 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Deep Multimodal Image Super-Resolution
Sep 07, 2020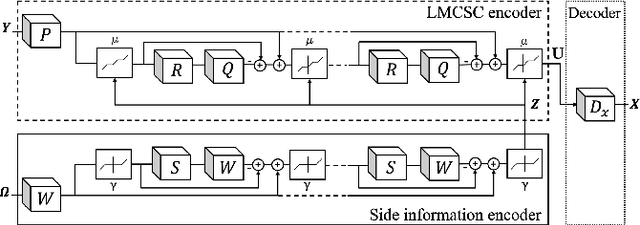

Multimodal image super-resolution (SR) is the reconstruction of a high resolution image given a low-resolution observation with the aid of another image modality. While existing deep multimodal models do not incorporate domain knowledge about image SR, we present a multimodal deep network design that integrates coupled sparse priors and allows the effective fusion of information from another modality into the reconstruction process. Our method is inspired by a novel iterative algorithm for coupled convolutional sparse coding, resulting in an interpretable network by design. We apply our model to the super-resolution of near-infrared image guided by RGB images. Experimental results show that our model outperforms state-of-the-art methods.
Multimodal Deep Unfolding for Guided Image Super-Resolution
Jan 21, 2020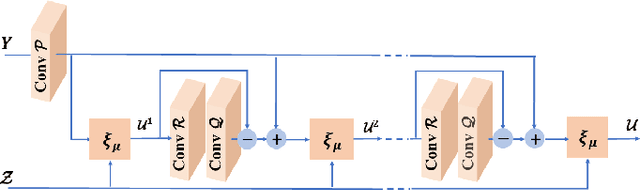
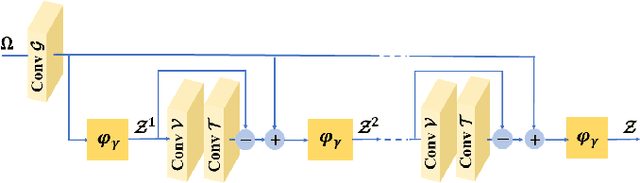
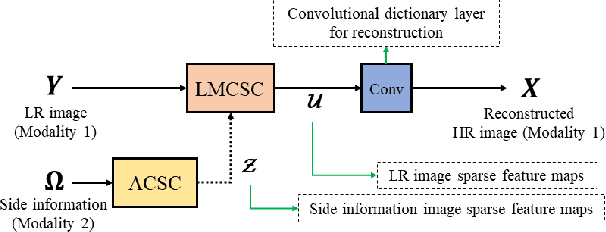
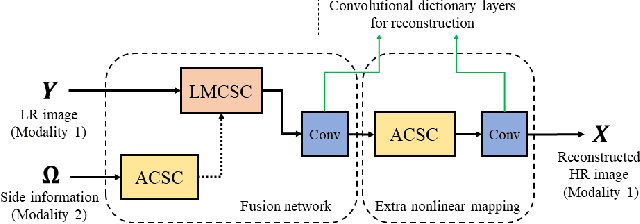
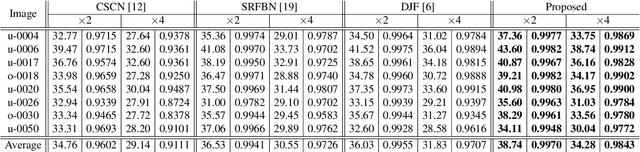
The reconstruction of a high resolution image given a low resolution observation is an ill-posed inverse problem in imaging. Deep learning methods rely on training data to learn an end-to-end mapping from a low-resolution input to a high-resolution output. Unlike existing deep multimodal models that do not incorporate domain knowledge about the problem, we propose a multimodal deep learning design that incorporates sparse priors and allows the effective integration of information from another image modality into the network architecture. Our solution relies on a novel deep unfolding operator, performing steps similar to an iterative algorithm for convolutional sparse coding with side information; therefore, the proposed neural network is interpretable by design. The deep unfolding architecture is used as a core component of a multimodal framework for guided image super-resolution. An alternative multimodal design is investigated by employing residual learning to improve the training efficiency. The presented multimodal approach is applied to super-resolution of near-infrared and multi-spectral images as well as depth upsampling using RGB images as side information. Experimental results show that our model outperforms state-of-the-art methods.
