 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIR-ALIGN: Enhancing Hyperspectral Image Restoration via Diffusion-Based Data Generation
May 13, 2026Hyperspectral image (HSI) restoration is crucial for reliable analysis, as real HSIs suffer from degradations like noise, blur, and resolution loss. However, existing models trained on source data often fail on target domains lacking clean references, a common occurrence in practice. To address this issue, we present HIR-ALIGN, a plug-and-play target-adaptive augmentation framework that enhances hyperspectral image restoration by augmenting limited training images with synthetic data that closely matches the target distribution using no extra data. It consists of three stages: (i) proxy generation, where off-the-shelf restoration models restore degraded target observations to produce semantics-preserving proxy HSIs that approximate target-domain clean images; (ii) distribution-adaptive synthesis, where a blur-robust unCLIP diffusion model generates target-aligned RGBs from proxy RGBs, with prompt conditioning and embedding-space noise initialization. Then, a warp-based spectral transfer module synthesizes HSIs by aligning each generated RGB with the proxy RGB, estimating soft patch-wise transport weights, and applying these weights and learnable local interpolation kernels to the proxy HSI; and (iii) aligned supervised finetuning, where restoration networks pretrained on the source distribution are finetuned using both the proxy HSIs and synthesized target-aligned HSIs, and are then deployed on degraded target images. We further provide theoretical analysis showing that augmentation-based finetuning can achieve lower target-domain restoration risk by jointly improving target distribution coverage and controlling spectral bias. Extensive experiments on simulated and real datasets across denoising and super-resolution tasks demonstrate that HIR-ALIGN consistently improves source-only supervised baselines, outperforming both source-only counterparts and representative unsupervised methods.
The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model
Apr 13, 2025Remote sensing has become critical for understanding environmental dynamics, urban planning, and disaster management. However, traditional remote sensing workflows often rely on explicit segmentation or detection methods, which struggle to handle complex, implicit queries that require reasoning over spatial context, domain knowledge, and implicit user intent. Motivated by this, we introduce a new task, \ie, geospatial pixel reasoning, which allows implicit querying and reasoning and generates the mask of the target region. To advance this task, we construct and release the first large-scale benchmark dataset called EarthReason, which comprises 5,434 manually annotated image masks with over 30,000 implicit question-answer pairs. Moreover, we propose SegEarth-R1, a simple yet effective language-guided segmentation baseline that integrates a hierarchical visual encoder, a large language model (LLM) for instruction parsing, and a tailored mask generator for spatial correlation. The design of SegEarth-R1 incorporates domain-specific adaptations, including aggressive visual token compression to handle ultra-high-resolution remote sensing images, a description projection module to fuse language and multi-scale features, and a streamlined mask prediction pipeline that directly queries description embeddings. Extensive experiments demonstrate that SegEarth-R1 achieves state-of-the-art performance on both reasoning and referring segmentation tasks, significantly outperforming traditional and LLM-based segmentation methods. Our data and code will be released at https://github.com/earth-insights/SegEarth-R1.
