 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThere is no Accuracy-Interpretability Tradeoff in Reinforcement Learning for Mazes
Paper and Code
Jun 09, 2022


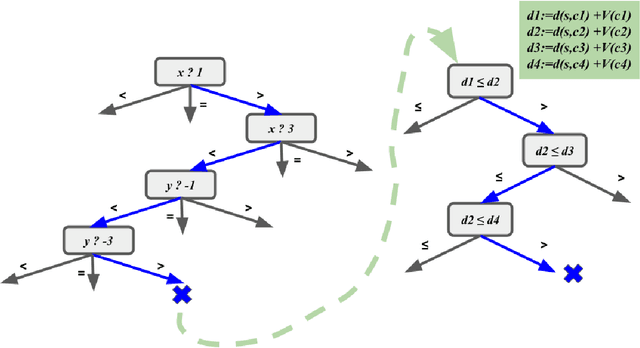
Interpretability is an essential building block for trustworthiness in reinforcement learning systems. However, interpretability might come at the cost of deteriorated performance, leading many researchers to build complex models. Our goal is to analyze the cost of interpretability. We show that in certain cases, one can achieve policy interpretability while maintaining its optimality. We focus on a classical problem from reinforcement learning: mazes with $k$ obstacles in $\mathbb{R}^d$. We prove the existence of a small decision tree with a linear function at each inner node and depth $O(\log k + 2^d)$ that represents an optimal policy. Note that for the interesting case of a constant $d$, we have $O(\log k)$ depth. Thus, in this setting, there is no accuracy-interpretability tradeoff. To prove this result, we use a new "compressing" technique that might be useful in additional settings.