Multimodal Image Super-resolution via Deep Unfolding with Side Information
Oct 18, 2019
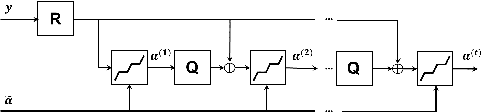
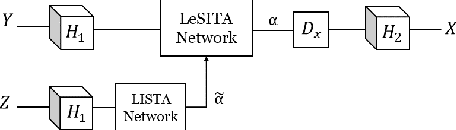
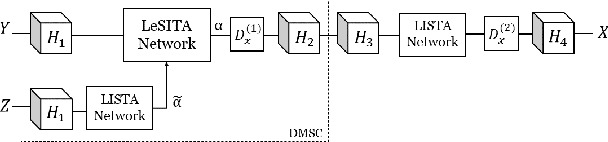
Deep learning methods have been successfully applied to various computer vision tasks. However, existing neural network architectures do not per se incorporate domain knowledge about the addressed problem, thus, understanding what the model has learned is an open research topic. In this paper, we rely on the unfolding of an iterative algorithm for sparse approximation with side information, and design a deep learning architecture for multimodal image super-resolution that incorporates sparse priors and effectively utilizes information from another image modality. We develop two deep models performing reconstruction of a high-resolution image of a target image modality from its low-resolution variant with the aid of a high-resolution image from a second modality. We apply the proposed models to super-resolve near-infrared images using as side information high-resolution RGB\ images. Experimental results demonstrate the superior performance of the proposed models against state-of-the-art methods including unimodal and multimodal approaches.
Deep Coupled-Representation Learning for Sparse Linear Inverse Problems with Side Information
Jul 04, 2019
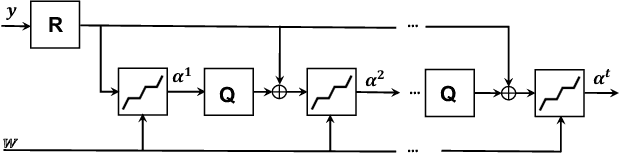


In linear inverse problems, the goal is to recover a target signal from undersampled, incomplete or noisy linear measurements. Typically, the recovery relies on complex numerical optimization methods; recent approaches perform an unfolding of a numerical algorithm into a neural network form, resulting in a substantial reduction of the computational complexity. In this paper, we consider the recovery of a target signal with the aid of a correlated signal, the so-called side information (SI), and propose a deep unfolding model that incorporates SI. The proposed model is used to learn coupled representations of correlated signals from different modalities, enabling the recovery of multimodal data at a low computational cost. As such, our work introduces the first deep unfolding method with SI, which actually comes from a different modality. We apply our model to reconstruct near-infrared images from undersampled measurements given RGB images as SI. Experimental results demonstrate the superior performance of the proposed framework against single-modal deep learning methods that do not use SI, multimodal deep learning designs, and optimization algorithms.
Matrix Factorization via Deep Learning
Dec 04, 2018

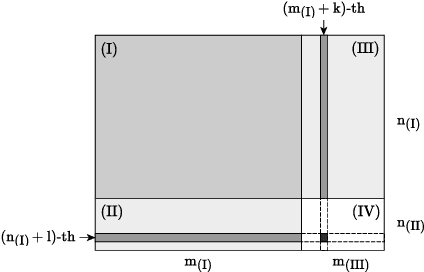
Matrix completion is one of the key problems in signal processing and machine learning. In recent years, deep-learning-based models have achieved state-of-the-art results in matrix completion. Nevertheless, they suffer from two drawbacks: (i) they can not be extended easily to rows or columns unseen during training; and (ii) their results are often degraded in case discrete predictions are required. This paper addresses these two drawbacks by presenting a deep matrix factorization model and a generic method to allow joint training of the factorization model and the discretization operator. Experiments on a real movie rating dataset show the efficacy of the proposed models.
