 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Multigrid Memory For Computational Fluid Dynamics
Jun 24, 2023Turbulent flow simulation plays a crucial role in various applications, including aircraft and ship design, industrial process optimization, and weather prediction. In this paper, we propose an advanced data-driven method for simulating turbulent flow, representing a significant improvement over existing approaches. Our methodology combines the strengths of Video Prediction Transformer (VPTR) (Ye & Bilodeau, 2022) and Multigrid Architecture (MgConv, MgResnet) (Ke et al., 2017). VPTR excels in capturing complex spatiotemporal dependencies and handling large input data, making it a promising choice for turbulent flow prediction. Meanwhile, Multigrid Architecture utilizes multiple grids with different resolutions to capture the multiscale nature of turbulent flows, resulting in more accurate and efficient simulations. Through our experiments, we demonstrate the effectiveness of our proposed approach, named MGxTransformer, in accurately predicting velocity, temperature, and turbulence intensity for incompressible turbulent flows across various geometries and flow conditions. Our results exhibit superior accuracy compared to other baselines, while maintaining computational efficiency. Our implementation in PyTorch is available publicly at https://github.com/Combi2k2/MG-Turbulent-Flow
Semi-supervised learning for medical image classification using imbalanced training data
Aug 20, 2021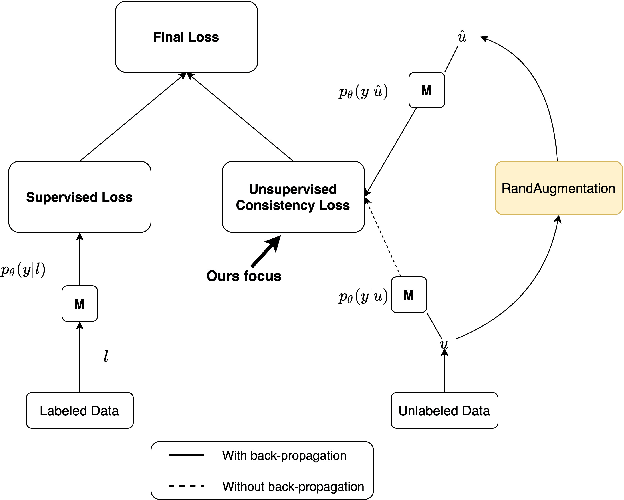
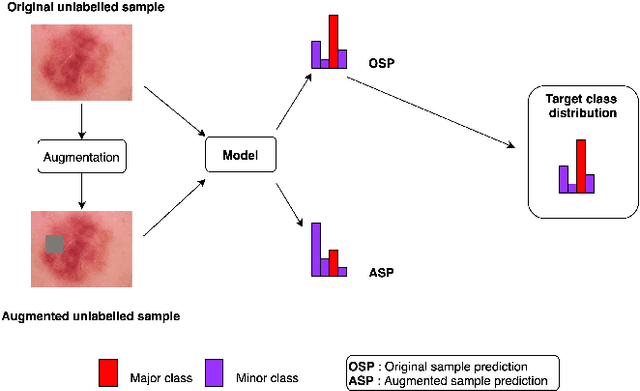
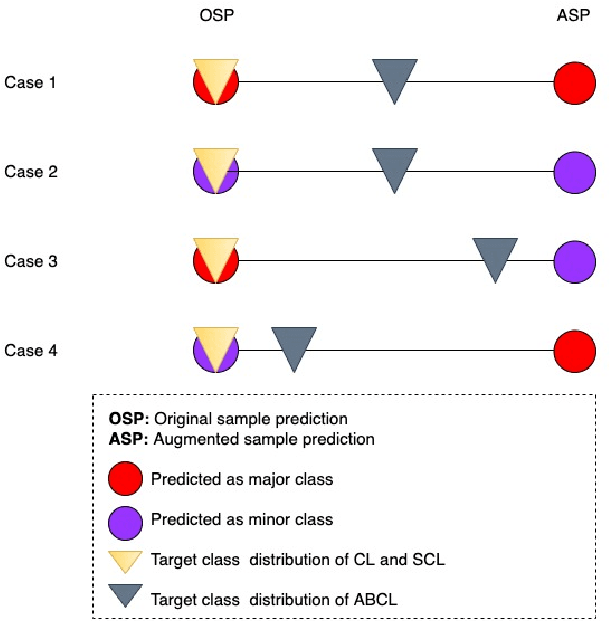
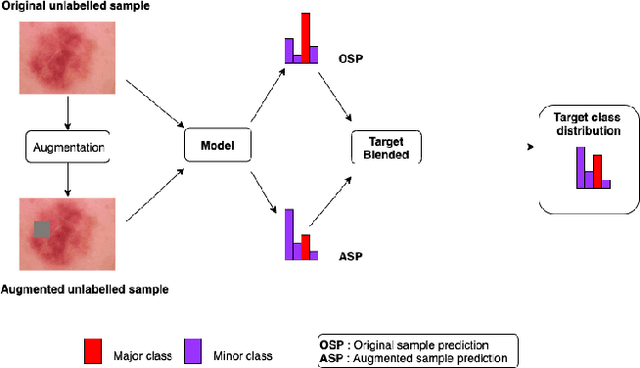
Medical image classification is often challenging for two reasons: a lack of labelled examples due to expensive and time-consuming annotation protocols, and imbalanced class labels due to the relative scarcity of disease-positive individuals in the wider population. Semi-supervised learning (SSL) methods exist for dealing with a lack of labels, but they generally do not address the problem of class imbalance. In this study we propose Adaptive Blended Consistency Loss (ABCL), a drop-in replacement for consistency loss in perturbation-based SSL methods. ABCL counteracts data skew by adaptively mixing the target class distribution of the consistency loss in accordance with class frequency. Our experiments with ABCL reveal improvements to unweighted average recall on two different imbalanced medical image classification datasets when compared with existing consistency losses that are not designed to counteract class imbalance.
Boosting Contrastive Self-Supervised Learning with False Negative Cancellation
Nov 23, 2020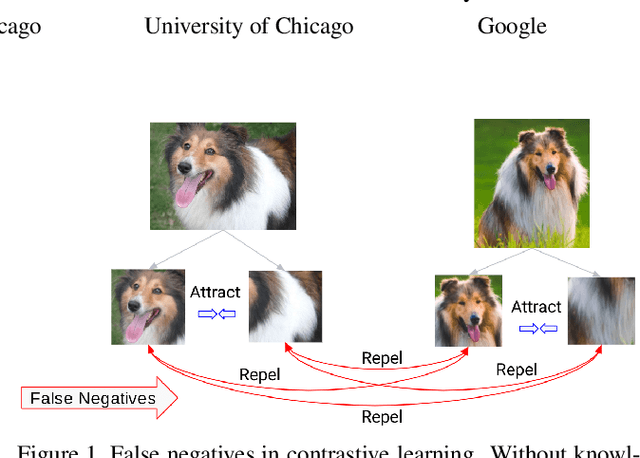

