 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Splatting: Generalized Fourier encoded primitives for scalable radiance fields
Mar 20, 2026Novel view synthesis has recently been revolutionized by 3D Gaussian Splatting (3DGS), which enables real-time rendering through explicit primitive rasterization. However, existing methods tie visual fidelity strictly to the number of primitives: quality downscaling is achieved only through pruning primitives. We propose the first inherently scalable primitive for radiance field rendering. Fourier Splatting employs scalable primitives with arbitrary closed shapes obtained by parameterizing planar surfels with Fourier encoded descriptors. This formulation allows a single trained model to be rendered at varying levels of detail simply by truncating Fourier coefficients at runtime. To facilitate stable optimization, we employ a straight-through estimator for gradient extension beyond the primitive boundary, and introduce HYDRA, a densification strategy that decomposes complex primitives into simpler constituents within the MCMC framework. Our method achieves state-of-the-art rendering quality among planar-primitive frameworks and comparable perceptual metrics compared to leading volumetric representations on standard benchmarks, providing a versatile solution for bandwidth-constrained high-fidelity rendering.
ReferGPT: Towards Zero-Shot Referring Multi-Object Tracking
Apr 12, 2025Tracking multiple objects based on textual queries is a challenging task that requires linking language understanding with object association across frames. Previous works typically train the whole process end-to-end or integrate an additional referring text module into a multi-object tracker, but they both require supervised training and potentially struggle with generalization to open-set queries. In this work, we introduce ReferGPT, a novel zero-shot referring multi-object tracking framework. We provide a multi-modal large language model (MLLM) with spatial knowledge enabling it to generate 3D-aware captions. This enhances its descriptive capabilities and supports a more flexible referring vocabulary without training. We also propose a robust query-matching strategy, leveraging CLIP-based semantic encoding and fuzzy matching to associate MLLM generated captions with user queries. Extensive experiments on Refer-KITTI, Refer-KITTIv2 and Refer-KITTI+ demonstrate that ReferGPT achieves competitive performance against trained methods, showcasing its robustness and zero-shot capabilities in autonomous driving. The codes are available on https://github.com/Tzoulio/ReferGPT
HybridTrack: A Hybrid Approach for Robust Multi-Object Tracking
Jan 02, 2025



The evolution of Advanced Driver Assistance Systems (ADAS) has increased the need for robust and generalizable algorithms for multi-object tracking. Traditional statistical model-based tracking methods rely on predefined motion models and assumptions about system noise distributions. Although computationally efficient, they often lack adaptability to varying traffic scenarios and require extensive manual design and parameter tuning. To address these issues, we propose a novel 3D multi-object tracking approach for vehicles, HybridTrack, which integrates a data-driven Kalman Filter (KF) within a tracking-by-detection paradigm. In particular, it learns the transition residual and Kalman gain directly from data, which eliminates the need for manual motion and stochastic parameter modeling. Validated on the real-world KITTI dataset, HybridTrack achieves 82.08% HOTA accuracy, significantly outperforming state-of-the-art methods. We also evaluate our method under different configurations, achieving the fastest processing speed of 112 FPS. Consequently, HybridTrack eliminates the dependency on scene-specific designs while improving performance and maintaining real-time efficiency. The code will be publicly available at the time of publishing: https://github.com/leandro-svg/HybridTrack.git.
Strada-LLM: Graph LLM for traffic prediction
Oct 28, 2024



Traffic prediction is a vital component of intelligent transportation systems. By reasoning about traffic patterns in both the spatial and temporal dimensions, accurate and interpretable predictions can be provided. A considerable challenge in traffic prediction lies in handling the diverse data distributions caused by vastly different traffic conditions occurring at different locations. LLMs have been a dominant solution due to their remarkable capacity to adapt to new datasets with very few labeled data samples, i.e., few-shot adaptability. However, existing forecasting techniques mainly focus on extracting local graph information and forming a text-like prompt, leaving LLM- based traffic prediction an open problem. This work presents a probabilistic LLM for traffic forecasting with three highlights. We propose a graph-aware LLM for traffic prediction that considers proximal traffic information. Specifically, by considering the traffic of neighboring nodes as covariates, our model outperforms the corresponding time-series LLM. Furthermore, we adopt a lightweight approach for efficient domain adaptation when facing new data distributions in few-shot fashion. The comparative experiment demonstrates the proposed method outperforms the state-of-the-art LLM-based methods and the traditional GNN- based supervised approaches. Furthermore, Strada-LLM can be easily adapted to different LLM backbones without a noticeable performance drop.