SPECIAL: Zero-shot Hyperspectral Image Classification With CLIP
Jan 27, 2025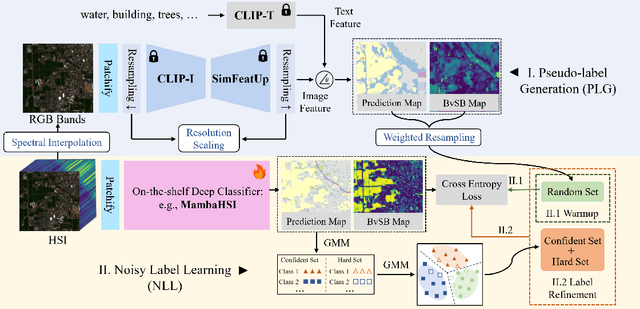

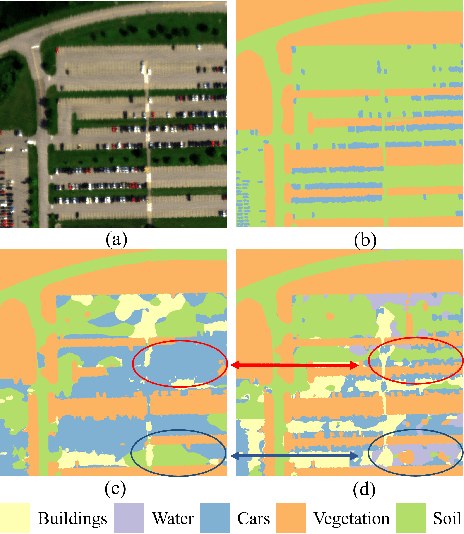
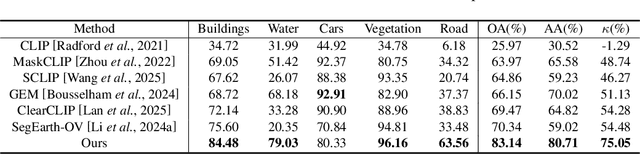
Hyperspectral image (HSI) classification aims at categorizing each pixel in an HSI into a specific land cover class, which is crucial for applications like remote sensing, environmental monitoring, and agriculture. Although deep learning-based HSI classification methods have achieved significant advancements, existing methods still rely on manually labeled data for training, which is both time-consuming and labor-intensive.To address this limitation, we introduce a novel zero-shot hyperspectral image classification framework based on CLIP (SPECIAL), aiming to eliminate the need for manual annotations. The SPECIAL framework consists of two main stages: (1) CLIP-based pseudo-label generation, and (2) noisy label learning. In the first stage, HSI is spectrally interpolated to produce RGB bands. These bands are subsequently classified using CLIP, resulting in noisy pseudo-labels that are accompanied by confidence scores.To improve the quality of these labels, we propose a scaling strategy that fuses predictions from multiple spatial scales. In the second stage, spectral information and a label refinement technique are incorporated to mitigate label noise and further enhance classification accuracy. Experimental results on three benchmark datasets demonstrate that our SPECIAL outperforms existing methods in zero-shot HSI classification, showing its potential for more practical applications. The code is available at https://github.com/LiPang/SPECIAL.
HAIR: Hypernetworks-based All-in-One Image Restoration
Aug 15, 2024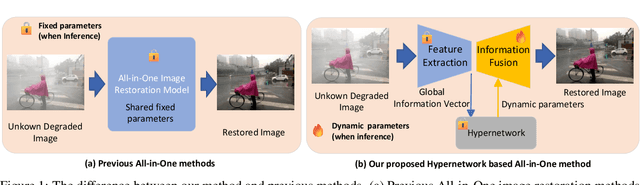
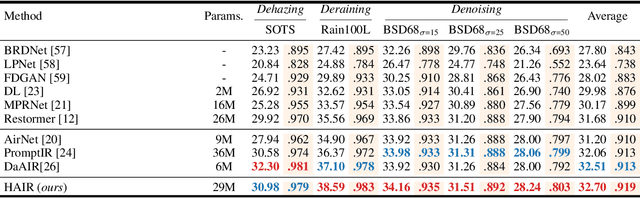
