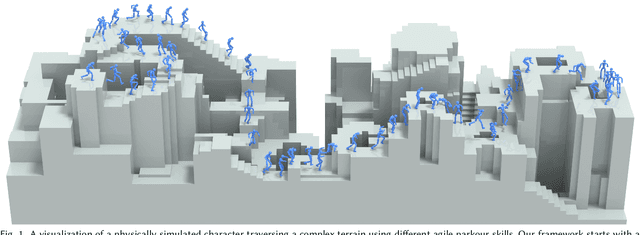
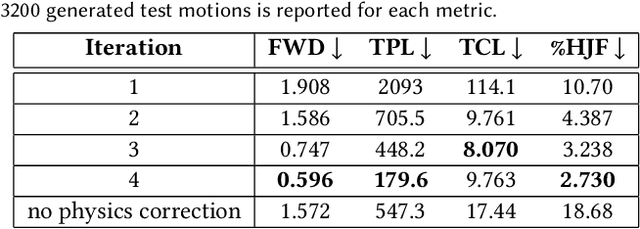

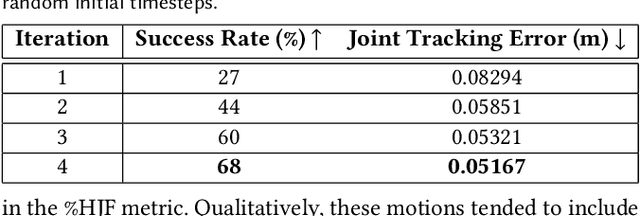
Humans excel in navigating diverse, complex environments with agile motor skills, exemplified by parkour practitioners performing dynamic maneuvers, such as climbing up walls and jumping across gaps. Reproducing these agile movements with simulated characters remains challenging, in part due to the scarcity of motion capture data for agile terrain traversal behaviors and the high cost of acquiring such data. In this work, we introduce PARC (Physics-based Augmentation with Reinforcement Learning for Character Controllers), a framework that leverages machine learning and physics-based simulation to iteratively augment motion datasets and expand the capabilities of terrain traversal controllers. PARC begins by training a motion generator on a small dataset consisting of core terrain traversal skills. The motion generator is then used to produce synthetic data for traversing new terrains. However, these generated motions often exhibit artifacts, such as incorrect contacts or discontinuities. To correct these artifacts, we train a physics-based tracking controller to imitate the motions in simulation. The corrected motions are then added to the dataset, which is used to continue training the motion generator in the next iteration. PARC's iterative process jointly expands the capabilities of the motion generator and tracker, creating agile and versatile models for interacting with complex environments. PARC provides an effective approach to develop controllers for agile terrain traversal, which bridges the gap between the scarcity of motion data and the need for versatile character controllers.
Learning to Use Chopsticks in Diverse Styles
May 28, 2022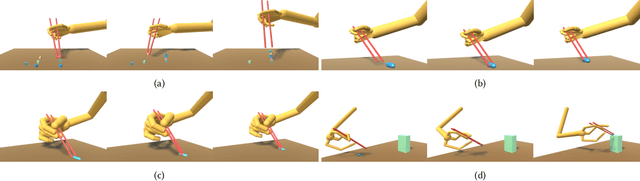

