 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSR-NF: Neural Field Regularization by Static Restoration Priors for Dynamic Imaging
Mar 13, 2025Dynamic imaging involves the reconstruction of a spatio-temporal object at all times using its undersampled measurements. In particular, in dynamic computed tomography (dCT), only a single projection at one view angle is available at a time, making the inverse problem very challenging. Moreover, ground-truth dynamic data is usually either unavailable or too scarce to be used for supervised learning techniques. To tackle this problem, we propose RSR-NF, which uses a neural field (NF) to represent the dynamic object and, using the Regularization-by-Denoising (RED) framework, incorporates an additional static deep spatial prior into a variational formulation via a learned restoration operator. We use an ADMM-based algorithm with variable splitting to efficiently optimize the variational objective. We compare RSR-NF to three alternatives: NF with only temporal regularization; a recent method combining a partially-separable low-rank representation with RED using a denoiser pretrained on static data; and a deep-image prior-based model. The first comparison demonstrates the reconstruction improvements achieved by combining the NF representation with static restoration priors, whereas the other two demonstrate the improvement over state-of-the art techniques for dCT.
Learning Robust Features for Scatter Removal and Reconstruction in Dynamic ICF X-Ray Tomography
Aug 22, 2024Density reconstruction from X-ray projections is an important problem in radiography with key applications in scientific and industrial X-ray computed tomography (CT). Often, such projections are corrupted by unknown sources of noise and scatter, which when not properly accounted for, can lead to significant errors in density reconstruction. In the setting of this problem, recent deep learning-based methods have shown promise in improving the accuracy of density reconstruction. In this article, we propose a deep learning-based encoder-decoder framework wherein the encoder extracts robust features from noisy/corrupted X-ray projections and the decoder reconstructs the density field from the features extracted by the encoder. We explore three options for the latent-space representation of features: physics-inspired supervision, self-supervision, and no supervision. We find that variants based on self-supervised and physicsinspired supervised features perform better over a range of unknown scatter and noise. In extreme noise settings, the variant with self-supervised features performs best. After investigating further details of the proposed deep-learning methods, we conclude by demonstrating that the newly proposed methods are able to achieve higher accuracy in density reconstruction when compared to a traditional iterative technique.
Reconstructing Richtmyer-Meshkov instabilities from noisy radiographs using low dimensional features and attention-based neural networks
Aug 02, 2024A trained attention-based transformer network can robustly recover the complex topologies given by the Richtmyer-Meshkoff instability from a sequence of hydrodynamic features derived from radiographic images corrupted with blur, scatter, and noise. This approach is demonstrated on ICF-like double shell hydrodynamic simulations. The key component of this network is a transformer encoder that acts on a sequence of features extracted from noisy radiographs. This encoder includes numerous self-attention layers that act to learn temporal dependencies in the input sequences and increase the expressiveness of the model. This approach is demonstrated to exhibit an excellent ability to accurately recover the Richtmyer-Meshkov instability growth rates, even despite the gas-metal interface being greatly obscured by radiographic noise.
Score-based Diffusion Models for Bayesian Image Reconstruction
May 25, 2023This paper explores the use of score-based diffusion models for Bayesian image reconstruction. Diffusion models are an efficient tool for generative modeling. Diffusion models can also be used for solving image reconstruction problems. We present a simple and flexible algorithm for training a diffusion model and using it for maximum a posteriori reconstruction, minimum mean square error reconstruction, and posterior sampling. We present experiments on both a linear and a nonlinear reconstruction problem that highlight the strengths and limitations of the approach.
