 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSR-NF: Neural Field Regularization by Static Restoration Priors for Dynamic Imaging
Mar 13, 2025



Dynamic imaging involves the reconstruction of a spatio-temporal object at all times using its undersampled measurements. In particular, in dynamic computed tomography (dCT), only a single projection at one view angle is available at a time, making the inverse problem very challenging. Moreover, ground-truth dynamic data is usually either unavailable or too scarce to be used for supervised learning techniques. To tackle this problem, we propose RSR-NF, which uses a neural field (NF) to represent the dynamic object and, using the Regularization-by-Denoising (RED) framework, incorporates an additional static deep spatial prior into a variational formulation via a learned restoration operator. We use an ADMM-based algorithm with variable splitting to efficiently optimize the variational objective. We compare RSR-NF to three alternatives: NF with only temporal regularization; a recent method combining a partially-separable low-rank representation with RED using a denoiser pretrained on static data; and a deep-image prior-based model. The first comparison demonstrates the reconstruction improvements achieved by combining the NF representation with static restoration priors, whereas the other two demonstrate the improvement over state-of-the art techniques for dCT.
A Pipeline for Segmenting and Structuring RGB-D Data for Robotics Applications
Oct 23, 2024
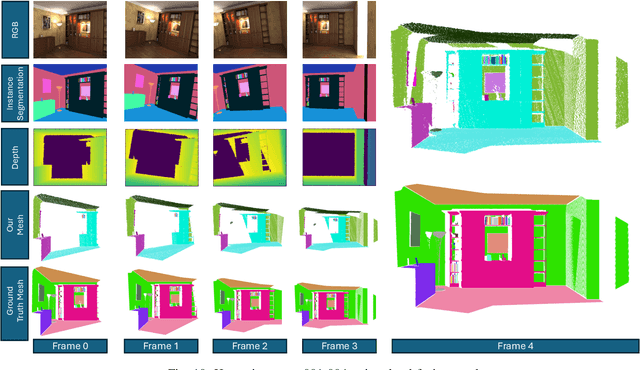


We introduce a novel pipeline for segmenting and structuring color and depth (RGB-D) data. Existing processing pipelines for RGB-D data have focused on extracting geometric information alone. This approach precludes the development of more advanced robotic navigation and manipulation algorithms, which benefit from a semantic understanding of their environment. Our pipeline can segment RGB-D data into accurate semantic masks. These masks are then used to fuse raw captured point clouds into semantically separated point clouds. We store this information using the Universal Scene Description (USD) file format, a format suitable for easy querying by downstream robotics algorithms, human-friendly visualization, and robotics simulation.
RED-PSM: Regularization by Denoising of Partially Separable Models for Dynamic Imaging
Apr 07, 2023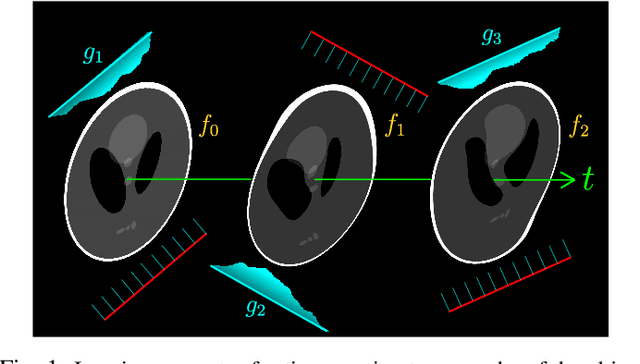
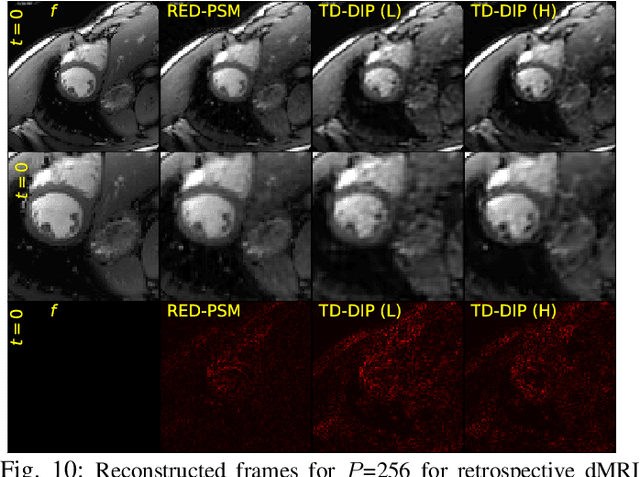
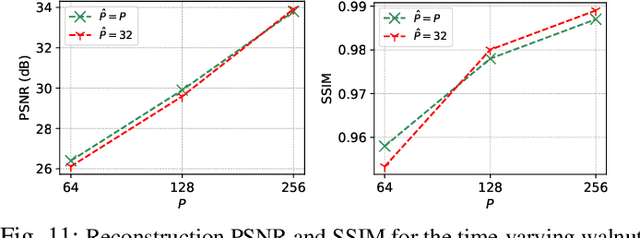
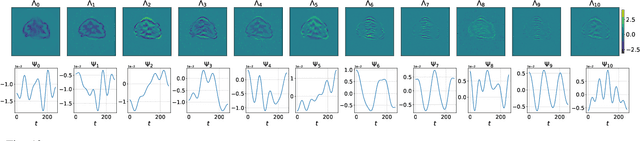