RESSCAL3D++: Joint Acquisition and Semantic Segmentation of 3D Point Clouds
Oct 03, 2024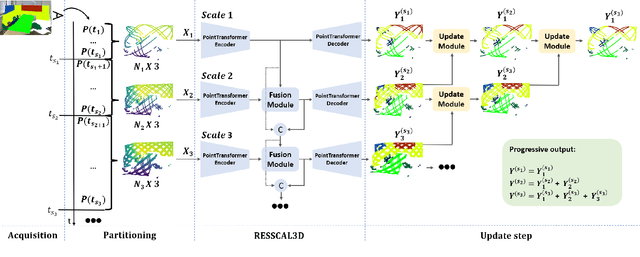



3D scene understanding is crucial for facilitating seamless interaction between digital devices and the physical world. Real-time capturing and processing of the 3D scene are essential for achieving this seamless integration. While existing approaches typically separate acquisition and processing for each frame, the advent of resolution-scalable 3D sensors offers an opportunity to overcome this paradigm and fully leverage the otherwise wasted acquisition time to initiate processing. In this study, we introduce VX-S3DIS, a novel point cloud dataset accurately simulating the behavior of a resolution-scalable 3D sensor. Additionally, we present RESSCAL3D++, an important improvement over our prior work, RESSCAL3D, by incorporating an update module and processing strategy. By applying our method to the new dataset, we practically demonstrate the potential of joint acquisition and semantic segmentation of 3D point clouds. Our resolution-scalable approach significantly reduces scalability costs from 2% to just 0.2% in mIoU while achieving impressive speed-ups of 15.6 to 63.9% compared to the non-scalable baseline. Furthermore, our scalable approach enables early predictions, with the first one occurring after only 7% of the total inference time of the baseline. The new VX-S3DIS dataset is available at https://github.com/remcoroyen/vx-s3dis.
ProtoSeg: A Prototype-Based Point Cloud Instance Segmentation Method
Oct 03, 2024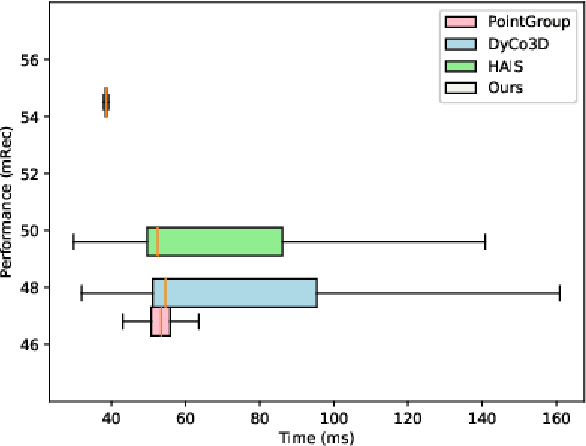
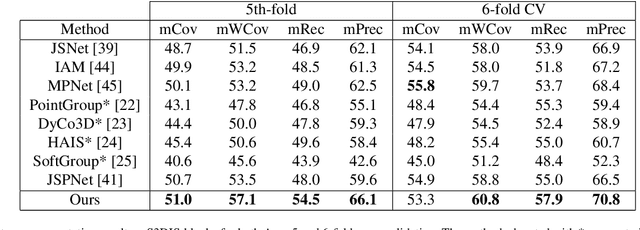
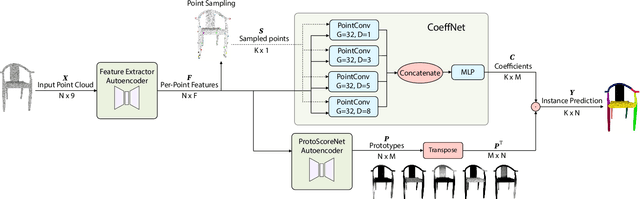
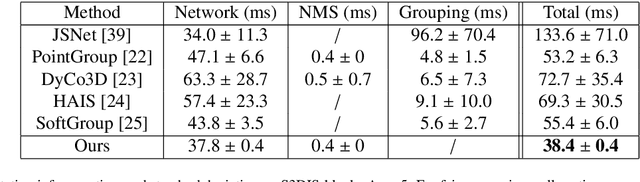
3D instance segmentation is crucial for obtaining an understanding of a point cloud scene. This paper presents a novel neural network architecture for performing instance segmentation on 3D point clouds. We propose to jointly learn coefficients and prototypes in parallel which can be combined to obtain the instance predictions. The coefficients are computed