 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Visual Teach and Repeat for UGVs Using 3D Semantic Maps
Paper and Code

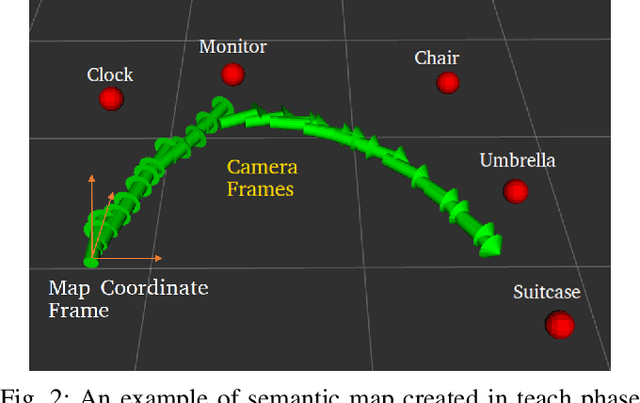

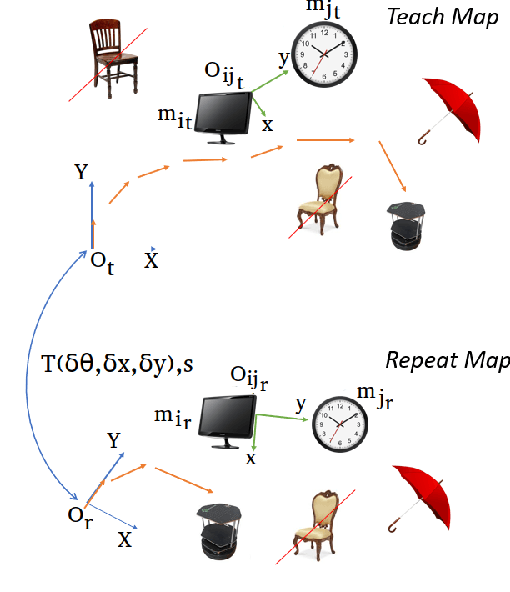
In this paper, we propose a Visual Teach and Repeat (VTR) algorithm using semantic landmarks extracted from environmental objects for ground robots with fixed mount monocular cameras. The proposed algorithm is robust to changes in the starting pose of the camera/robot, where a pose is defined as the planar position plus the orientation around the vertical axis. VTR consists of a teach phase in which a robot moves in a prescribed path, and a repeat phase in which the robot tries to repeat the same path starting from the same or a different pose. Most available VTR algorithms are pose dependent and cannot perform well in the repeat phase when starting from an initial pose far from that of the teach phase. To achieve more robust pose independency, during the teach phase, we collect the camera poses and the 3D point clouds of the environment using ORB-SLAM. We also detect objects in the environment using YOLOv3. We then combine the two outputs to build a 3D semantic map of the environment consisting of the 3D position of the objects and the robot path. In the repeat phase, we relocalize the robot based on the detected objects and the stored semantic map. The robot is then able to move toward the teach path, and repeat it in both forward and backward directions. The results show that our algorithm is highly robust with respect to pose variations as well as environmental alterations. Our code and data are available at the following Github page: https://github.com/mmahdavian/semantic_visual_teach_repeat