 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct As a Real Researcher: A Suite of Benchmarks Evaluating Frontier LLMs and Agentic Harnesses in Research Lifecycle
Jun 05, 2026As foundation models advance and agent scaffolding becomes increasingly sophisticated, agents have demonstrated remarkable proficiency in complex, long-horizon coding tasks and even autonomous experiment execution. Despite their evolution from research assistants into autonomous research agents, these systems still exhibit significant limitations in field sensitivity, research ethics, and nuanced scientific judgment. Consequently, frontier agents remain unable to fully replace human researchers. To bridge this gap, we conceptualize the AARR (Act As a Real Researcher) benchmark series. Unlike existing benchmarks that primarily assess macro-level execution capabilities, AARR focuses on whether agents can emulate the professionalism, thoroughness, and nuanced reasoning that characterize human researchers in granular research scenarios. In this work, we propose AARRI-Bench (Act As a Real Research Intern), the first benchmark in this series. We conduct extensive experiments across frontier models and agentic systems, revealing that even the best-performing configuration (Mini-SWE-Agent with Claude Opus 4.7) achieves only 68.3\% success rate, frequently overlooking subtle yet critical details that are obvious to real human researchers. Our results indicate that developing researcher-like AI requires further exploration of research behavior, rather than merely complex scaffolding. Our data is released at https://github.com/AARR-bench/AARRI-bench.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
Multi-Modal Building Change Detection for Large-Scale Small Changes: Benchmark and Baseline
Mar 19, 2026Change detection in optical remote sensing imagery is susceptible to illumination fluctuations, seasonal changes, and variations in surface land-cover materials. Relying solely on RGB imagery often produces pseudo-changes and leads to semantic ambiguity in features. Incorporating near-infrared (NIR) information provides heterogeneous physical cues that are complementary to visible light, thereby enhancing the discriminability of building materials and tiny structures while improving detection accuracy. However, existing multi-modal datasets generally lack high-resolution and accurately registered bi-temporal imagery, and current methods often fail to fully exploit the inherent heterogeneity between these modalities. To address these issues, we introduce the Large-scale Small-change Multi-modal Dataset (LSMD), a bi-temporal RGB-NIR building change detection benchmark dataset targeting small changes in realistic scenarios, providing a rigorous testing platform for evaluating multi-modal change detection methods in complex environments. Based on LSMD, we further propose the Multi-modal Spectral Complementarity Network (MSCNet) to achieve effective cross-modal feature fusion. MSCNet comprises three key components: the Neighborhood Context Enhancement Module (NCEM) to strengthen local spatial details, the Cross-modal Alignment and Interaction Module (CAIM) to enable deep interaction between RGB and NIR features, and the Saliency-aware Multisource Refinement Module (SMRM) to progressively refine fused features. Extensive experiments demonstrate that MSCNet effectively leverages multi-modal information and consistently outperforms existing methods under multiple input configurations, validating its efficacy for fine-grained building change detection. The source code will be made publicly available at: https://github.com/AeroVILab-AHU/LSMD
On Stability and Robustness of Diffusion Posterior Sampling for Bayesian Inverse Problems
Feb 02, 2026Diffusion models have recently emerged as powerful learned priors for Bayesian inverse problems (BIPs). Diffusion-based solvers rely on a presumed likelihood for the observations in BIPs to guide the generation process. However, the link between likelihood and recovery quality for BIPs is unclear in previous works. We bridge this gap by characterizing the posterior approximation error and proving the \emph{stability} of the diffusion-based solvers. Meanwhile, an immediate result of our findings on stability demonstrates the lack of robustness in diffusion-based solvers, which remains unexplored. This can degrade performance when the presumed likelihood mismatches the unknown true data generation processes. To address this issue, we propose a simple yet effective solution, \emph{robust diffusion posterior sampling}, which is provably \emph{robust} and compatible with existing gradient-based posterior samplers. Empirical results on scientific inverse problems and natural image tasks validate the effectiveness and robustness of our method, showing consistent performance improvements under challenging likelihood misspecifications.
Exchange Is All You Need for Remote Sensing Change Detection
Jan 12, 2026Remote sensing change detection fundamentally relies on the effective fusion and discrimination of bi-temporal features. Prevailing paradigms typically utilize Siamese encoders bridged by explicit difference computation modules, such as subtraction or concatenation, to identify changes. In this work, we challenge this complexity with SEED (Siamese Encoder-Exchange-Decoder), a streamlined paradigm that replaces explicit differencing with parameter-free feature exchange. By sharing weights across both Siamese encoders and decoders, SEED effectively operates as a single parameter set model. Theoretically, we formalize feature exchange as an orthogonal permutation operator and prove that, under pixel consistency, this mechanism preserves mutual information and Bayes optimal risk, whereas common arithmetic fusion methods often introduce information loss. Extensive experiments across five benchmarks, including SYSU-CD, LEVIR-CD, PX-CLCD, WaterCD, and CDD, and three backbones, namely SwinT, EfficientNet, and ResNet, demonstrate that SEED matches or surpasses state of the art methods despite its simplicity. Furthermore, we reveal that standard semantic segmentation models can be transformed into competitive change detectors solely by inserting this exchange mechanism, referred to as SEG2CD. The proposed paradigm offers a robust, unified, and interpretable framework for change detection, demonstrating that simple feature exchange is sufficient for high performance information fusion. Code and full training and evaluation protocols will be released at https://github.com/dyzy41/open-rscd.