using an overcomplete set of sampled points with a novel multi-scale module, dubbed dilated point inception. As the set of obtained instance mask predictions is overcomplete, we employ a non-maximum suppression algorithm to retrieve the final predictions. This approach allows to omit the time-expensive clustering step and leads to a more stable inference time. The proposed method is not only 28% faster than the state-of-the-art, it also exhibits the lowest standard deviation. Our experiments have shown that the standard deviation of the inference time is only 1.0% of the total time while it ranges between 10.8 and 53.1% for the state-of-the-art methods. Lastly, our method outperforms the state-of-the-art both on S3DIS-blocks (4.9% in mRec on Fold-5) and PartNet (2.0% on average in mAP).
GINTRIP: Interpretable Temporal Graph Regression using Information bottleneck and Prototype-based method
Sep 17, 2024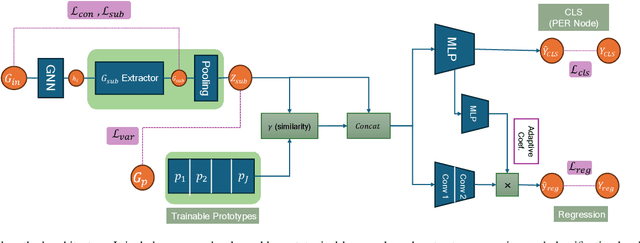
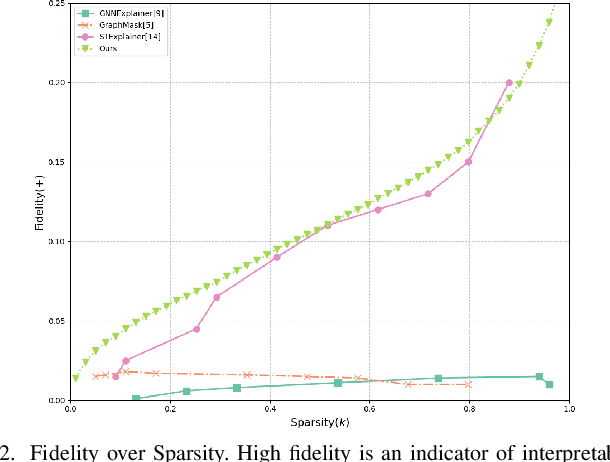
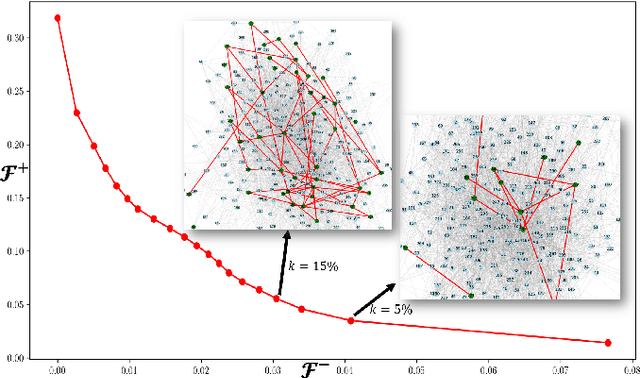

Deep neural networks (DNNs) have demonstrated remarkable performance across various domains, yet their application to temporal graph regression tasks faces significant challenges regarding interpretability. This critical issue, rooted in the inherent complexity of both DNNs and underlying spatio-temporal patterns in the graph, calls for innovative solutions. While interpretability concerns in Graph Neural Networks (GNNs) mirror those of DNNs, to the best of our knowledge, no notable work has addressed the interpretability of temporal GNNs using a combination of Information Bottleneck (IB) principles and prototype-based methods. Our research introduces a novel approach that uniquely integrates these techniques to enhance the interpretability of temporal graph regression models. The key contributions of our work are threefold: We introduce the \underline{G}raph \underline{IN}terpretability in \underline{T}emporal \underline{R}egression task using \underline{I}nformation bottleneck and \underline{P}rototype (GINTRIP) framework, the first combined