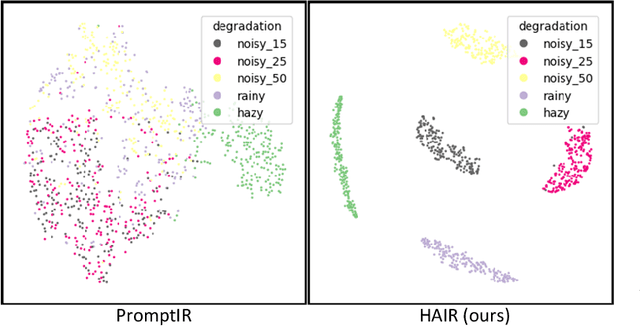
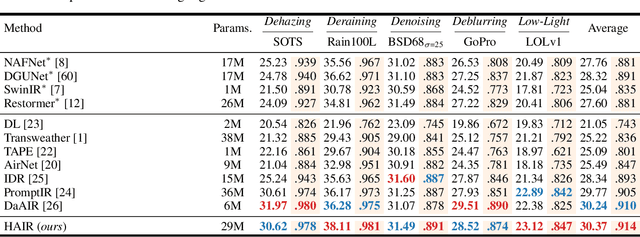
Image restoration involves recovering a high-quality clean image from its degraded version, which is a fundamental task in computer vision. Recent progress in image restoration has demonstrated the effectiveness of learning models capable of addressing various degradations simultaneously, i.e., the All-in-One image restoration models. However, these existing methods typically utilize the same parameters facing images with different degradation types, which causes the model to be forced to trade off between degradation types, therefore impair the total performance. To solve this problem, we propose HAIR, a Hypernetworks-based plug-in-and-play method that dynamically generated parameters for the corresponding networks based on the contents of input images. HAIR consists of 2 main components: Classifier (Cl) and Hyper Selecting Net (HSN). To be more specific, the Classifier is a simple image classification network which is used to generate a Global Information Vector (GIV) that contains the degradation information of the input image; And the HSNs can be seen as a simple Fully-connected Neural Network that receive the GIV and output parameters for the corresponding modules. Extensive experiments shows that incorporating HAIR into the architectures can significantly improve the performance of different models on image restoration tasks at a low cost, \textbf{although HAIR only generate parameters and haven't change these models' logical structures at all.} With incorporating HAIR into the popular architecture Restormer, our method obtains superior or at least comparable performance to current state-of-the-art methods on a range of image restoration tasks. \href{https://github.com/toummHus/HAIR}{\textcolor{blue}{$\underline{\textbf{Code and pre-trained checkpoints are available here.}}$}}
