 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQT -- std $Q$-target
Feb 12, 2024Std $Q$-target is a conservative, actor-critic, ensemble, $Q$-learning-based algorithm, which is based on a single key $Q$-formula: $Q$-networks standard deviation, which is an "uncertainty penalty", and, serves as a minimalistic solution to the problem of overestimation bias. We implement SQT on top of TD3/TD7 code and test it against the state-of-the-art (SOTA) actor-critic algorithms, DDPG, TD3 and TD7 on seven popular MuJoCo and Bullet tasks. Our results demonstrate SQT's $Q$-target formula superiority over TD3's $Q$-target formula as a conservative solution to overestimation bias in RL, while SQT shows a clear performance advantage on a wide margin over DDPG, TD3, and TD7 on all tasks.
DUQIM-Net: Probabilistic Object Hierarchy Representation for Multi-View Manipulation
Jul 19, 2022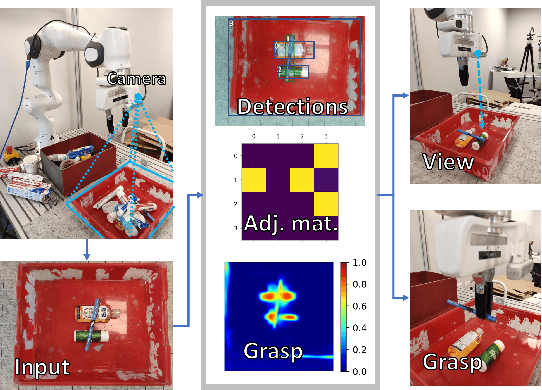
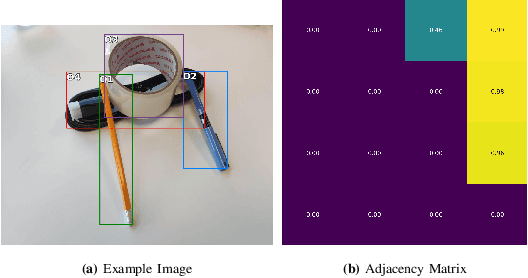
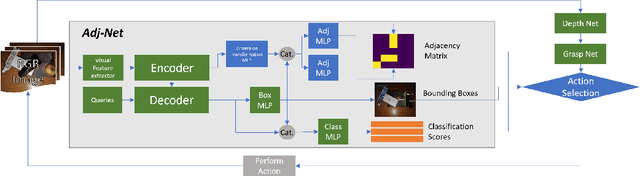
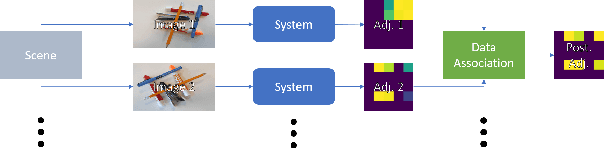
Object manipulation in cluttered scenes is a difficult and important problem in robotics. To efficiently manipulate objects, it is crucial to understand their surroundings, especially in cases where multiple objects are stacked one on top of the other, preventing effective grasping. We here present DUQIM-Net, a decision-making approach for object manipulation in a setting of stacked objects. In DUQIM-Net, the hierarchical stacking relationship is assessed using Adj-Net, a model that leverages existing Transformer Encoder-Decoder object detectors by adding an adjacency head. The output of this head probabilistically infers the underlying hierarchical structure of the objects in the scene. We utilize the properties of the adjacency matrix in DUQIM-Net to perform decision making and assist with object-grasping tasks. Our experimental results show that Adj-Net surpasses the state-of-the-art in object-relationship inference on the Visual Manipulation Relationship Dataset (VMRD), and that DUQIM-Net outperforms comparable approaches in bin clearing tasks.
Analysis of Stochastic Processes through Replay Buffers
Jun 26, 2022
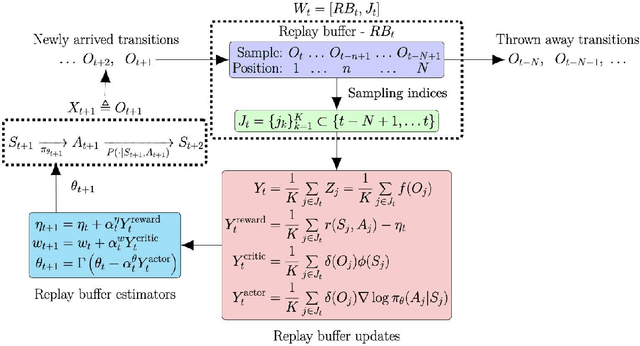
Replay buffers are a key component in many reinforcement learning schemes. Yet, their theoretical properties are not fully understood. In this paper we analyze a system where a stochastic process X is pushed into a replay buffer and then randomly sampled to generate a stochastic process Y from the replay buffer. We provide an analysis of the properties of the sampled process such as stationarity, Markovity and autocorrelation in terms of the properties of the original process. Our theoretical analysis sheds light on why replay buffer may be a good de-correlator. Our analysis provides theoretical tools for proving the convergence of replay buffer based algorithms which are prevalent in reinforcement learning schemes.