 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sample Complexity Of ERMs In Stochastic Convex Optimization
Nov 09, 2023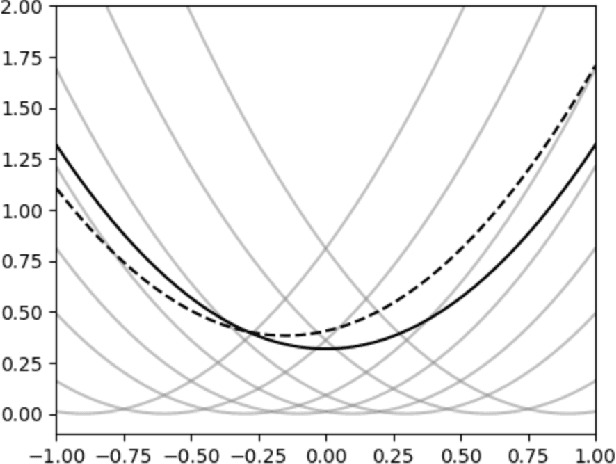
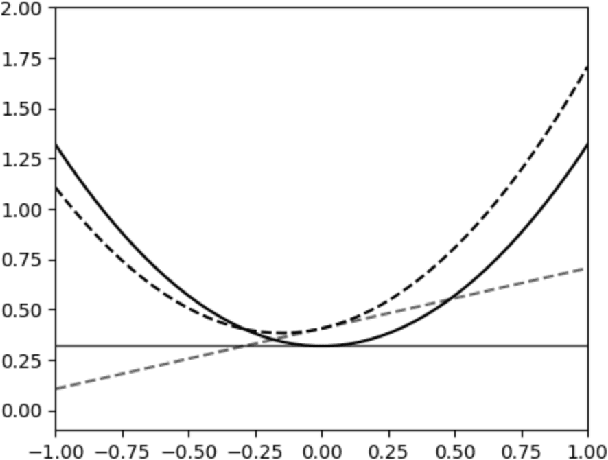
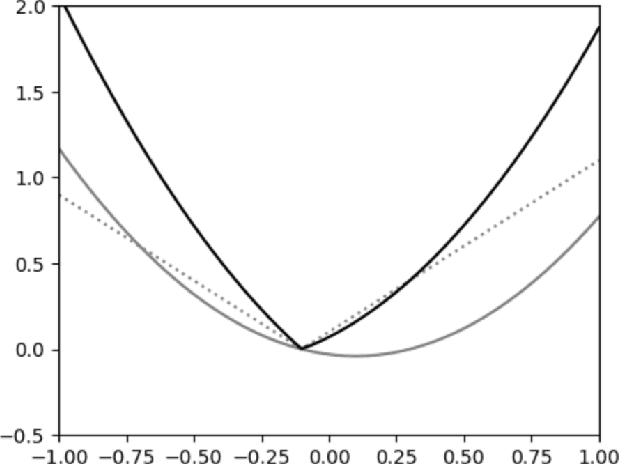
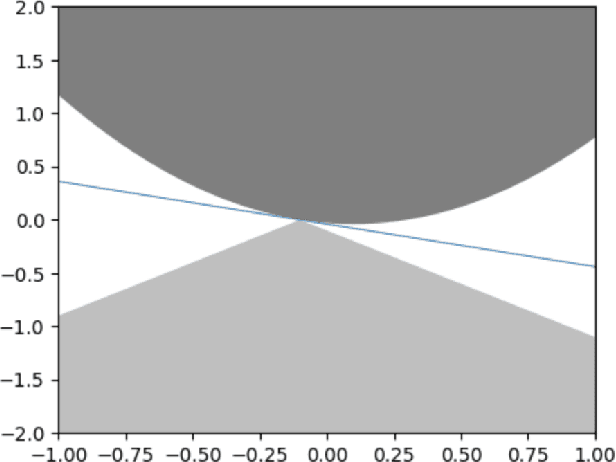
Stochastic convex optimization is one of the most well-studied models for learning in modern machine learning. Nevertheless, a central fundamental question in this setup remained unresolved: "How many data points must be observed so that any empirical risk minimizer (ERM) shows good performance on the true population?" This question was proposed by Feldman (2016), who proved that $\Omega(\frac{d}{\epsilon}+\frac{1}{\epsilon^2})$ data points are necessary (where $d$ is the dimension and $\epsilon>0$ is the accuracy parameter). Proving an $\omega(\frac{d}{\epsilon}+\frac{1}{\epsilon^2})$ lower bound was left as an open problem. In this work we show that in fact $\tilde{O}(\frac{d}{\epsilon}+\frac{1}{\epsilon^2})$ data points are also sufficient. This settles the question and yields a new separation between ERMs and uniform convergence. This sample complexity holds for the classical setup of learning bounded convex Lipschitz functions over the Euclidean unit ball. We further generalize the result and show that a similar upper bound holds for all symmetric convex bodies. The general bound is composed of two terms: (i) a term of the form $\tilde{O}(\frac{d}{\epsilon})$ with an inverse-linear dependence on the accuracy parameter, and (ii) a term that depends on the statistical complexity of the class of $\textit{linear}$ functions (captured by the Rademacher complexity). The proof builds a mechanism for controlling the behavior of stochastic convex optimization problems.
A Characterization of Multiclass Learnability
Mar 03, 2022
A seminal result in learning theory characterizes the PAC learnability of binary classes through the Vapnik-Chervonenkis dimension. Extending this characterization to the general multiclass setting has been open since the pioneering works on multiclass PAC learning in the late 1980s. This work resolves this problem: we characterize multiclass PAC learnability through the DS dimension, a combinatorial dimension defined by Daniely and Shalev-Shwartz (2014). The classical characterization of the binary case boils down to empirical risk minimization. In contrast, our characterization of the multiclass case involves a variety of algorithmic ideas; these include a natural setting we call list PAC learning. In the list learning setting, instead of predicting a single outcome for a given unseen input, the goal is to provide a short menu of predictions. Our second main result concerns the Natarajan dimension, which has been a central candidate for characterizing multiclass learnability. This dimension was introduced by Natarajan (1988) as a barrier for PAC learning. Whether the Natarajan dimension characterizes PAC learnability in general has been posed as an open question in several papers since. This work provides a negative answer: we construct a non-learnable class with Natarajan dimension one. For the construction, we identify a fundamental connection between concept classes and topology (i.e., colorful simplicial complexes). We crucially rely on a deep and involved construction of hyperbolic pseudo-manifolds by Januszkiewicz and Swiatkowski. It is interesting that hyperbolicity is directly related to learning problems that are difficult to solve although no obvious barriers exist. This is another demonstration of the fruitful links machine learning has with different areas in mathematics.
Learning Infinite-Layer Networks: Without the Kernel Trick
Jul 28, 2017Infinite--Layer Networks (ILN) have recently been proposed as an architecture that mimics neural networks while enjoying some of the advantages of kernel methods. ILN are networks that integrate over infinitely many nodes within a single hidden layer. It has been demonstrated by several authors that the problem of learning ILN can be reduced to the kernel trick, implying that whenever a certain integral can be computed analytically they are efficiently learnable. In this work we give an online algorithm for ILN, which avoids the kernel trick assumption. More generally and of independent interest, we show that kernel methods in general can be exploited even when the kernel cannot be efficiently computed but can only be estimated via sampling. We provide a regret analysis for our algorithm, showing that it matches the sample complexity of methods which have access to kernel values. Thus, our method is the first to demonstrate that the kernel trick is not necessary as such, and random features suffice to obtain comparable performance.