Matrix Completion With Variational Graph Autoencoders: Application in Hyperlocal Air Quality Inference
Nov 05, 2018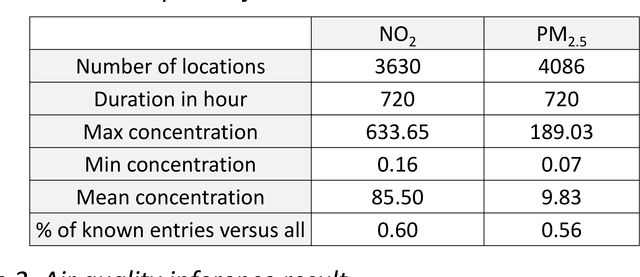
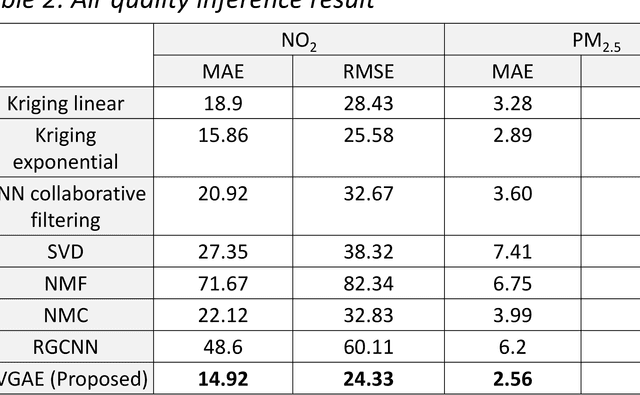
Inferring air quality from a limited number of observations is an essential task for monitoring and controlling air pollution. Existing inference methods typically use low spatial resolution data collected by fixed monitoring stations and infer the concentration of air pollutants using additional types of data, e.g., meteorological and traffic information. In this work, we focus on street-level air quality inference by utilizing data collected by mobile stations. We formulate air quality inference in this setting as a graph-based matrix completion problem and propose a novel variational model based on graph convolutional autoencoders. Our model captures effectively the spatio-temporal correlation of the measurements and does not depend on the availability of additional information apart from the street-network topology. Experiments on a real air quality dataset, collected with mobile stations, shows that the proposed model outperforms state-of-the-art approaches.
Regularizing Autoencoder-Based Matrix Completion Models via Manifold Learning
Jul 04, 2018
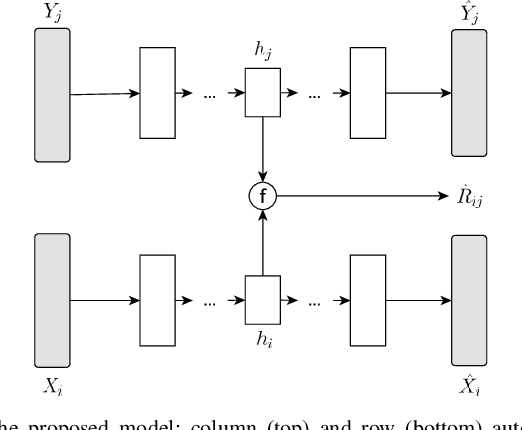


Autoencoders are popular among neural-network-based matrix completion models due to their ability to retrieve potential latent factors from the partially observed matrices. Nevertheless, when training data is scarce their performance is significantly degraded due to overfitting. In this paper, we mit- igate overfitting with a data-dependent regularization technique that relies on the principles of multi-task learning. Specifically, we propose an autoencoder-based matrix completion model that performs prediction of the unknown matrix values as a main task, and manifold learning as an auxiliary task. The latter acts as an inductive bias, leading to solutions that generalize better. The proposed model outperforms the existing autoencoder-based models designed for matrix completion, achieving high reconstruction accuracy in well-known datasets.
Extendable Neural Matrix Completion
May 13, 2018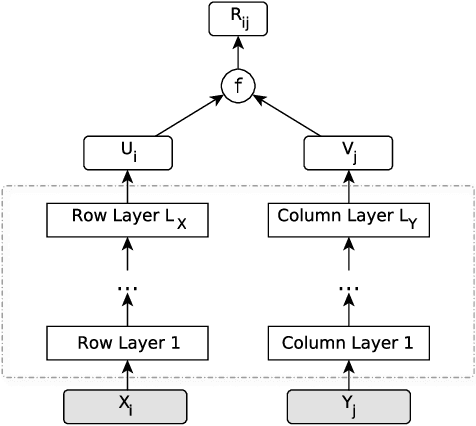
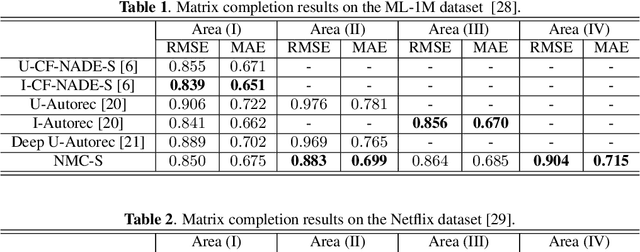

Matrix completion is one of the key problems in signal processing and machine learning, with applications ranging from image pro- cessing and data gathering to classification and recommender sys- tems. Recently, deep neural networks have been proposed as la- tent factor models for matrix completion and have achieved state- of-the-art performance. Nevertheless, a major problem with existing neural-network-based models is their limited capabilities to extend to samples unavailable at the training stage. In this paper, we propose a deep two-branch neural network model for matrix completion. The proposed model not only inherits the predictive power of neural net- works, but is also capable of extending to partially observed samples outside the training set, without the need of retraining or fine-tuning. Experimental studies on popular movie rating datasets prove the ef- fectiveness of our model compared to the state of the art, in terms of both accuracy and extendability.