Improving Few-Shot Change Detection Visual Question Answering via Decision-Ambiguity-guided Reinforcement Fine-Tuning
Dec 31, 2025Change detection visual question answering (CDVQA) requires answering text queries by reasoning about semantic changes in bi-temporal remote sensing images. A straightforward approach is to boost CDVQA performance with generic vision-language models via supervised fine-tuning (SFT). Despite recent progress, we observe that a significant portion of failures do not stem from clearly incorrect predictions, but from decision ambiguity, where the model assigns similar confidence to the correct answer and strong distractors. To formalize this challenge, we define Decision-Ambiguous Samples (DAS) as instances with a small probability margin between the ground-truth answer and the most competitive alternative. We argue that explicitly optimizing DAS is crucial for improving the discriminability and robustness of CDVQA models. To this end, we propose DARFT, a Decision-Ambiguity-guided Reinforcement Fine-Tuning framework that first mines DAS using an SFT-trained reference policy and then applies group-relative policy optimization on the mined subset. By leveraging multi-sample decoding and intra-group relative advantages, DARFT suppresses strong distractors and sharpens decision boundaries without additional supervision. Extensive experiments demonstrate consistent gains over SFT baselines, particularly under few-shot settings.
SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images
Dec 23, 2025Effectively grounding complex language to pixels in remote sensing (RS) images is a critical challenge for applications like disaster response and environmental monitoring. Current models can parse simple, single-target commands but fail when presented with complex geospatial scenarios, e.g., segmenting objects at various granularities, executing multi-target instructions, and interpreting implicit user intent. To drive progress against these failures, we present LaSeRS, the first large-scale dataset built for comprehensive training and evaluation across four critical dimensions of language-guided segmentation: hierarchical granularity, target multiplicity, reasoning requirements, and linguistic variability. By capturing these dimensions, LaSeRS moves beyond simple commands, providing a benchmark for complex geospatial reasoning. This addresses a critical gap: existing datasets oversimplify, leading to sensitivity-prone real-world models. We also propose SegEarth-R2, an MLLM architecture designed for comprehensive language-guided segmentation in RS, which directly confronts these challenges. The model's effectiveness stems from two key improvements: (1) a spatial attention supervision mechanism specifically handles the localization of small objects and their components, and (2) a flexible and efficient segmentation query mechanism that handles both single-target and multi-target scenarios. Experimental results demonstrate that our SegEarth-R2 achieves outstanding performance on LaSeRS and other benchmarks, establishing a powerful baseline for the next generation of geospatial segmentation. All data and code will be released at https://github.com/earth-insights/SegEarth-R2.
Point What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025
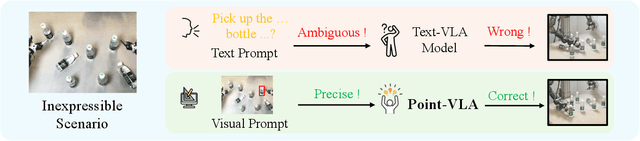
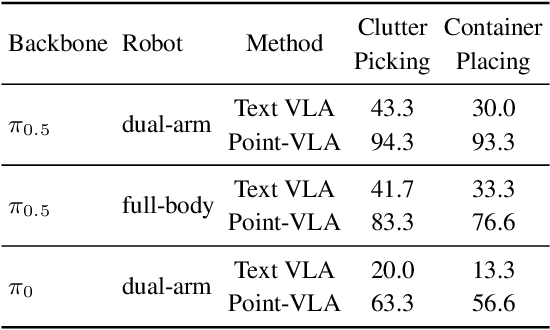
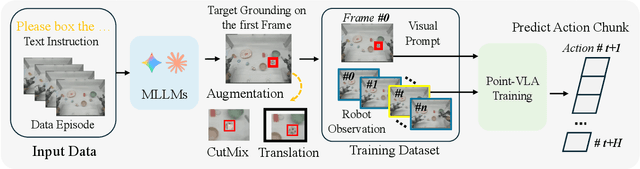
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
SegEarth-OV3: Exploring SAM 3 for Open-Vocabulary Semantic Segmentation in Remote Sensing Images
Dec 09, 2025Most existing methods for training-free Open-Vocabulary Semantic Segmentation (OVSS) are based on CLIP. While these approaches have made progress, they often face challenges in precise localization or require complex pipelines to combine separate modules, especially in remote sensing scenarios where numerous dense and small targets are present. Recently, Segment Anything Model 3 (SAM 3) was proposed, unifying segmentation and recognition in a promptable framework. In this paper, we present a preliminary exploration of applying SAM 3 to the remote sensing OVSS task without any training. First, we implement a mask fusion strategy that combines the outputs from SAM 3's semantic segmentation head and the Transformer decoder (instance head). This allows us to leverage the strengths of both heads for better land coverage. Second, we utilize the presence score from the presence head to filter out categories that do not exist in the scene, reducing false positives caused by the vast vocabulary sizes and patch-level processing in geospatial scenes. We evaluate our method on extensive remote sensing datasets. Experiments show that this simple adaptation achieves promising performance, demonstrating the potential of SAM 3 for remote sensing OVSS. Our code is released at https://github.com/earth-insights/SegEarth-OV-3.