application of IB and prototype-based methods for interpretable temporal graph tasks. We derive a novel theoretical bound on mutual information (MI), extending the applicability of IB principles to graph regression tasks. We incorporate an unsupervised auxiliary classification head, fostering multi-task learning and diverse concept representation, which enhances the model bottleneck's interpretability. Our model is evaluated on real-world traffic datasets, outperforming existing methods in both forecasting accuracy and interpretability-related metrics.
Efficient and Scalable Point Cloud Generation with Sparse Point-Voxel Diffusion Models
Aug 12, 2024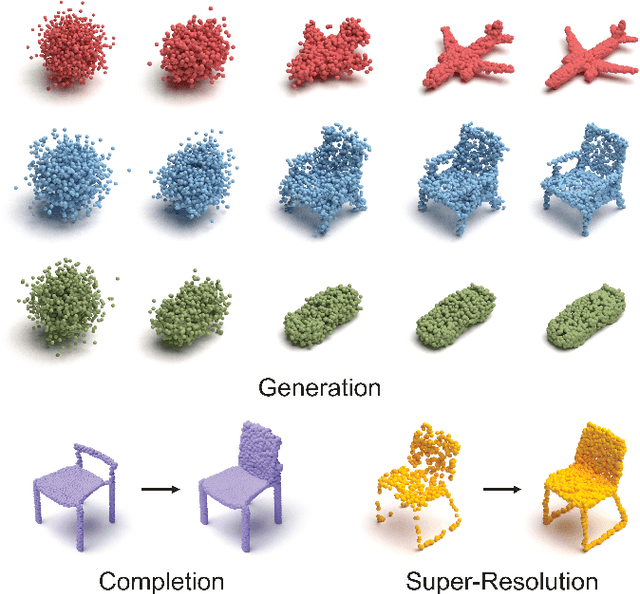
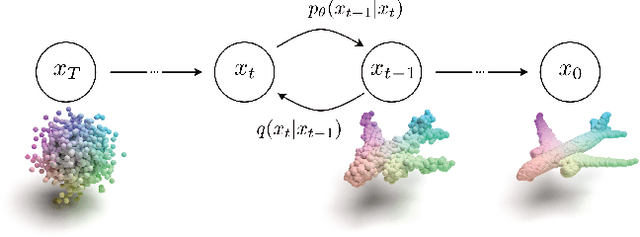
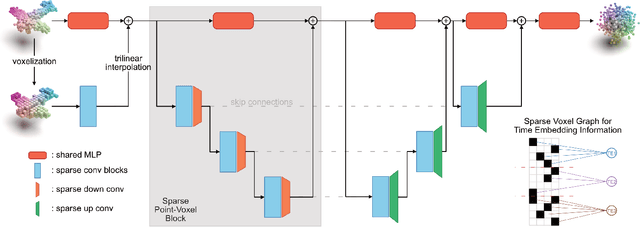
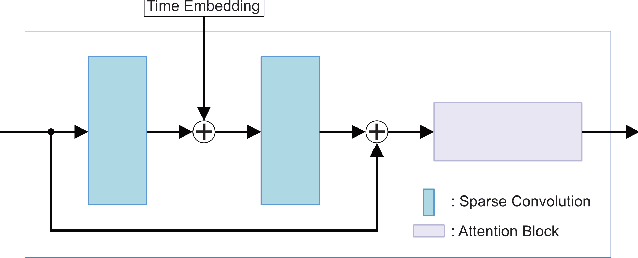
We propose a novel point cloud U-Net diffusion architecture for 3D generative modeling capable of generating high-quality and diverse 3D shapes while maintaining fast generation times. Our network employs a dual-branch architecture, combining the high-resolution representations of points with the computational efficiency of sparse voxels. Our fastest variant outperforms all non-diffusion generative approaches on unconditional shape generation, the most popular benchmark for evaluating point cloud generative models, while our largest model achieves state-of-the-art results among diffusion methods, with a runtime approximately 70% of the previously state-of-the-art PVD. Beyond unconditional generation, we perform extensive evaluations, including conditional generation on all categories of ShapeNet, demonstrating the scalability of our model to larger datasets, and implicit generation which allows our network to produce high quality point clouds on fewer timesteps, further decreasing the generation time. Finally, we evaluate the architecture's performance in point cloud completion and super-resolution. Our model excels in all tasks, establishing it as a state-of-the-art diffusion U-Net for point cloud generative modeling. The code is publicly available at https://github.com/JohnRomanelis/SPVD.git.