Twitter User Geolocation using Deep Multiview Learning
May 11, 2018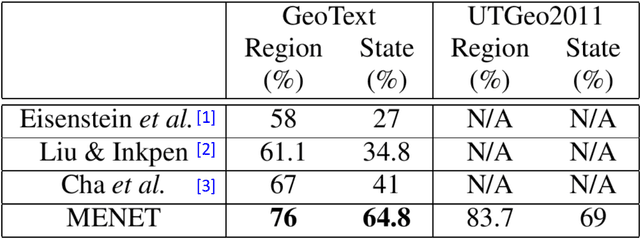
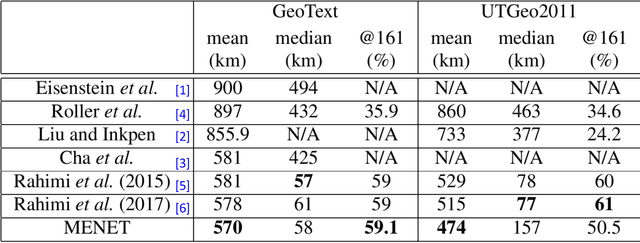
Predicting the geographical location of users on social networks like Twitter is an active research topic with plenty of methods proposed so far. Most of the existing work follows either a content-based or a network-based approach. The former is based on user-generated content while the latter exploits the structure of the network of users. In this paper, we propose a more generic approach, which incorporates not only both content-based and network-based features, but also other available information into a unified model. Our approach, named Multi-Entry Neural Network (MENET), leverages the latest advances in deep learning and multiview learning. A realization of MENET with textual, network and metadata features results in an effective method for Twitter user geolocation, achieving the state of the art on two well-known datasets.
Multiview Deep Learning for Predicting Twitter Users' Location
Dec 21, 2017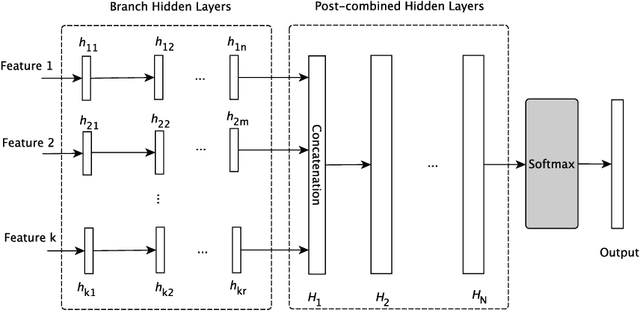

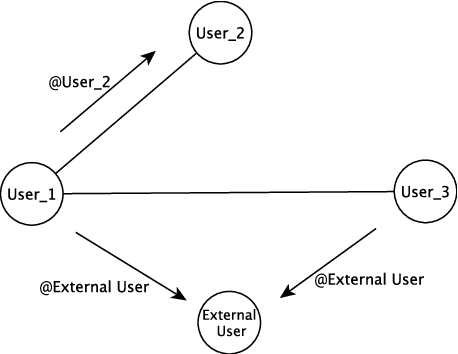
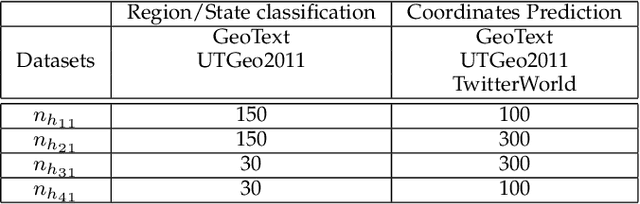
The problem of predicting the location of users on large social networks like Twitter has emerged from real-life applications such as social unrest detection and online marketing. Twitter user geolocation is a difficult and active research topic with a vast literature. Most of the proposed methods follow either a content-based or a network-based approach. The former exploits user-generated content while the latter utilizes the connection or interaction between Twitter users. In this paper, we introduce a novel method combining the strength of both approaches. Concretely, we propose a multi-entry neural network architecture named MENET leveraging the advances in deep learning and multiview learning. The generalizability of MENET enables the integration of multiple data representations. In the context of Twitter user geolocation, we realize MENET with textual, network, and metadata features. Considering the natural distribution of Twitter users across the concerned geographical area, we subdivide the surface of the earth into multi-scale cells and train MENET with the labels of the cells. We show that our method outperforms the state of the art by a large margin on three benchmark datasets.