ZoomEarth: Active Perception for Ultra-High-Resolution Geospatial Vision-Language Tasks
Nov 15, 2025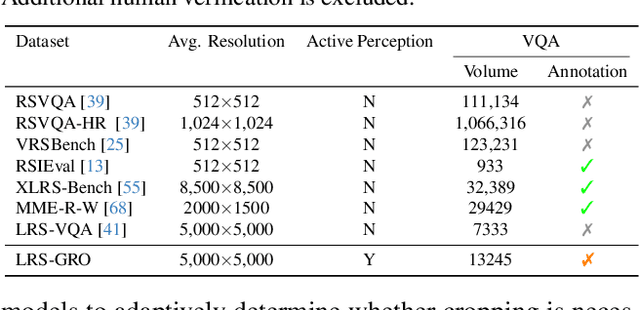
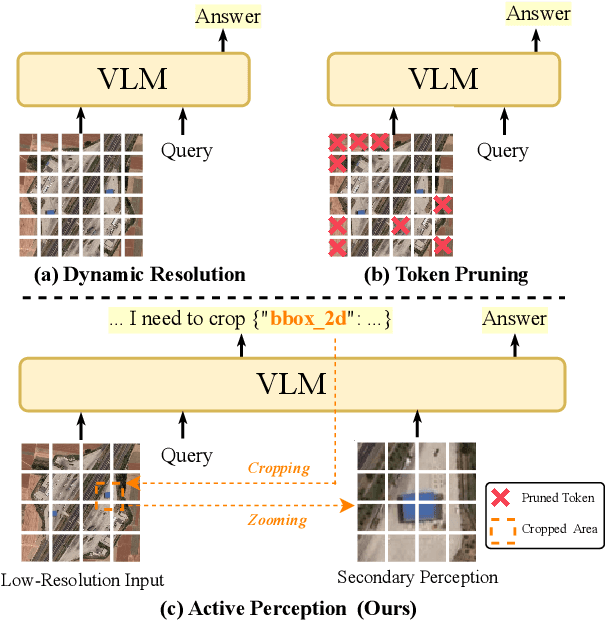
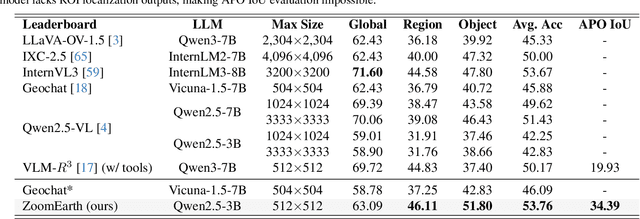
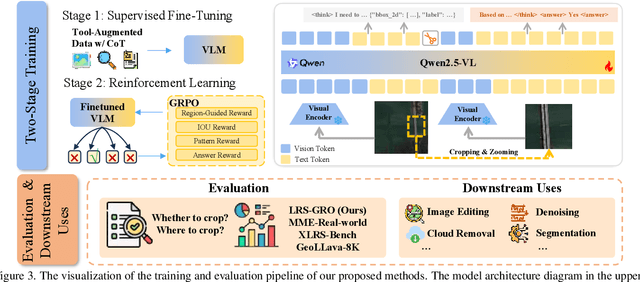
Ultra-high-resolution (UHR) remote sensing (RS) images offer rich fine-grained information but also present challenges in effective processing. Existing dynamic resolution and token pruning methods are constrained by a passive perception paradigm, suffering from increased redundancy when obtaining finer visual inputs. In this work, we explore a new active perception paradigm that enables models to revisit information-rich regions. First, we present LRS-GRO, a large-scale benchmark dataset tailored for active perception in UHR RS processing, encompassing 17 question types across global, region, and object levels, annotated via a semi-automatic pipeline. Building on LRS-GRO, we propose ZoomEarth, an adaptive cropping-zooming framework with a novel Region-Guided reward that provides fine-grained guidance. Trained via supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), ZoomEarth achieves state-of-the-art performance on LRS-GRO and, in the zero-shot setting, on three public UHR remote sensing benchmarks. Furthermore, ZoomEarth can be seamlessly integrated with downstream models for tasks such as cloud removal, denoising, segmentation, and image editing through simple tool interfaces, demonstrating strong versatility and extensibility.