 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dense Contrastive Learning with Dense Negative Pairs
Oct 11, 2022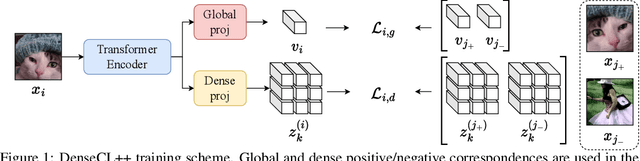
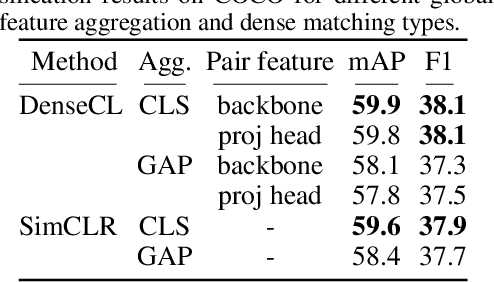
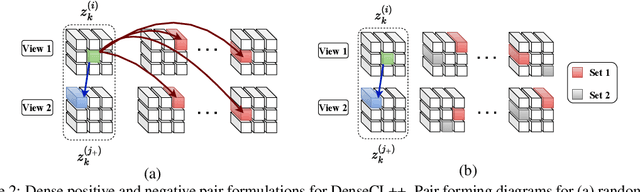
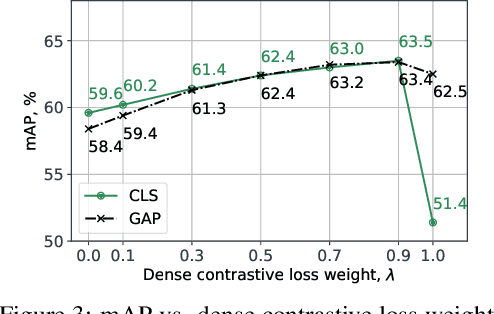
Many contrastive representation learning methods learn a single global representation of an entire image. However, dense contrastive representation learning methods such as DenseCL [19] can learn better representations for tasks requiring stronger spatial localization of features, such as multi-label classification, detection, and segmentation. In this work, we study how to improve the quality of the representations learned by DenseCL by modifying the training scheme and objective function, and propose DenseCL++. We also conduct several ablation studies to better understand the effects of: (i) various techniques to form dense negative pairs among augmentations of different images, (ii) cross-view dense negative and positive pairs, and (iii) an auxiliary reconstruction task. Our results show 3.5% and 4% mAP improvement over SimCLR [3] and DenseCL in COCO multi-label classification. In COCO and VOC segmentation tasks, we achieve 1.8% and 0.7% mIoU improvements over SimCLR, respectively.
A Study on Self-Supervised Object Detection Pretraining
Jul 09, 2022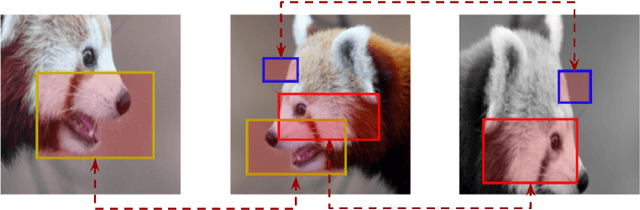
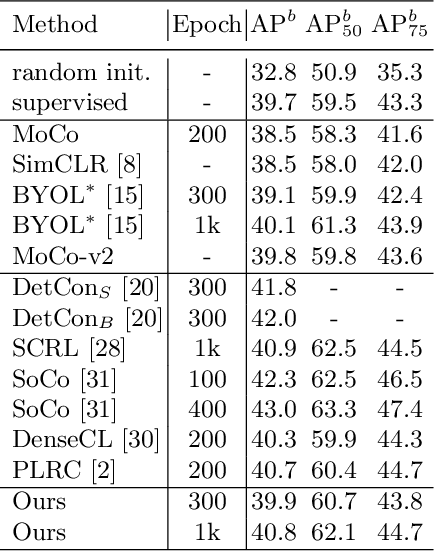
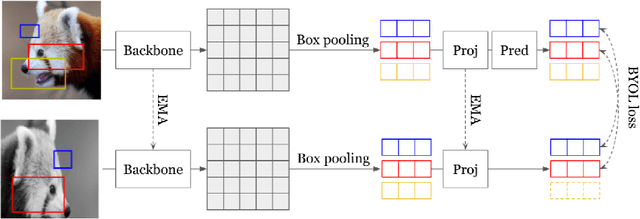
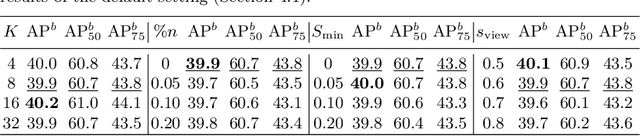
In this work, we study different approaches to self-supervised pretraining of object detection models. We first design a general framework to learn a spatially consistent dense representation from an image, by randomly sampling and projecting boxes to each augmented view and maximizing the similarity between corresponding box features. We study existing design choices in the literature, such as box generation, feature extraction strategies, and using multiple views inspired by its success on instance-level