 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESSCAL3D++: Joint Acquisition and Semantic Segmentation of 3D Point Clouds
Oct 03, 2024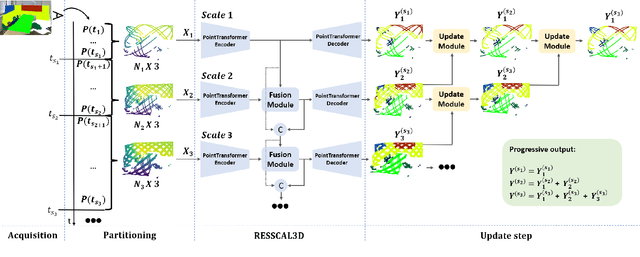



3D scene understanding is crucial for facilitating seamless interaction between digital devices and the physical world. Real-time capturing and processing of the 3D scene are essential for achieving this seamless integration. While existing approaches typically separate acquisition and processing for each frame, the advent of resolution-scalable 3D sensors offers an opportunity to overcome this paradigm and fully leverage the otherwise wasted acquisition time to initiate processing. In this study, we introduce VX-S3DIS, a novel point cloud dataset accurately simulating the behavior of a resolution-scalable 3D sensor. Additionally, we present RESSCAL3D++, an important improvement over our prior work, RESSCAL3D, by incorporating an update module and processing strategy. By applying our method to the new dataset, we practically demonstrate the potential of joint acquisition and semantic segmentation of 3D point clouds. Our resolution-scalable approach significantly reduces scalability costs from 2% to just 0.2% in mIoU while achieving impressive speed-ups of 15.6 to 63.9% compared to the non-scalable baseline. Furthermore, our scalable approach enables early predictions, with the first one occurring after only 7% of the total inference time of the baseline. The new VX-S3DIS dataset is available at https://github.com/remcoroyen/vx-s3dis.
ProtoSeg: A Prototype-Based Point Cloud Instance Segmentation Method
Oct 03, 2024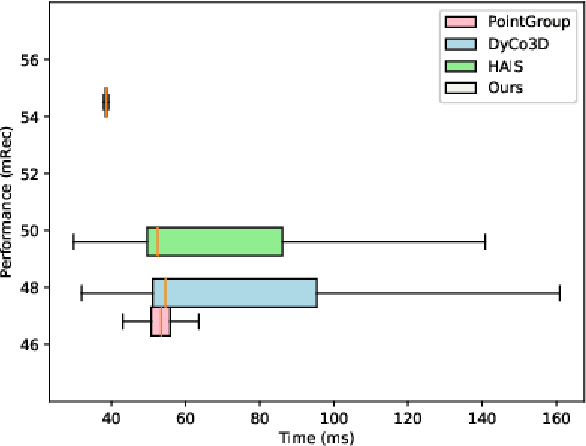
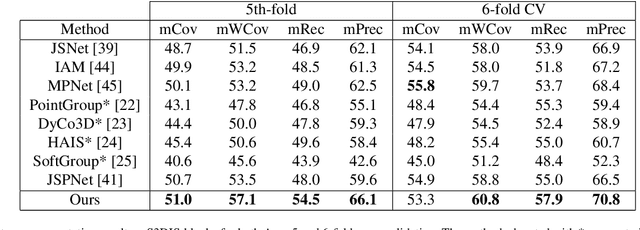
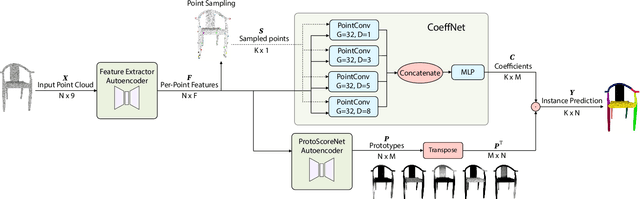
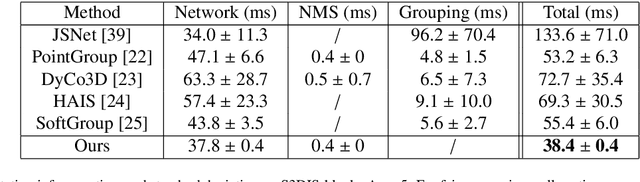
3D instance segmentation is crucial for obtaining an understanding of a point cloud scene. This paper presents a novel neural network architecture for performing instance segmentation on 3D point clouds. We propose to jointly learn coefficients and prototypes in parallel which can be combined to obtain the instance predictions. The coefficients are computed using an overcomplete set of sampled points with a novel multi-scale module, dubbed dilated point inception. As the set of obtained instance mask predictions is overcomplete, we employ a non-maximum suppression algorithm to retrieve the final predictions. This approach allows to omit the time-expensive clustering step and leads to a more stable inference time. The proposed method is not only 28% faster than the state-of-the-art, it also exhibits the lowest standard deviation. Our experiments have shown that the standard deviation of the inference time is only 1.0% of the total time while it ranges between 10.8 and 53.1% for the state-of-the-art methods. Lastly, our method outperforms the state-of-the-art both on S3DIS-blocks (4.9% in mRec on Fold-5) and PartNet (2.0% on average in mAP).
Joint prototype and coefficient prediction for 3D instance segmentation
Jul 09, 2024



