 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Diverse Athletic Jumping Strategies
May 02, 2021
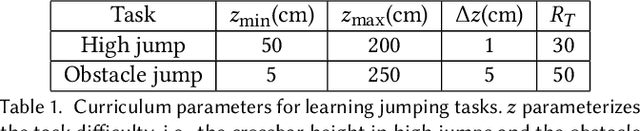
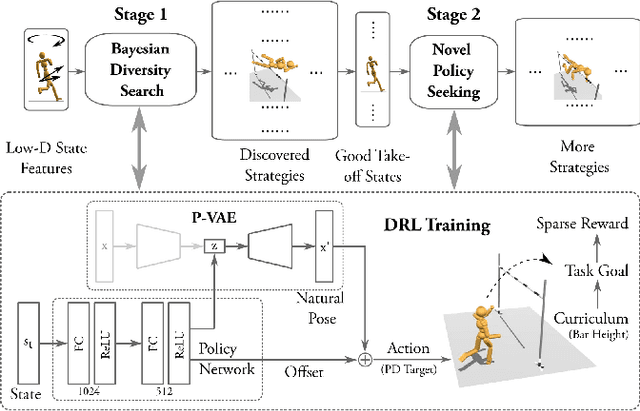
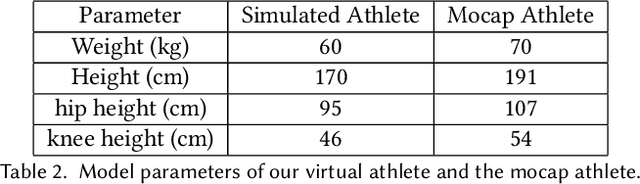
We present a framework that enables the discovery of diverse and natural-looking motion strategies for athletic skills such as the high jump. The strategies are realized as control policies for physics-based characters. Given a task objective and an initial character configuration, the combination of physics simulation and deep reinforcement learning (DRL) provides a suitable starting point for automatic control policy training. To facilitate the learning of realistic human motions, we propose a Pose Variational Autoencoder (P-VAE) to constrain the actions to a subspace of natural poses. In contrast to motion imitation methods, a rich variety of novel strategies can naturally emerge by exploring initial character states through a sample-efficient Bayesian diversity search (BDS) algorithm. A second stage of optimization that encourages novel policies can further enrich the unique strategies discovered. Our method allows for the discovery of diverse and novel strategies for athletic jumping motions such as high jumps and obstacle jumps with no motion examples and less reward engineering than prior work.
* 17 pages; SIGGRAPH 2021
Efficient Hyperparameter Optimization for Physics-based Character Animation
Apr 26, 2021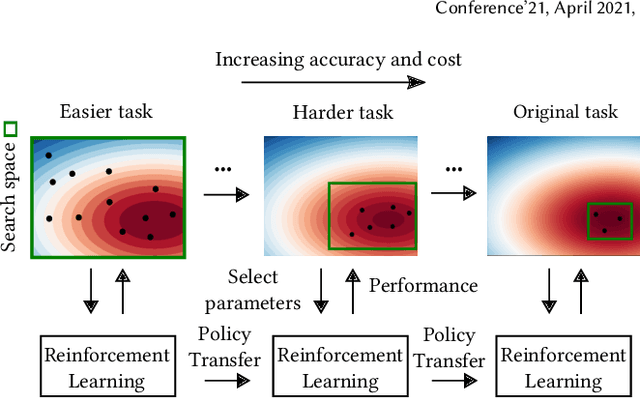


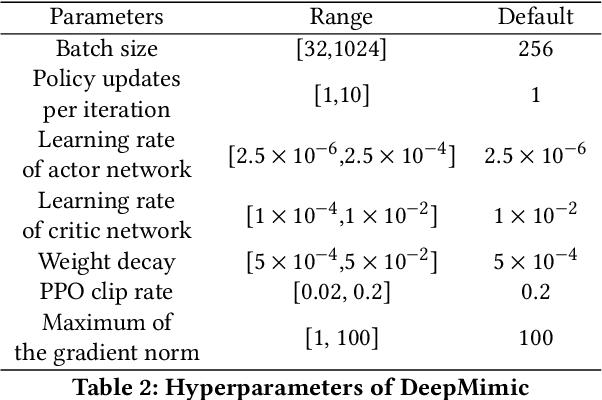
Physics-based character animation has seen significant advances in recent years with the adoption of Deep Reinforcement Learning (DRL). However, DRL-based learning methods are usually computationally expensive and their performance crucially depends on the choice of hyperparameters. Tuning hyperparameters for these methods often requires repetitive training of control policies, which is even more computationally prohibitive. In this work, we propose a novel Curriculum-based Multi-Fidelity Bayesian Optimization framework (CMFBO) for efficient hyperparameter optimization of DRL-based character control systems. Using curriculum-based task difficulty as fidelity criterion, our method improves searching efficiency by gradually pruning search space through evaluation on easier motor skill tasks. We evaluate our method on two physics-based character control tasks: character morphology optimization and hyperparameter tuning of DeepMimic. Our algorithm significantly outperforms state-of-the-art hyperparameter optimization methods applicable for physics-based character animation. In particular, we show that hyperparameters optimized through our algorithm result in at least 5x efficiency gain comparing to author-released settings in DeepMimic.