 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-CC: Mask Enhanced Video Model for Remote Sensing Change Caption
Paper and Code
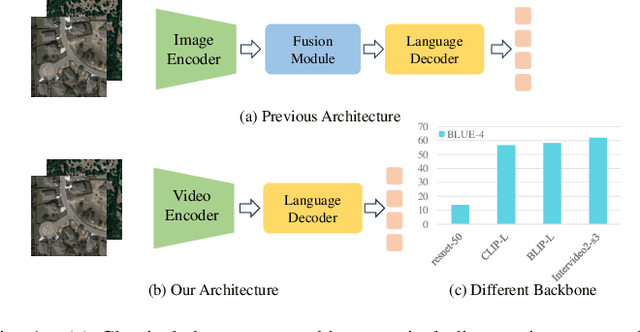

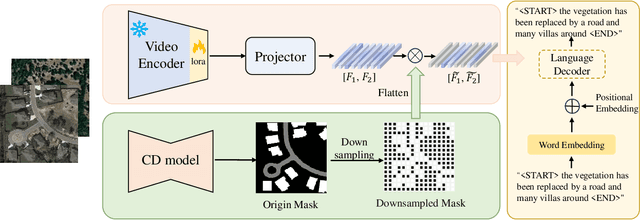
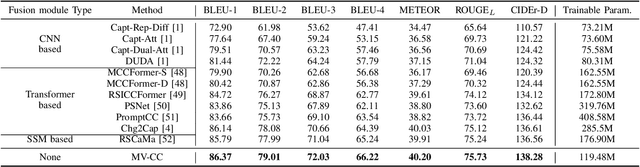
Remote sensing image change caption (RSICC) aims to provide natural language descriptions for bi-temporal remote sensing images. Since Change Caption (CC) task requires both spatial and temporal features, previous works follow an encoder-fusion-decoder architecture. They use an image encoder to extract spatial features and the fusion module to integrate spatial features and extract temporal features, which leads to increasingly complex manual design of the fusion module. In this paper, we introduce a novel video model-based paradigm without design of the fusion module and propose a Mask-enhanced Video model for Change Caption (MV-CC). Specifically, we use the off-the-shelf video encoder to simultaneously extract the temporal and spatial features of bi-temporal images. Furthermore, the types of changes in the CC are set based on specific task requirements, and to enable the model to better focus on the regions of interest, we employ masks obtained from the Change Detection (CD) method to explicitly guide the CC model. Experimental results demonstrate that our proposed method can obtain better performance compared with other state-of-the-art RSICC methods. The code is available at https://github.com/liuruixun/MV-CC.