Dynamic imaging addresses the recovery of a time-varying 2D or 3D object at each time instant using its undersampled measurements. In particular, in the case of dynamic tomography, only a single projection at a single view angle may be available at a time, making the problem severely ill-posed. In this work, we propose an approach, RED-PSM, which combines for the first time two powerful techniques to address this challenging imaging problem. The first, are partially separable models, which have been used to efficiently introduce a low-rank prior for the spatio-temporal object. The second is the recent Regularization by Denoising (RED), which provides a flexible framework to exploit the impressive performance of state-of-the-art image denoising algorithms, for various inverse problems. We propose a partially separable objective with RED and an optimization scheme with variable splitting and ADMM, and prove convergence of our objective to a value corresponding to a stationary point satisfying the first order optimality conditions. Convergence is accelerated by a particular projection-domain-based initialization. We demonstrate the performance and computational improvements of our proposed RED-PSM with a learned image denoiser by comparing it to a recent deep-prior-based method TD-DIP.
Improving Dense Contrastive Learning with Dense Negative Pairs
Oct 11, 2022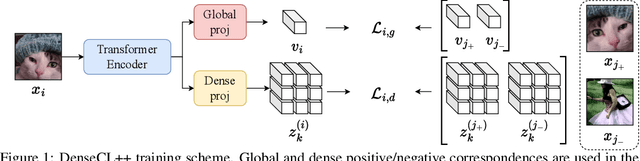
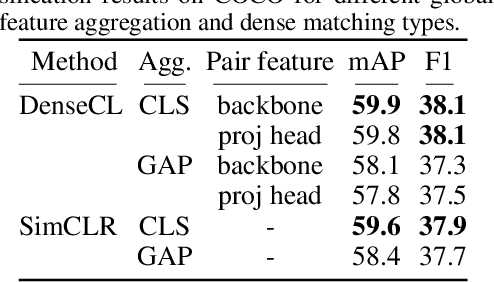
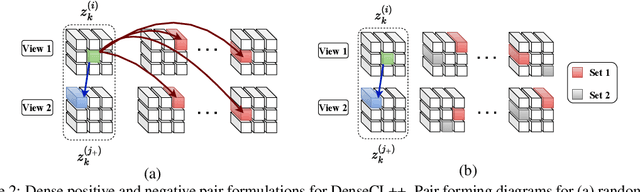
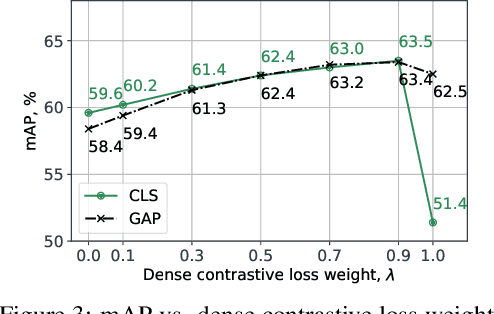
Many contrastive representation learning methods learn a single global representation of an entire image. However, dense contrastive representation learning methods such as DenseCL [19] can learn better representations for tasks requiring stronger spatial localization of features, such as multi-label classification, detection, and segmentation. In this work, we study how to improve the quality of the representations learned by DenseCL by modifying the training scheme and objective function, and propose DenseCL++. We also conduct several ablation studies to better understand the effects of: (i) various techniques to form dense negative pairs among augmentations of different images, (ii) cross-view dense negative and positive pairs, and (iii) an auxiliary reconstruction task. Our results show 3.5% and 4% mAP improvement over SimCLR [3] and DenseCL in COCO multi-label classification. In COCO and VOC segmentation tasks, we achieve 1.8% and 0.7% mIoU improvements over SimCLR, respectively.
