 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Prompt Tuning: Advancing In-Context Learning with Adversarial Methods
Oct 22, 2024Fine-tuning Large Language Models (LLMs) typically involves updating at least a few billions of parameters. A more parameter-efficient approach is Prompt Tuning (PT), which updates only a few learnable tokens, and differently, In-Context Learning (ICL) adapts the model to a new task by simply including examples in the input without any training. When applying optimization-based methods, such as fine-tuning and PT for few-shot learning, the model is specifically adapted to the small set of training examples, whereas ICL leaves the model unchanged. This distinction makes traditional learning methods more prone to overfitting; in contrast, ICL is less sensitive to the few-shot scenario. While ICL is not prone to overfitting, it does not fully extract the information that exists in the training examples. This work introduces Context-aware Prompt Tuning (CPT), a method inspired by ICL, PT, and adversarial attacks. We build on the ICL strategy of concatenating examples before the input, but we extend this by PT-like learning, refining the context embedding through iterative optimization to extract deeper insights from the training examples. We carefully modify specific context tokens, considering the unique structure of input and output formats. Inspired by adversarial attacks, we adjust the input based on the labels present in the context, focusing on minimizing, rather than maximizing, the loss. Moreover, we apply a projected gradient descent algorithm to keep token embeddings close to their original values, under the assumption that the user-provided data is inherently valuable. Our method has been shown to achieve superior accuracy across multiple classification tasks using various LLM models.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020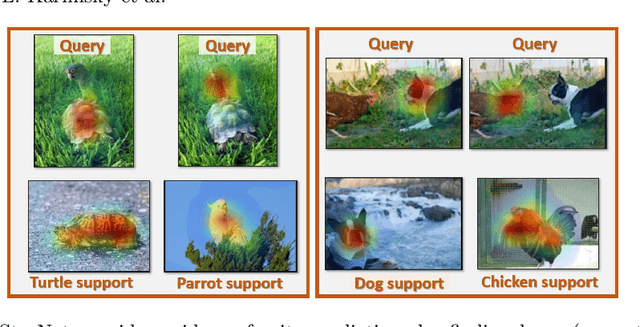
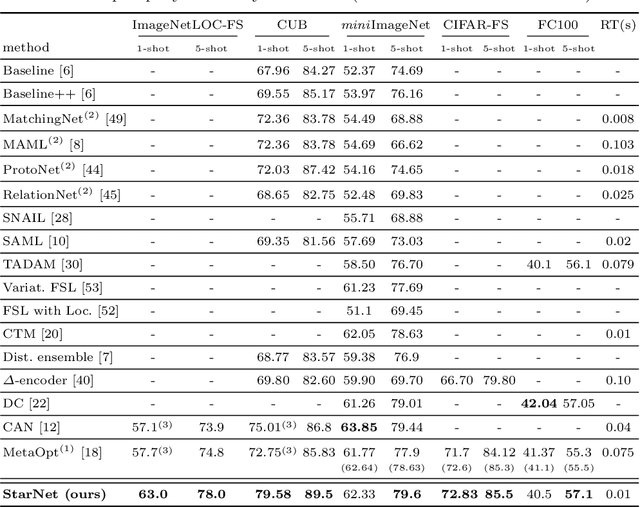
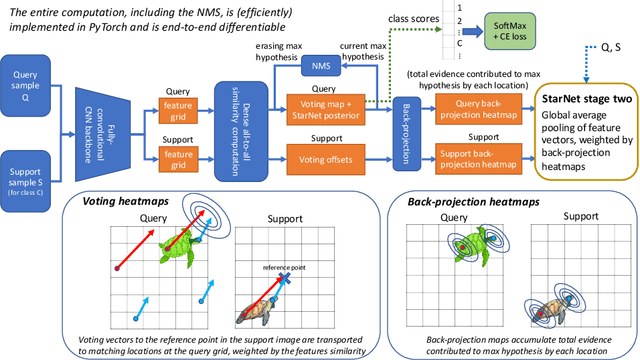
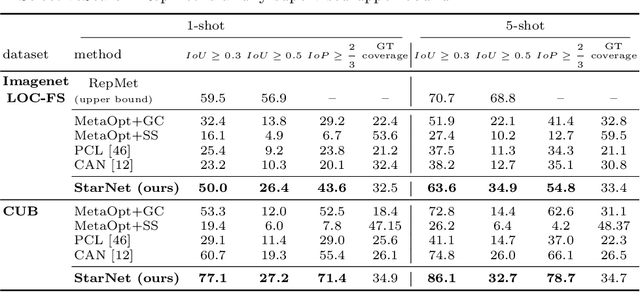
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.