HIR-Diff: Unsupervised Hyperspectral Image Restoration Via Improved Diffusion Models
Feb 24, 2024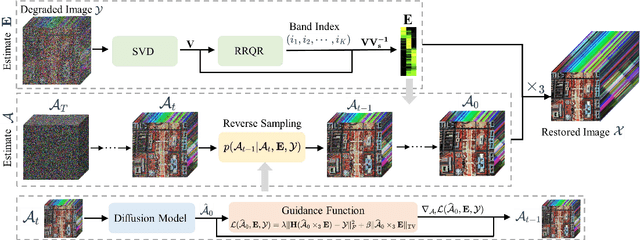
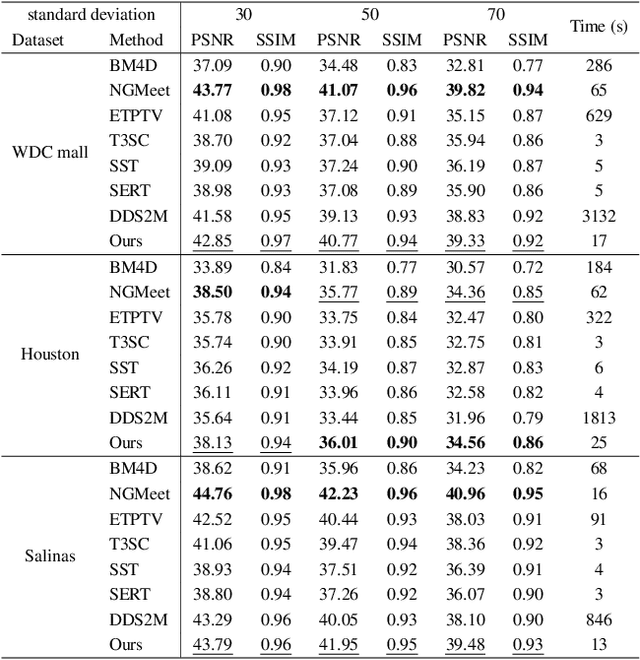
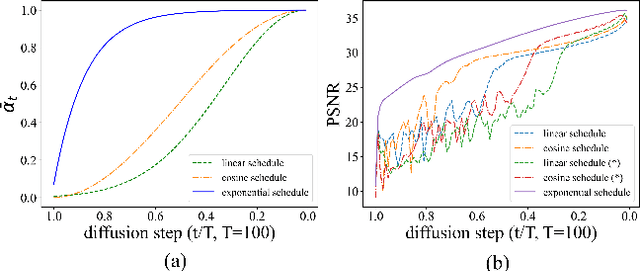
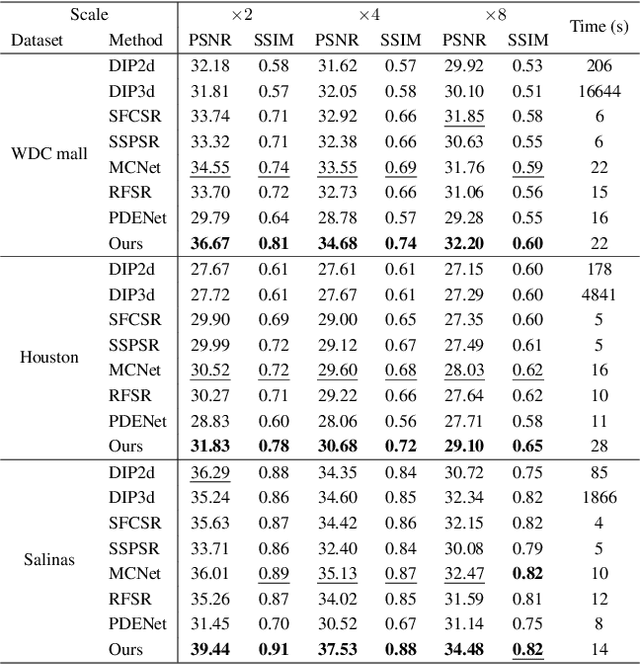
Hyperspectral image (HSI) restoration aims at recovering clean images from degraded observations and plays a vital role in downstream tasks. Existing model-based methods have limitations in accurately modeling the complex image characteristics with handcraft priors, and deep learning-based methods suffer from poor generalization ability. To alleviate these issues, this paper proposes an unsupervised HSI restoration framework with pre-trained diffusion model (HIR-Diff), which restores the clean HSIs from the product of two low-rank components, i.e., the reduced image and the coefficient matrix. Specifically, the reduced image, which has a low spectral dimension, lies in the image field and can be inferred from our improved diffusion model where a new guidance function with total variation (TV) prior is designed to ensure that the reduced image can be well sampled. The coefficient matrix can be effectively pre-estimated based on singular value decomposition (SVD) and rank-revealing QR (RRQR) factorization. Furthermore, a novel exponential noise schedule is proposed to accelerate the restoration process (about 5$\times$ acceleration for denoising) with little performance decrease. Extensive experimental results validate the superiority of our method in both performance and speed on a variety of HSI restoration tasks, including HSI denoising, noisy HSI super-resolution, and noisy HSI inpainting. The code is available at https://github.com/LiPang/HIRDiff.