3D instance segmentation is crucial for applications demanding comprehensive 3D scene understanding. In this paper, we introduce a novel method that simultaneously learns coefficients and prototypes. Employing an overcomplete sampling strategy, our method produces an overcomplete set of instance predictions, from which the optimal ones are selected through a Non-Maximum Suppression (NMS) algorithm during inference. The obtained prototypes are visualizable and interpretable. Our method demonstrates superior performance on S3DIS-blocks, consistently outperforming existing methods in mRec and mPrec. Moreover, it operates 32.9% faster than the state-of-the-art. Notably, with only 0.8% of the total inference time, our method exhibits an over 20-fold reduction in the variance of inference time compared to existing methods. These attributes render our method well-suited for practical applications requiring both rapid inference and high reliability.
* Published in Electronics Letters
Improved Block Merging for 3D Point Cloud Instance Segmentation
Jul 09, 2024

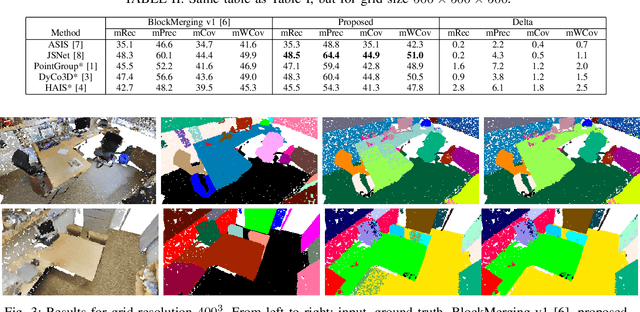

This paper proposes a novel block merging algorithm suitable for any block-based 3D instance segmentation technique. The proposed work improves over the state-of-the-art by allowing wrongly labelled points of already processed blocks to be corrected through label propagation. By doing so, instance overlap between blocks is not anymore necessary to produce the desirable results, which is the main limitation of the current art. Our experiments show that the proposed block merging algorithm significantly and consistently improves the obtained accuracy for all evaluation metrics employed in literature, regardless of the underlying network architecture.
* Published at 2023 24th International Conference on Digital Signal Processing (DSP)
RT-GS2: Real-Time Generalizable Semantic Segmentation for 3D Gaussian Representations of Radiance Fields
May 28, 2024
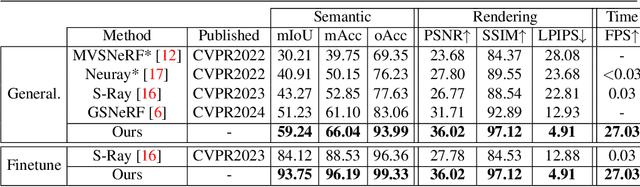
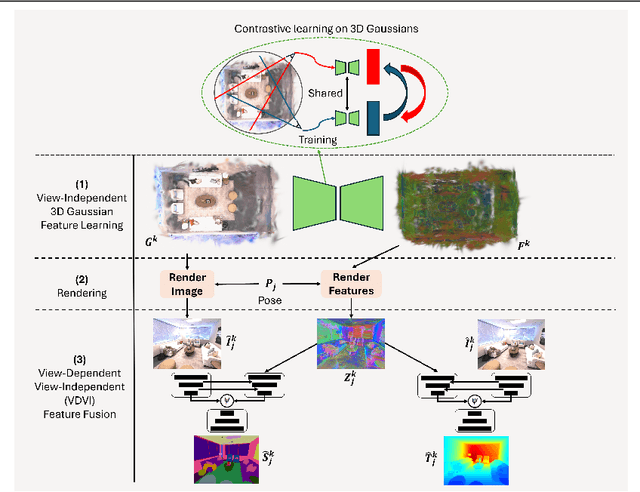
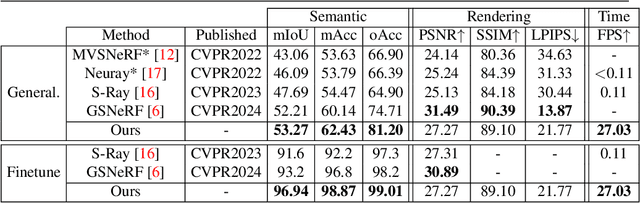
