 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchcodec: Adaptive residual-expert sparse quantization for high-fidelity neural audio coding
Jan 28, 2026Recent neural audio compression models often rely on residual vector quantization for high-fidelity coding, but using a fixed number of per-frame codebooks is suboptimal for the wide variability of audio content-especially for signals that are either very simple or highly complex. To address this limitation, we propose SwitchCodec, a neural audio codec based on Residual Experts Vector Quantization (REVQ). REVQ combines a shared quantizer with dynamically routed expert quantizers that are activated according to the input audio, decoupling bitrate from codebook capacity and improving compression efficiency. This design ensures full training and utilization of each quantizer. In addition, a variable-bitrate mechanism adjusts the number of active expert quantizers at inference, enabling multi-bitrate operation without retraining. Experiments demonstrate that SwitchCodec surpasses existing baselines on both objective metrics and subjective listening tests.
Semantically Robust Unsupervised Image Translation for Paired Remote Sensing Images
Feb 17, 2025Image translation for change detection or classification in bi-temporal remote sensing images is unique. Although it can acquire paired images, it is still unsupervised. Moreover, strict semantic preservation in translation is always needed instead of multimodal outputs. In response to these problems, this paper proposes a new method, SRUIT (Semantically Robust Unsupervised Image-to-image Translation), which ensures semantically robust translation and produces deterministic output. Inspired by previous works, the method explores the underlying characteristics of bi-temporal Remote Sensing images and designs the corresponding networks. Firstly, we assume that bi-temporal Remote Sensing images share the same latent space, for they are always acquired from the same land location. So SRUIT makes the generators share their high-level layers, and this constraint will compel two domain mapping to fall into the same latent space. Secondly, considering land covers of bi-temporal images could evolve into each other, SRUIT exploits the cross-cycle-consistent adversarial networks to translate from one to the other and recover them. Experimental results show that constraints of sharing weights and cross-cycle consistency enable translated images with both good perceptual image quality and semantic preservation for significant differences.
qNBO: quasi-Newton Meets Bilevel Optimization
Feb 03, 2025Bilevel optimization, addressing challenges in hierarchical learning tasks, has gained significant interest in machine learning. The practical implementation of the gradient descent method to bilevel optimization encounters computational hurdles, notably the computation of the exact lower-level solution and the inverse Hessian of the lower-level objective. Although these two aspects are inherently connected, existing methods typically handle them separately by solving the lower-level problem and a linear system for the inverse Hessian-vector product. In this paper, we introduce a general framework to address these computational challenges in a coordinated manner. Specifically, we leverage quasi-Newton algorithms to accelerate the resolution of the lower-level problem while efficiently approximating the inverse Hessian-vector product. Furthermore, by exploiting the superlinear convergence properties of BFGS, we establish the non-asymptotic convergence analysis of the BFGS adaptation within our framework. Numerical experiments demonstrate the comparable or superior performance of the proposed algorithms in real-world learning tasks, including hyperparameter optimization, data hyper-cleaning, and few-shot meta-learning.
