 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGINTRIP: Interpretable Temporal Graph Regression using Information bottleneck and Prototype-based method
Sep 17, 2024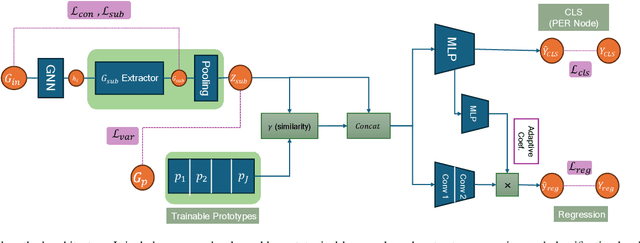
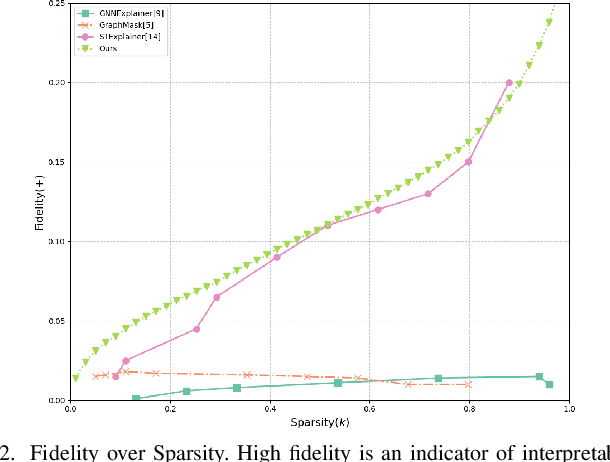
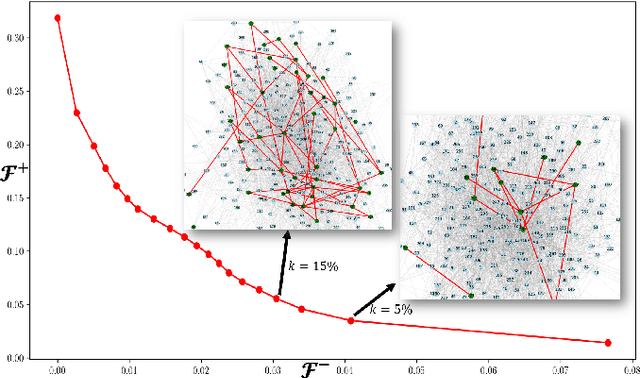

Deep neural networks (DNNs) have demonstrated remarkable performance across various domains, yet their application to temporal graph regression tasks faces significant challenges regarding interpretability. This critical issue, rooted in the inherent complexity of both DNNs and underlying spatio-temporal patterns in the graph, calls for innovative solutions. While interpretability concerns in Graph Neural Networks (GNNs) mirror those of DNNs, to the best of our knowledge, no notable work has addressed the interpretability of temporal GNNs using a combination of Information Bottleneck (IB) principles and prototype-based methods. Our research introduces a novel approach that uniquely integrates these techniques to enhance the interpretability of temporal graph regression models. The key contributions of our work are threefold: We introduce the \underline{G}raph \underline{IN}terpretability in \underline{T}emporal \underline{R}egression task using \underline{I}nformation bottleneck and \underline{P}rototype (GINTRIP) framework, the first combined application of IB and prototype-based methods for interpretable temporal graph tasks. We derive a novel theoretical bound on mutual information (MI), extending the applicability of IB principles to graph regression tasks. We incorporate an unsupervised auxiliary classification head, fostering multi-task learning and diverse concept representation, which enhances the model bottleneck's interpretability. Our model is evaluated on real-world traffic datasets, outperforming existing methods in both forecasting accuracy and interpretability-related metrics.
Classification of Breast Cancer Histopathology Images using a Modified Supervised Contrastive Learning Method
May 06, 2024



Deep neural networks have reached remarkable achievements in medical image processing tasks, specifically classifying and detecting various diseases. However, when confronted with limited data, these networks face a critical vulnerability, often succumbing to overfitting by excessively memorizing the limited information available. This work addresses the challenge mentioned above by improving the supervised contrastive learning method to reduce the impact of false positives. Unlike most existing methods that rely predominantly on fully supervised learning, our approach leverages the advantages of self-supervised learning in conjunction with employing the available labeled data. We evaluate our method on the BreakHis dataset, which consists of breast cancer histopathology images, and demonstrate an increase in classification accuracy by 1.45% at the image level and 1.42% at the patient level compared to the state-of-the-art method. This improvement corresponds to 93.63% absolute accuracy, highlighting our approach's effectiveness in leveraging data properties to learn more appropriate representation space.
Unsupervised Image Segmentation by Mutual Information Maximization and Adversarial Regularization
Jul 01, 2021