HIDFlowNet: A Flow-Based Deep Network for Hyperspectral Image Denoising
Jun 20, 2023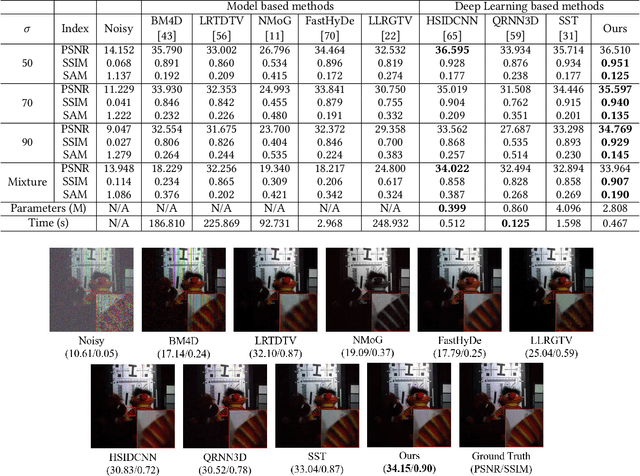
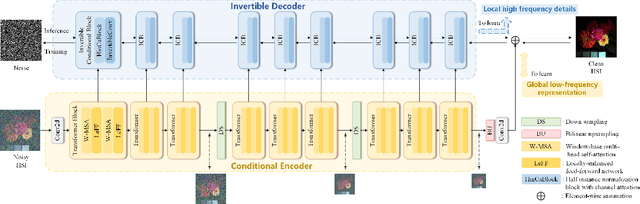
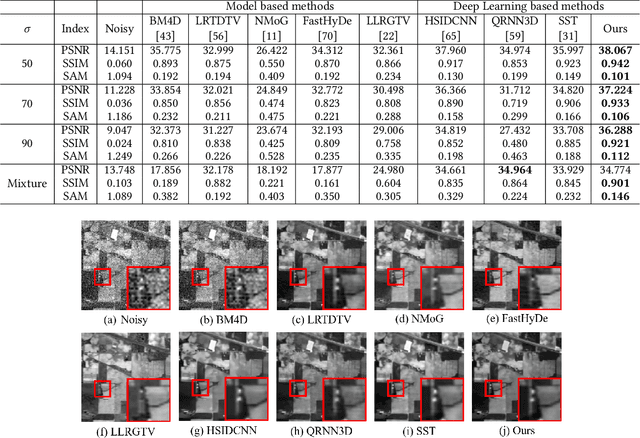
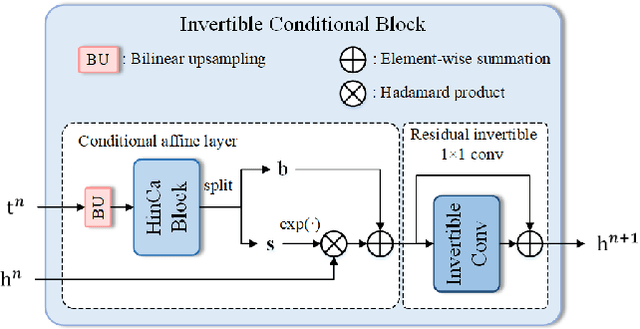
Hyperspectral image (HSI) denoising is essentially ill-posed since a noisy HSI can be degraded from multiple clean HSIs. However, current deep learning-based approaches ignore this fact and restore the clean image with deterministic mapping (i.e., the network receives a noisy HSI and outputs a clean HSI). To alleviate this issue, this paper proposes a flow-based HSI denoising network (HIDFlowNet) to directly learn the conditional distribution of the clean HSI given the noisy HSI and thus diverse clean HSIs can be sampled from the conditional distribution. Overall, our HIDFlowNet is induced from the flow methodology and contains an invertible decoder and a conditional encoder, which can fully decouple the learning of low-frequency and high-frequency information of HSI. Specifically, the invertible decoder is built by staking a succession of invertible conditional blocks (ICBs) to capture the local high-frequency details since the invertible network is information-lossless. The conditional encoder utilizes down-sampling operations to obtain low-resolution images and uses transformers to capture correlations over a long distance so that global low-frequency information can be effectively extracted. Extensive experimental results on simulated and real HSI datasets verify the superiority of our proposed HIDFlowNet compared with other state-of-the-art methods both quantitatively and visually.