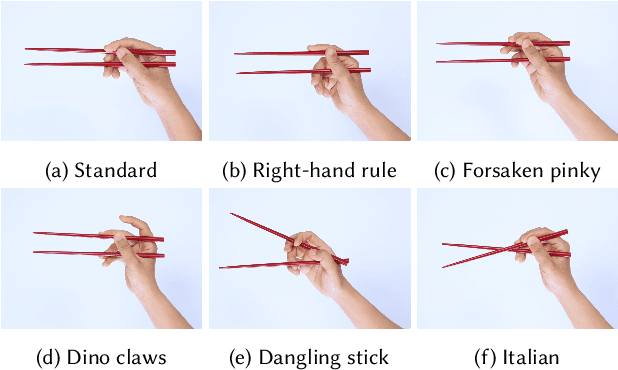

Learning dexterous manipulation skills is a long-standing challenge in computer graphics and robotics, especially when the task involves complex and delicate interactions between the hands, tools and objects. In this paper, we focus on chopsticks-based object relocation tasks, which are common yet demanding. The key to successful chopsticks skills is steady gripping of the sticks that also supports delicate maneuvers. We automatically discover physically valid chopsticks holding poses by Bayesian Optimization (BO) and Deep Reinforcement Learning (DRL), which works for multiple gripping styles and hand morphologies without the need of example data. Given as input the discovered gripping poses and desired objects to be moved, we build physics-based hand controllers to accomplish relocation tasks in two stages. First, kinematic trajectories are synthesized for the chopsticks and hand in a motion planning stage. The key components of our motion planner include a grasping model to select suitable chopsticks configurations for grasping the object, and a trajectory optimization module to generate collision-free chopsticks trajectories. Then we train physics-based hand controllers through DRL again to track the desired kinematic trajectories produced by the motion planner. We demonstrate the capabilities of our framework by relocating objects of various shapes and sizes, in diverse gripping styles and holding positions for multiple hand morphologies. Our system achieves faster learning speed and better control robustness, when compared to vanilla systems that attempt to learn chopstick-based skills without a gripping pose optimization module and/or without a kinematic motion planner.
Robust Visual Teach and Repeat for UGVs Using 3D Semantic Maps
Sep 21, 2021
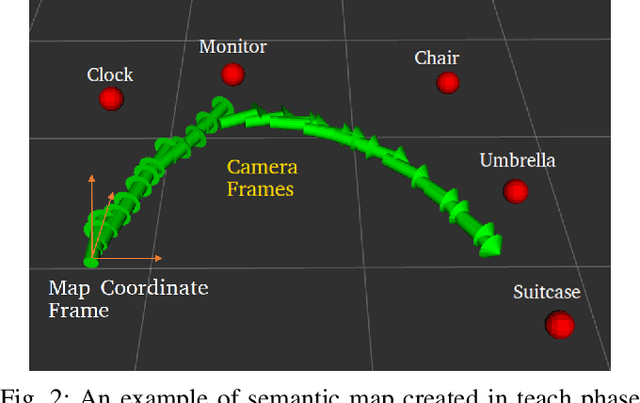