Dynamic Tomography Reconstruction by Projection-Domain Separable Modeling
Apr 21, 2022
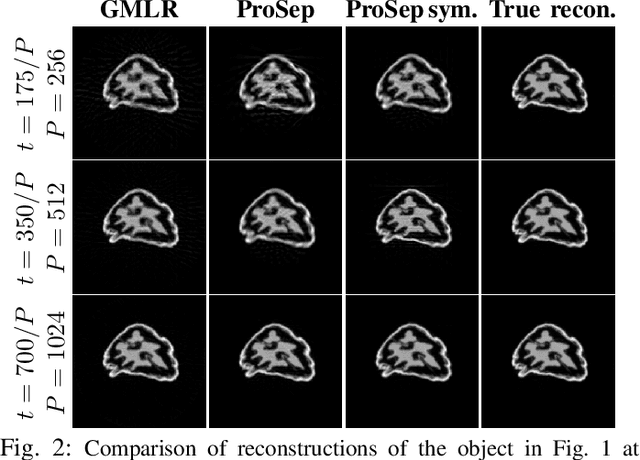

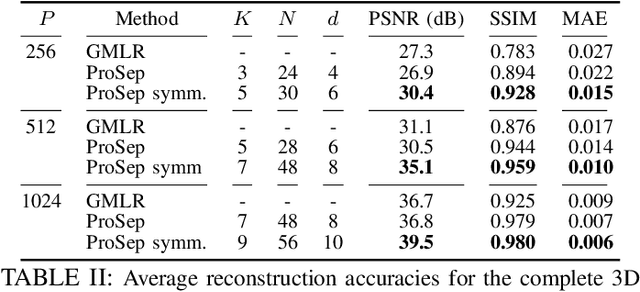
In dynamic tomography the object undergoes changes while projections are being acquired sequentially in time. The resulting inconsistent set of projections cannot be used directly to reconstruct an object corresponding to a time instant. Instead, the objective is to reconstruct a spatio-temporal representation of the object, which can be displayed as a movie. We analyze conditions for unique and stable solution of this ill-posed inverse problem, and present a recovery algorithm, validating it experimentally. We compare our approach to one based on the recently proposed GMLR variation on deep prior for video, demonstrating the advantages of the proposed approach.
Scatter Correction in X-ray CT by Physics-Inspired Deep Learning
Mar 21, 2021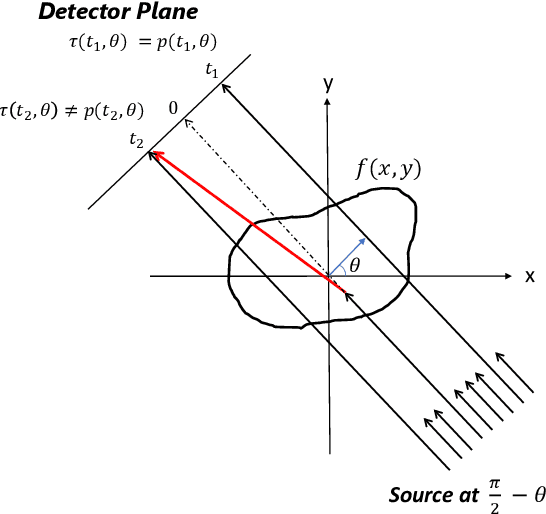
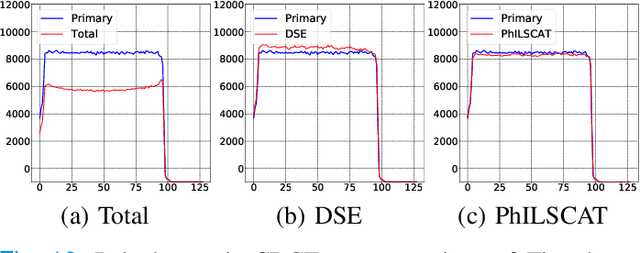

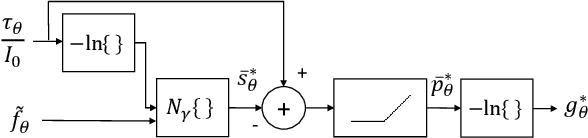
A fundamental problem in X-ray Computed Tomography (CT) is the scatter due to interaction of photons with the imaged object. Unless corrected, scatter manifests itself as degradations in the reconstructions in the form of various artifacts. Scatter correction is therefore critical for reconstruction quality. Scatter correction methods can be divided into two categories: hardware-based; and software-based. Despite success in specific settings, hardware-based methods require modification in the hardware, or increase in the scan time or dose. This makes software-based methods attractive. In this context, Monte-Carlo based scatter estimation, analytical-numerical, and kernel-based methods were developed. Furthermore, data-driven approaches to tackle this problem were recently demonstrated. In this work, two novel physics-inspired deep-learning-based methods, PhILSCAT and OV-PhILSCAT, are proposed. The methods estimate and correct for the scatter in the acquired projection measurements. They incorporate both an initial reconstruction of the object of interest and the scatter-corrupted measurements related to it. They use a common deep neural network architecture and cost function, both tailored to the problem. Numerical experiments with data obtained by Monte-Carlo simulations of the imaging of phantoms reveal significant improvement over a recent purely projection-domain deep neural network scatter correction method.