LAM3D: Leveraging Attention for Monocular 3D Object Detection
Aug 03, 2024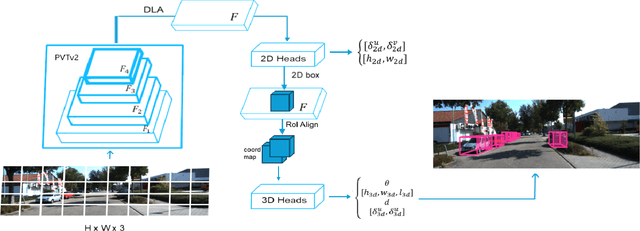



Since the introduction of the self-attention mechanism and the adoption of the Transformer architecture for Computer Vision tasks, the Vision Transformer-based architectures gained a lot of popularity in the field, being used for tasks such as image classification, object detection and image segmentation. However, efficiently leveraging the attention mechanism in vision transformers for the Monocular 3D Object Detection task remains an open question. In this paper, we present LAM3D, a framework that Leverages self-Attention mechanism for Monocular 3D object Detection. To do so, the proposed method is built upon a Pyramid Vision Transformer v2 (PVTv2) as feature extraction backbone and 2D/3D detection machinery. We evaluate the proposed method on the KITTI 3D Object Detection Benchmark, proving the applicability of the proposed solution in the autonomous driving domain and outperforming reference methods. Moreover, due to the usage of self-attention, LAM3D is able to systematically outperform the equivalent architecture that does not employ self-attention.
Improved Block Merging for 3D Point Cloud Instance Segmentation
Jul 09, 2024

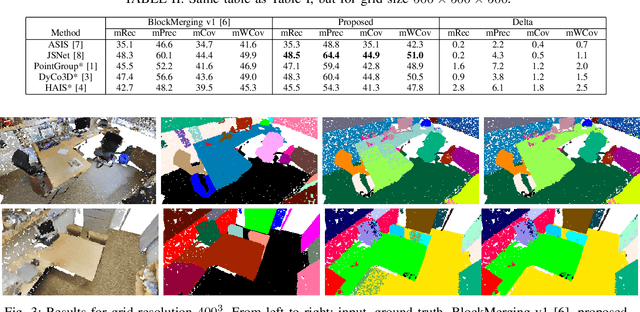

This paper proposes a novel block merging algorithm suitable for any block-based 3D instance segmentation technique. The proposed work improves over the state-of-the-art by allowing wrongly labelled points of already processed blocks to be corrected through label propagation. By doing so, instance overlap between blocks is not anymore necessary to produce the desirable results, which is the main limitation of the current art. Our experiments show that the proposed block merging algorithm significantly and consistently improves the obtained accuracy for all evaluation metrics employed in literature, regardless of the underlying network architecture.
* Published at 2023 24th International Conference on Digital Signal Processing (DSP)