Semantic segmentation is one of the basic, yet essential scene understanding tasks for an autonomous agent. The recent developments in supervised machine learning and neural networks have enjoyed great success in enhancing the performance of the state-of-the-art techniques for this task. However, their superior performance is highly reliant on the availability of a large-scale annotated dataset. In this paper, we propose a novel fully unsupervised semantic segmentation method, the so-called Information Maximization and Adversarial Regularization Segmentation (InMARS). Inspired by human perception which parses a scene into perceptual groups, rather than analyzing each pixel individually, our proposed approach first partitions an input image into meaningful regions (also known as superpixels). Next, it utilizes Mutual-Information-Maximization followed by an adversarial training strategy to cluster these regions into semantically meaningful classes. To customize an adversarial training scheme for the problem, we incorporate adversarial pixel noise along with spatial perturbations to impose photometrical and geometrical invariance on the deep neural network. Our experiments demonstrate that our method achieves the state-of-the-art performance on two commonly used unsupervised semantic segmentation datasets, COCO-Stuff, and Potsdam.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021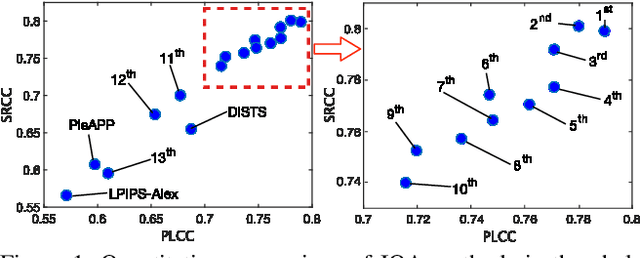
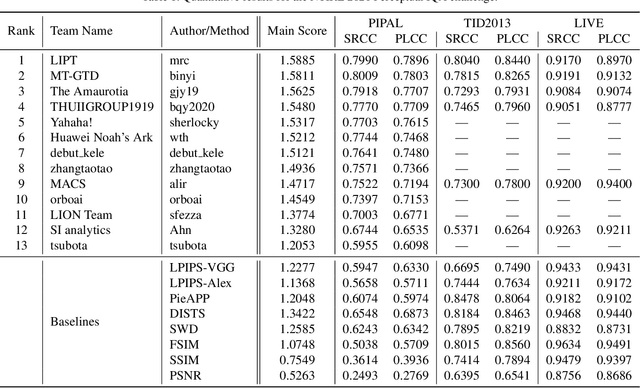

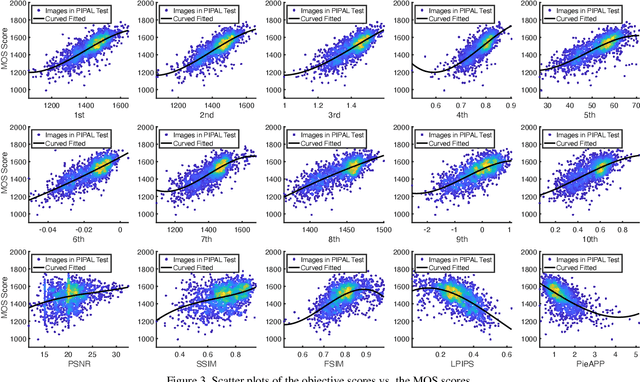
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
(ASNA) An Attention-based Siamese-Difference Neural Network with Surrogate Ranking Loss function for Perceptual Image Quality Assessment
May 06, 2021



Recently, deep convolutional neural networks (DCNN) that leverage the adversarial training framework for image restoration and enhancement have significantly improved the processed images' sharpness. Surprisingly, although these DCNNs produced crispier images than other methods visually, they may get a lower quality score when popular measures are employed for evaluating them. Therefore it is necessary to develop a quantitative metric to reflect their performances, which is well-aligned with the perceived quality of an image. Famous quantitative metrics such as Peak signal-to-noise ratio (PSNR), The structural similarity index measure (SSIM), and Perceptual Index (PI) are not well-correlated with the mean opinion score (MOS) for an image, especially for the neural networks trained with adversarial loss functions. This paper has proposed a convolutional neural network using an extension architecture of the traditional Siamese network so-called Siamese-Difference neural network. We have equipped this architecture with the spatial and channel-wise attention mechanism to increase our method's performance. Finally, we employed an auxiliary loss function to train our model. The suggested additional cost function surrogates ranking loss to increase Spearman's rank correlation coefficient while it is differentiable concerning the neural network parameters. Our method achieved superior performance in \textbf{\textit{NTIRE 2021 Perceptual Image Quality Assessment}} Challenge. The implementations of our proposed method are publicly available.