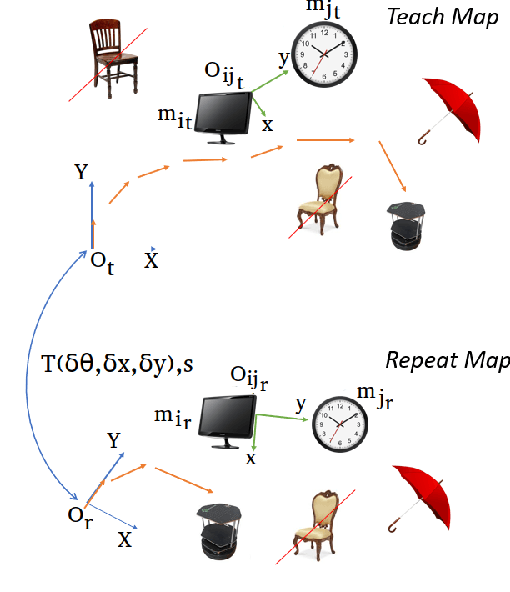
In this paper, we propose a Visual Teach and Repeat (VTR) algorithm using semantic landmarks extracted from environmental objects for ground robots with fixed mount monocular cameras. The proposed algorithm is robust to changes in the starting pose of the camera/robot, where a pose is defined as the planar position plus the orientation around the vertical axis. VTR consists of a teach phase in which a robot moves in a prescribed path, and a repeat phase in which the robot tries to repeat the same path starting from the same or a different pose. Most available VTR algorithms are pose dependent and cannot perform well in the repeat phase when starting from an initial pose far from that of the teach phase. To achieve more robust pose independency, during the teach phase, we collect the camera poses and the 3D point clouds of the environment using ORB-SLAM. We also detect objects in the environment using YOLOv3. We then combine the two outputs to build a 3D semantic map of the environment consisting of the 3D position of the objects and the robot path. In the repeat phase, we relocalize the robot based on the detected objects and the stored semantic map. The robot is then able to move toward the teach path, and repeat it in both forward and backward directions. The results show that our algorithm is highly robust with respect to pose variations as well as environmental alterations. Our code and data are available at the following Github page: https://github.com/mmahdavian/semantic_visual_teach_repeat
Discovering Diverse Athletic Jumping Strategies
May 02, 2021
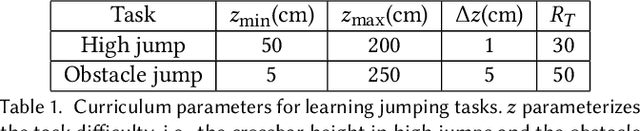
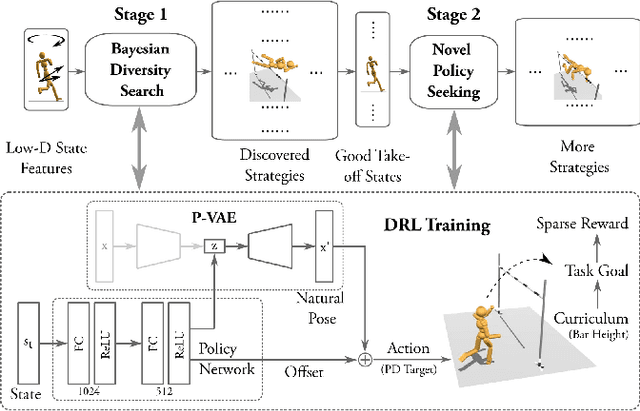
We present a framework that enables the discovery of diverse and natural-looking motion strategies for athletic skills such as the high jump. The strategies are realized as control policies for physics-based characters. Given a task objective and an initial character configuration, the combination of physics simulation and deep reinforcement learning (DRL) provides a suitable starting point for automatic control policy training. To facilitate the learning of realistic human motions, we propose a Pose Variational Autoencoder (P-VAE) to constrain the actions to a subspace of natural poses. In contrast to motion imitation methods, a rich variety of novel strategies can naturally emerge by exploring initial character states through a sample-efficient Bayesian diversity search (BDS) algorithm. A second stage of optimization that encourages novel policies can further enrich the unique strategies discovered. Our method allows for the discovery of diverse and novel strategies for athletic jumping motions such as high jumps and obstacle jumps with no motion examples and less reward engineering than prior work.
* 17 pages; SIGGRAPH 2021
Hierarchical Action Classification with Network Pruning
Jul 30, 2020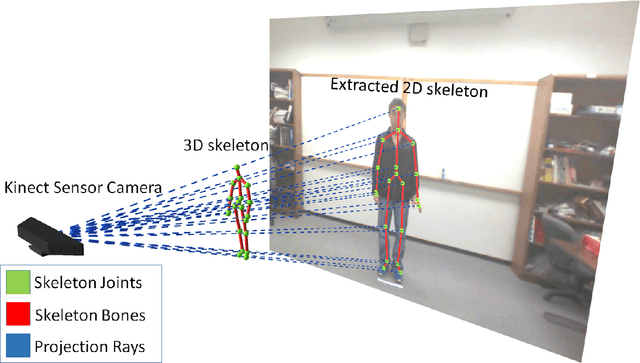
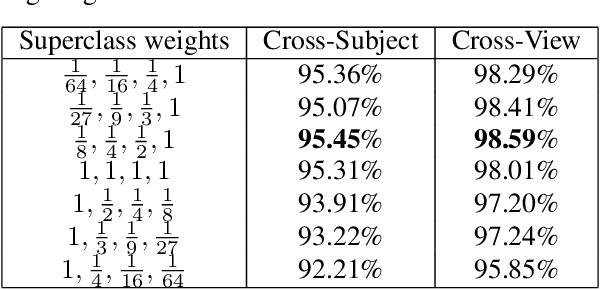
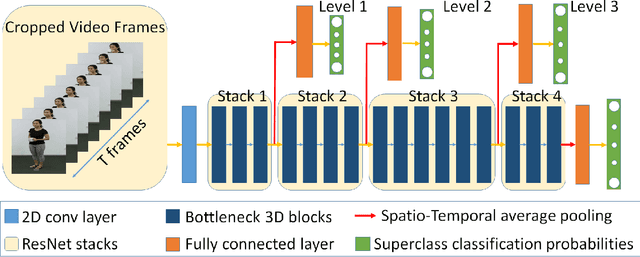

Research on human action classification has made significant progresses in the past few years. Most deep learning methods focus on improving performance by adding more network components. We propose, however, to better utilize auxiliary mechanisms, including hierarchical classification, network pruning, and skeleton-based preprocessing, to boost the model robustness and performance. We test the effectiveness of our method on four commonly used testing datasets: NTU RGB+D 60, NTU RGB+D 120, Northwestern-UCLA Multiview Action 3D, and UTD Multimodal Human Action Dataset. Our experiments show that our method can achieve either comparable or better performance on all four datasets. In particular, our method sets up a new baseline for NTU 120, the largest dataset among the four. We also analyze our method with extensive comparisons and ablation studies.