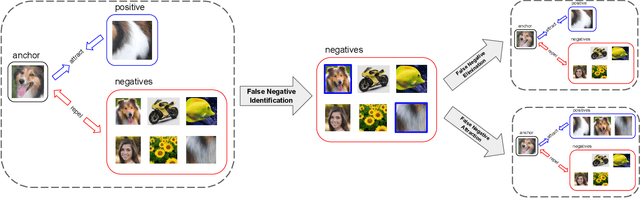

Self-supervised representation learning has witnessed significant leaps fueled by recent progress in Contrastive learning, which seeks to learn transformations that embed positive input pairs nearby, while pushing negative pairs far apart. While positive pairs can be generated reliably (e.g., as different views of the same image), it is difficult to accurately establish negative pairs, defined as samples from different images regardless of their semantic content or visual features. A fundamental problem in contrastive learning is mitigating the effects of false negatives. Contrasting false negatives induces two critical issues in representation learning: discarding semantic information and slow convergence. In this paper, we study this problem in detail and propose novel approaches to mitigate the effects of false negatives. The proposed methods exhibit consistent and significant improvements over existing contrastive learning-based models. They achieve new state-of-the-art performance on ImageNet evaluations, achieving 5.8% absolute improvement in top-1 accuracy over the previous state-of-the-art when finetuning with 1% labels, as well as transferring to downstream tasks.
Multigrid Neural Memory
Jun 13, 2019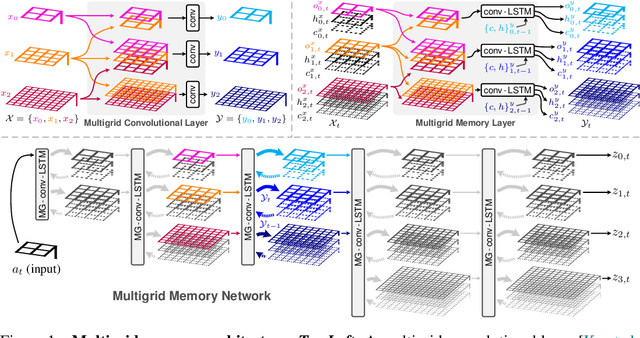
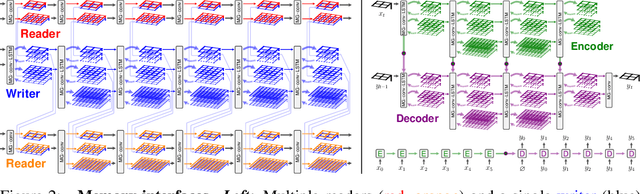

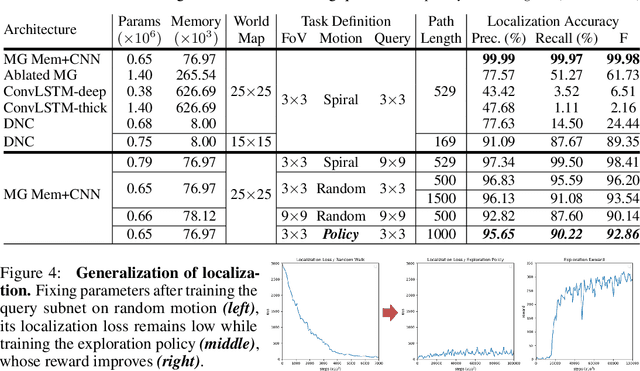
We introduce a novel architecture that integrates a large addressable memory space into the core functionality of a deep neural network. Our design distributes both memory addressing operations and storage capacity over many network layers. Distinct from strategies that connect neural networks to external memory banks, our approach co-locates memory with computation throughout the network structure. Mirroring recent architectural innovations in convolutional networks, we organize memory into a multiresolution hierarchy, whose internal connectivity enables learning of dynamic information routing strategies and data-dependent read/write operations. This multigrid spatial layout permits parameter-efficient scaling of memory size, allowing us to experiment with memories substantially larger than those in prior work. We demonstrate this capability on synthetic exploration and mapping tasks, where the network is able to self-organize and retain long-term memory for trajectories of thousands of time steps. On tasks decoupled from any notion of spatial geometry, such as sorting or associative recall, our design functions as a truly generic memory and yields results competitive with those of the recently proposed Differentiable Neural Computer.