image representation learning techniques. Our results suggest that the method is robust to different choices of hyperparameters, and using multiple views is not as effective as shown for instance-level image representation learning. We also design two auxiliary tasks to predict boxes in one view from their features in the other view, by (1) predicting boxes from the sampled set by using a contrastive loss, and (2) predicting box coordinates using a transformer, which potentially benefits downstream object detection tasks. We found that these tasks do not lead to better object detection performance when finetuning the pretrained model on labeled data.
Boosting Contrastive Self-Supervised Learning with False Negative Cancellation
Nov 23, 2020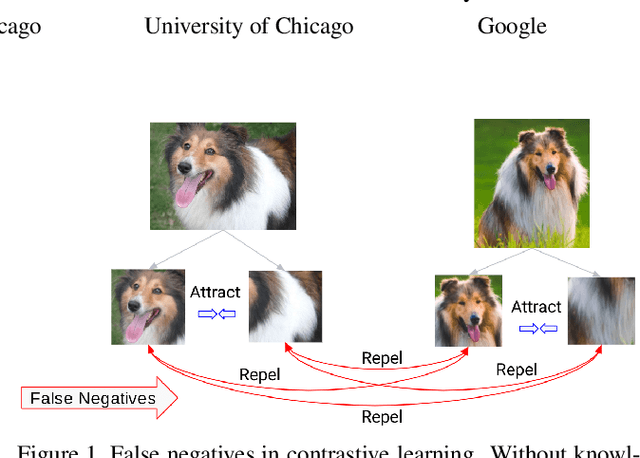

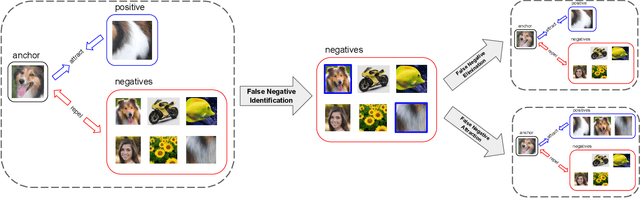

Self-supervised representation learning has witnessed significant leaps fueled by recent progress in Contrastive learning, which seeks to learn transformations that embed positive input pairs nearby, while pushing negative pairs far apart. While positive pairs can be generated reliably (e.g., as different views of the same image), it is difficult to accurately establish negative pairs, defined as samples from different images regardless of their semantic content or visual features. A fundamental problem in contrastive learning is mitigating the effects of false negatives. Contrasting false negatives induces two critical issues in representation learning: discarding semantic information and slow convergence. In this paper, we study this problem in detail and propose novel approaches to mitigate the effects of false negatives. The proposed methods exhibit consistent and significant improvements over existing contrastive learning-based models. They achieve new state-of-the-art performance on ImageNet evaluations, achieving 5.8% absolute improvement in top-1 accuracy over the previous state-of-the-art when finetuning with 1% labels, as well as transferring to downstream tasks.