Open-CD: A Comprehensive Toolbox for Change Detection
Jul 22, 2024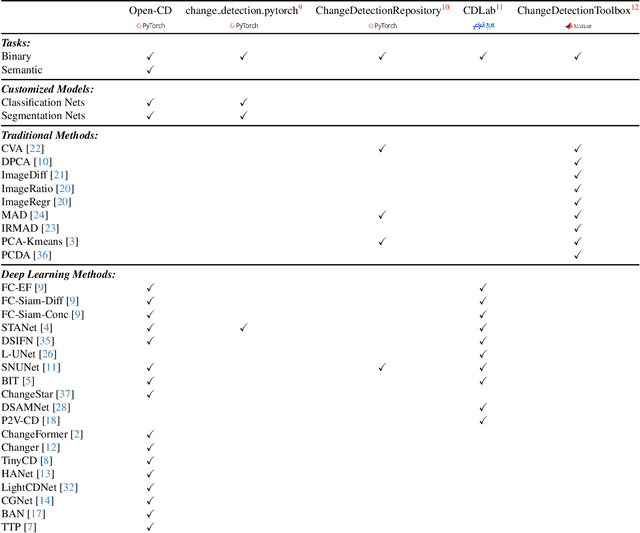
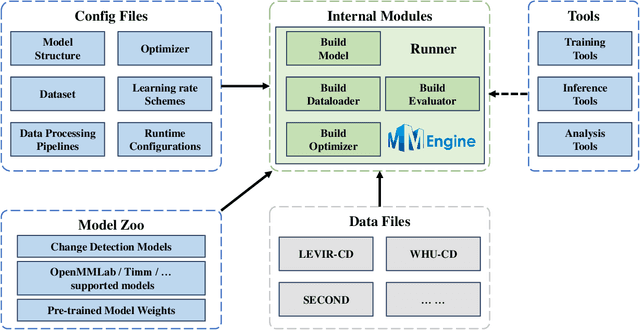
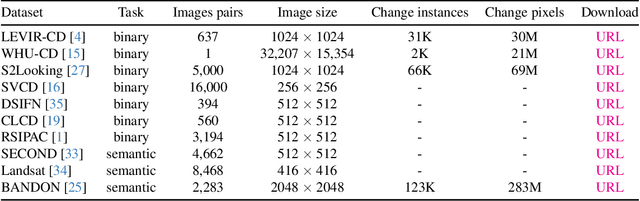
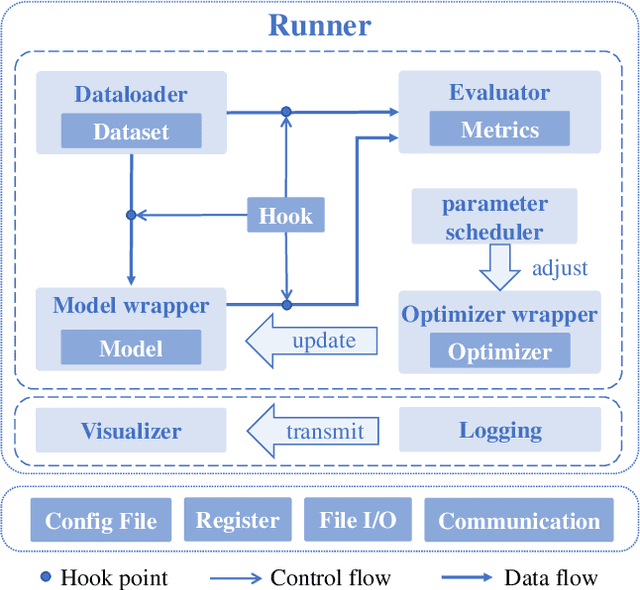
We present Open-CD, a change detection toolbox that contains a rich set of change detection methods as well as related components and modules. The toolbox started from a series of open source general vision task tools, including OpenMMLab Toolkits, PyTorch Image Models, etc. It gradually evolves into a unified platform that covers many popular change detection methods and contemporary modules. It not only includes training and inference codes, but also provides some useful scripts for data analysis. We believe this toolbox is by far the most complete change detection toolbox. In this report, we introduce the various features, supported methods and applications of Open-CD. In addition, we also conduct a benchmarking study on different methods and components. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new change detectors. Code and models are available at \url{https://github.com/likyoo/open-cd}. Pioneeringly, this report also includes brief descriptions of the algorithms supported in Open-CD, mainly contributed by their authors. We sincerely encourage researchers in this field to participate in this project and work together to create a more open community. This toolkit and report will be kept updated.
