 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAM3D: Leveraging Attention for Monocular 3D Object Detection
Paper and Code
Aug 03, 2024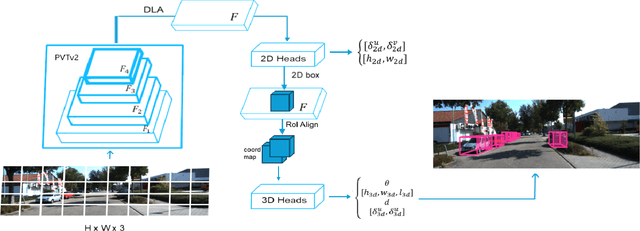



Since the introduction of the self-attention mechanism and the adoption of the Transformer architecture for Computer Vision tasks, the Vision Transformer-based architectures gained a lot of popularity in the field, being used for tasks such as image classification, object detection and image segmentation. However, efficiently leveraging the attention mechanism in vision transformers for the Monocular 3D Object Detection task remains an open question. In this paper, we present LAM3D, a framework that Leverages self-Attention mechanism for Monocular 3D object Detection. To do so, the proposed method is built upon a Pyramid Vision Transformer v2 (PVTv2) as feature extraction backbone and 2D/3D detection machinery. We evaluate the proposed method on the KITTI 3D Object Detection Benchmark, proving the applicability of the proposed solution in the autonomous driving domain and outperforming reference methods. Moreover, due to the usage of self-attention, LAM3D is able to systematically outperform the equivalent architecture that does not employ self-attention.