 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristic-Free Multi-Teacher Learning
Nov 19, 2024We introduce Teacher2Task, a novel framework for multi-teacher learning that eliminates the need for manual aggregation heuristics. Existing multi-teacher methods typically rely on such heuristics to combine predictions from multiple teachers, often resulting in sub-optimal aggregated labels and the propagation of aggregation errors. Teacher2Task addresses these limitations by introducing teacher-specific input tokens and reformulating the training process. Instead of relying on aggregated labels, the framework transforms the training data, consisting of ground truth labels and annotations from N teachers, into N+1 distinct tasks: N auxiliary tasks that predict the labeling styles of the N individual teachers, and one primary task that focuses on the ground truth labels. This approach, drawing upon principles from multiple learning paradigms, demonstrates strong empirical results across a range of architectures, modalities, and tasks.
A Study on Self-Supervised Object Detection Pretraining
Jul 09, 2022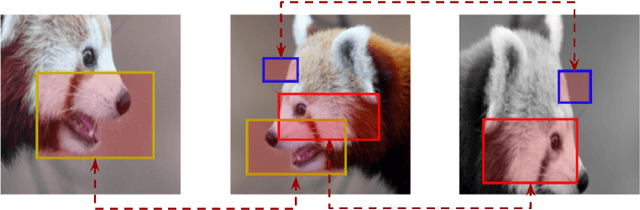
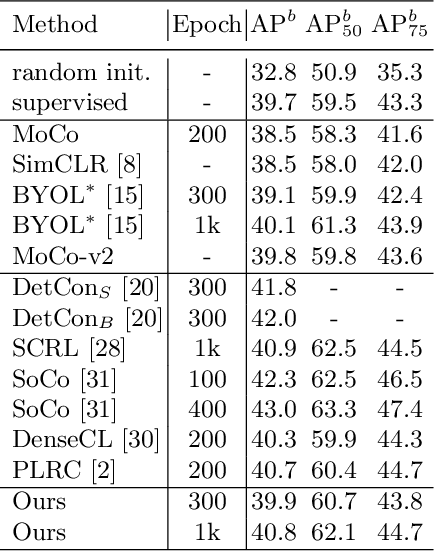
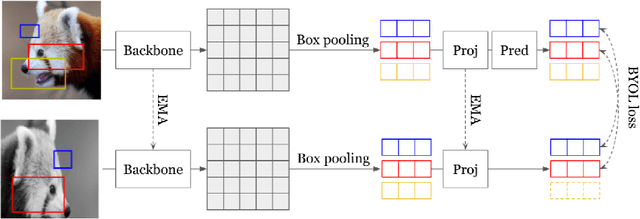
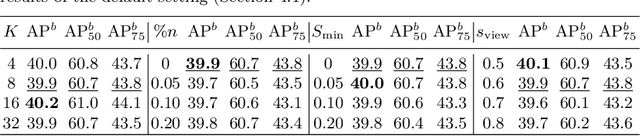
In this work, we study different approaches to self-supervised pretraining of object detection models. We first design a general framework to learn a spatially consistent dense representation from an image, by randomly sampling and projecting boxes to each augmented view and maximizing the similarity between corresponding box features. We study existing design choices in the literature, such as box generation, feature extraction strategies, and using multiple views inspired by its success on instance-level image representation learning techniques. Our results suggest that the method is robust to different choices of hyperparameters, and using multiple views is not as effective as shown for instance-level image representation learning. We also design two auxiliary tasks to predict boxes in one view from their features in the other view, by (1) predicting boxes from the sampled set by using a contrastive loss, and (2) predicting box coordinates using a transformer, which potentially benefits downstream object detection tasks. We found that these tasks do not lead to better object detection performance when finetuning the pretrained model on labeled data.