Changer: Feature Interaction is What You Need for Change Detection
Sep 17, 2022

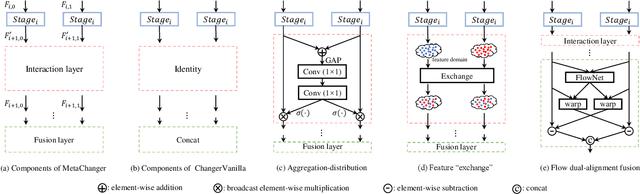

Change detection is an important tool for long-term earth observation missions. It takes bi-temporal images as input and predicts "where" the change has occurred. Different from other dense prediction tasks, a meaningful consideration for change detection is the interaction between bi-temporal features. With this motivation, in this paper we propose a novel general change detection architecture, MetaChanger, which includes a series of alternative interaction layers in the feature extractor. To verify the effectiveness of MetaChanger, we propose two derived models, ChangerAD and ChangerEx with simple interaction strategies: Aggregation-Distribution (AD) and "exchange". AD is abstracted from some complex interaction methods, and "exchange" is a completely parameter\&computation-free operation by exchanging bi-temporal features. In addition, for better alignment of bi-temporal features, we propose a flow dual-alignment fusion (FDAF) module which allows interactive alignment and feature fusion. Crucially, we observe Changer series models achieve competitive performance on different scale change detection datasets. Further, our proposed ChangerAD and ChangerEx could serve as a starting baseline for future MetaChanger design.
Salient Positions based Attention Network for Image Classification
Jun 09, 2021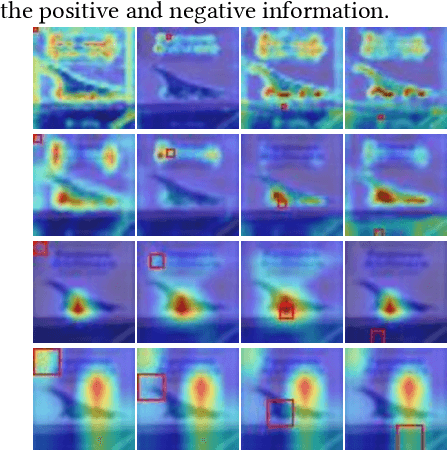
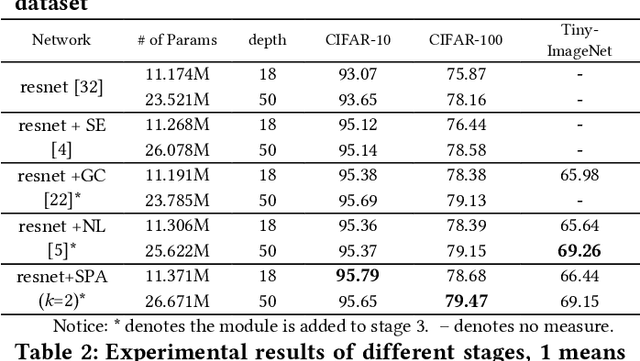
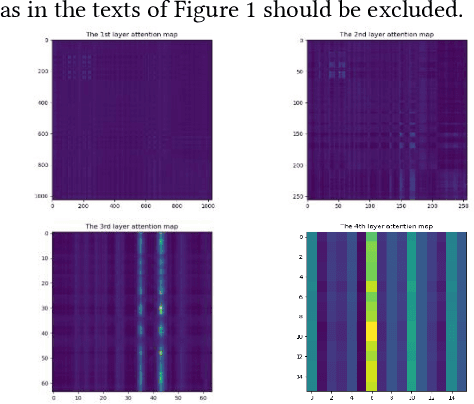

The self-attention mechanism has attracted wide publicity for its most important advantage of modeling long dependency, and its variations in computer vision tasks, the non-local block tries to model the global dependency of the input feature maps. Gathering global contextual information will inevitably need a tremendous amount of memory and computing resources, which has been extensively studied in the past several years. However, there is a further problem with the self-attention scheme: is all information gathered from the global scope helpful for the contextual modelling? To our knowledge, few studies have focused on the problem. Aimed at both questions this paper proposes the salient positions-based attention scheme SPANet, which is inspired by some interesting observations on the attention maps and affinity matrices generated in self-attention scheme. We believe these observations are beneficial for better understanding of the self-attention. SPANet uses the salient positions selection algorithm to select only a limited amount of salient points to attend in the attention map computing. This approach will not only spare a lot of memory and computing resources, but also try to distill the positive information from the transformation of the input feature maps. In the implementation, considering the feature maps with channel high dimensions, which are completely different from the general visual image, we take the squared power of the feature maps along the channel dimension as the saliency metric of the positions. In general, different from the non-local block method, SPANet models the contextual information using only the selected positions instead of all, along the channel dimension instead of space dimension. Our source code is available at https://github.com/likyoo/SPANet.