3D Hand Pose Detection in Egocentric RGB-D Images
Nov 29, 2014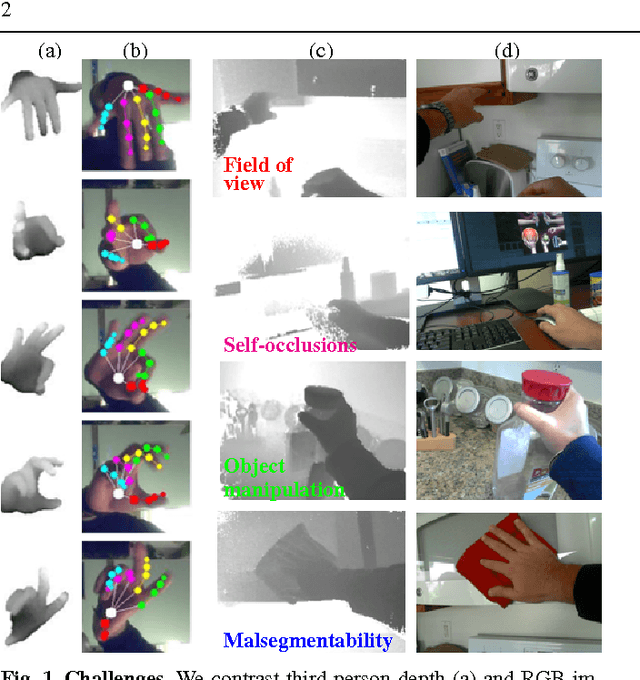
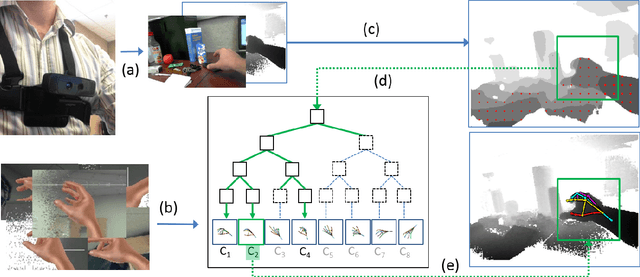
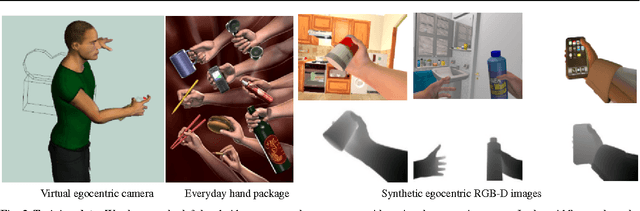
We focus on the task of everyday hand pose estimation from egocentric viewpoints. For this task, we show that depth sensors are particularly informative for extracting near-field interactions of the camera wearer with his/her environment. Despite the recent advances in full-body pose estimation using Kinect-like sensors, reliable monocular hand pose estimation in RGB-D images is still an unsolved problem. The problem is considerably exacerbated when analyzing hands performing daily activities from a first-person viewpoint, due to severe occlusions arising from object manipulations and a limited field-of-view. Our system addresses these difficulties by exploiting strong priors over viewpoint and pose in a discriminative tracking-by-detection framework. Our priors are operationalized through a photorealistic synthetic model of egocentric scenes, which is used to generate training data for learning depth-based pose classifiers. We evaluate our approach on an annotated dataset of real egocentric object manipulation scenes and compare to both commercial and academic approaches. Our method provides state-of-the-art performance for both hand detection and pose estimation in egocentric RGB-D images.