Gaussian Splatting has revolutionized the world of novel view synthesis by achieving high rendering performance in real-time. Recently, studies have focused on enriching these 3D representations with semantic information for downstream tasks. In this paper, we introduce RT-GS2, the first generalizable semantic segmentation method employing Gaussian Splatting. While existing Gaussian Splatting-based approaches rely on scene-specific training, RT-GS2 demonstrates the ability to generalize to unseen scenes. Our method adopts a new approach by first extracting view-independent 3D Gaussian features in a self-supervised manner, followed by a novel View-Dependent / View-Independent (VDVI) feature fusion to enhance semantic consistency over different views. Extensive experimentation on three different datasets showcases RT-GS2's superiority over the state-of-the-art methods in semantic segmentation quality, exemplified by a 8.01% increase in mIoU on the Replica dataset. Moreover, our method achieves real-time performance of 27.03 FPS, marking an astonishing 901 times speedup compared to existing approaches. This work represents a significant advancement in the field by introducing, to the best of our knowledge, the first real-time generalizable semantic segmentation method for 3D Gaussian representations of radiance fields.
RESSCAL3D: Resolution Scalable 3D Semantic Segmentation of Point Clouds
Apr 10, 2024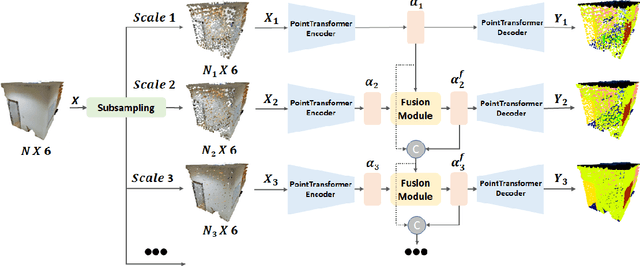
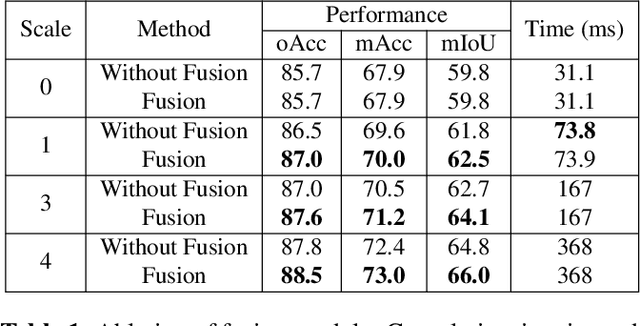

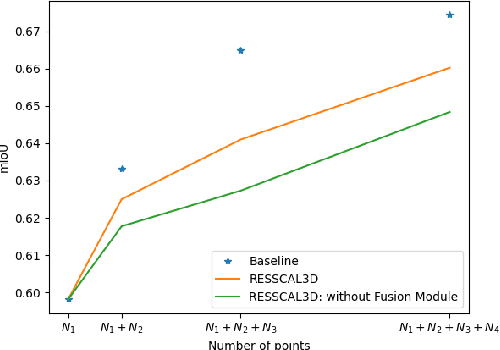
While deep learning-based methods have demonstrated outstanding results in numerous domains, some important functionalities are missing. Resolution scalability is one of them. In this work, we introduce a novel architecture, dubbed RESSCAL3D, providing resolution-scalable 3D semantic segmentation of point clouds. In contrast to existing works, the proposed method does not require the whole point cloud to be available to start inference. Once a low-resolution version of the input point cloud is available, first semantic predictions can be generated in an extremely fast manner. This enables early decision-making in subsequent processing steps. As additional points become available, these are processed in parallel. To improve performance, features from previously computed scales are employed as prior knowledge at the current scale. Our experiments show that RESSCAL3D is 31-62% faster than the non-scalable baseline while keeping a limited impact on performance. To the best of our knowledge, the proposed method is the first to propose a resolution-scalable approach for 3D semantic segmentation of point clouds based on deep learning.