RED-PSM: Regularization by Denoising of Partially Separable Models for Dynamic Imaging
Apr 07, 2023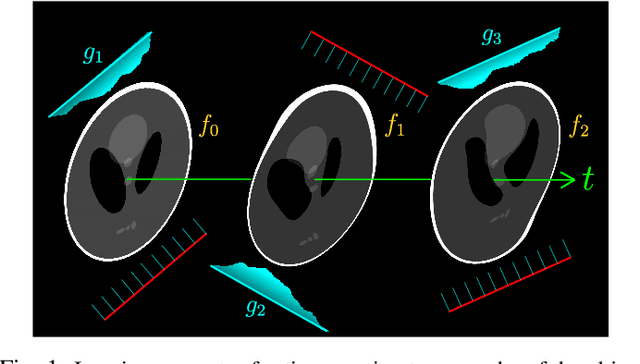
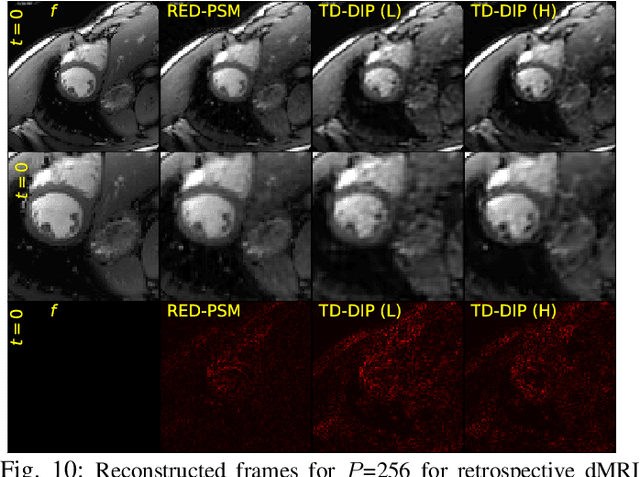
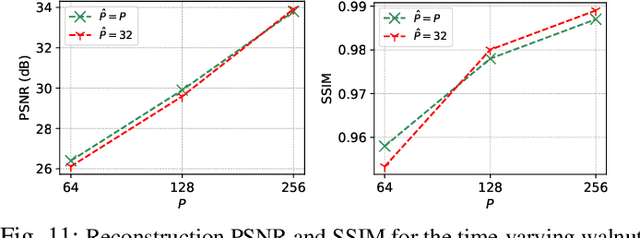
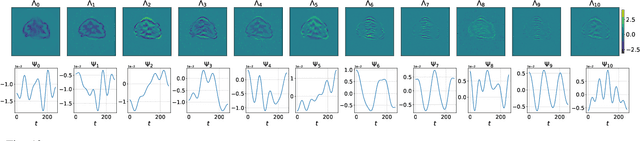
Dynamic imaging addresses the recovery of a time-varying 2D or 3D object at each time instant using its undersampled measurements. In particular, in the case of dynamic tomography, only a single projection at a single view angle may be available at a time, making the problem severely ill-posed. In this work, we propose an approach, RED-PSM, which combines for the first time two powerful techniques to address this challenging imaging problem. The first, are partially separable models, which have been used to efficiently introduce a low-rank prior for the spatio-temporal object. The second is the recent Regularization by Denoising (RED), which provides a flexible framework to exploit the impressive performance of state-of-the-art image denoising algorithms, for various inverse problems. We propose a partially separable objective with RED and an optimization scheme with variable splitting and ADMM, and prove convergence of our objective to a value corresponding to a stationary point satisfying the first order optimality conditions. Convergence is accelerated by a particular projection-domain-based initialization. We demonstrate the performance and computational improvements of our proposed RED-PSM with a learned image denoiser by comparing it to a recent deep-prior-based method TD-DIP.
Material Identification From Radiographs Without Energy Resolution
Mar 10, 2023We propose a method for performing material identification from radiographs without energy-resolved measurements. Material identification has a wide variety of applications, including in biomedical imaging, nondestructive testing, and security. While existing techniques for radiographic material identification make use of dual energy sources, energy-resolving detectors, or additional (e.g., neutron) measurements, such setups are not always practical-requiring additional hardware and complicating imaging. We tackle material identification without energy resolution, allowing standard X-ray systems to provide material identification information without requiring additional hardware. Assuming a setting where the geometry of each object in the scene is known and the materials come from a known set of possible materials, we pose the problem as a combinatorial optimization with a loss function that accounts for the presence of scatter and an unknown gain and propose a branch and bound algorithm to efficiently solve it. We present experiments on both synthetic data and real, experimental data with relevance to security applications-thick, dense objects imaged with MeV X-rays. We show that material identification can be efficient and accurate, for example, in a scene with three shells (two copper, one aluminum), our algorithm ran in six minutes on a consumer-level laptop and identified the correct materials as being among the top 10 best matches out of 8,000 possibilities.
Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
Nov 19, 2022Diffusion models have emerged as the new state-of-the-art generative model with high quality samples, with intriguing properties such as mode coverage and high flexibility. They have also been shown to be effective inverse problem solvers, acting as the prior of the distribution, while the information of the forward model can be granted at the sampling stage. Nonetheless, as the generative process remains in the same high dimensional (i.e. identical to data dimension) space, the models have not been extended to 3D inverse problems due to the extremely high memory and computational cost. In this paper, we combine the ideas from the conventional model-based iterative reconstruction with the modern diffusion models, which leads to a highly effective method for solving 3D medical image reconstruction tasks such as sparse-view tomography, limited angle tomography, compressed sensing MRI from pre-trained 2D diffusion models. In essence, we propose to augment the 2D diffusion prior with a model-based prior in the remaining direction at test time, such that one can achieve coherent reconstructions across all dimensions. Our method can be run in a single commodity GPU, and establishes the new state-of-the-art, showing that the proposed method can perform reconstructions of high fidelity and accuracy even in the most extreme cases (e.g. 2-view 3D tomography). We further reveal that the generalization capacity of the proposed method is surprisingly high, and can be used to reconstruct volumes that are entirely different from the training dataset.
Diffusion Posterior Sampling for General Noisy Inverse Problems
Sep 29, 2022
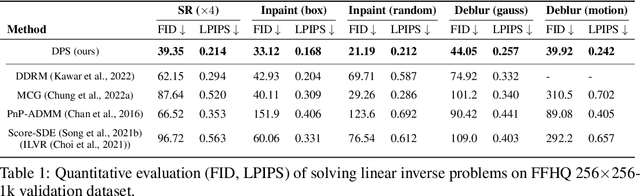

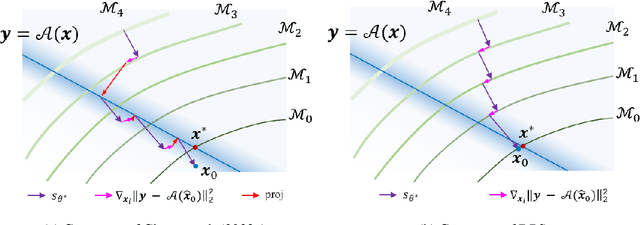
Diffusion models have been recently studied as powerful generative inverse problem solvers, owing to their high quality reconstructions and the ease of combining existing iterative solvers. However, most works focus on solving simple linear inverse problems in noiseless settings, which significantly under-represents the complexity of real-world problems. In this work, we extend diffusion solvers to efficiently handle general noisy (non)linear inverse problems via the Laplace approximation of the posterior sampling. Interestingly, the resulting posterior sampling scheme is a blended version of diffusion sampling with the manifold constrained gradient without a strict measurement consistency projection step, yielding a more desirable generative path in noisy settings compared to the previous studies. Our method demonstrates that diffusion models can incorporate various measurement noise statistics such as Gaussian and Poisson, and also efficiently handle noisy nonlinear inverse problems such as Fourier phase retrieval and non-uniform deblurring.
Dynamic Tomography Reconstruction by Projection-Domain Separable Modeling
Apr 21, 2022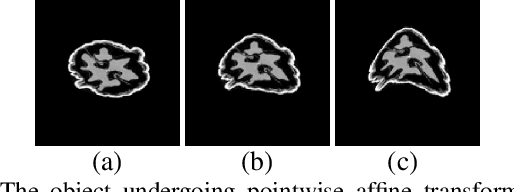
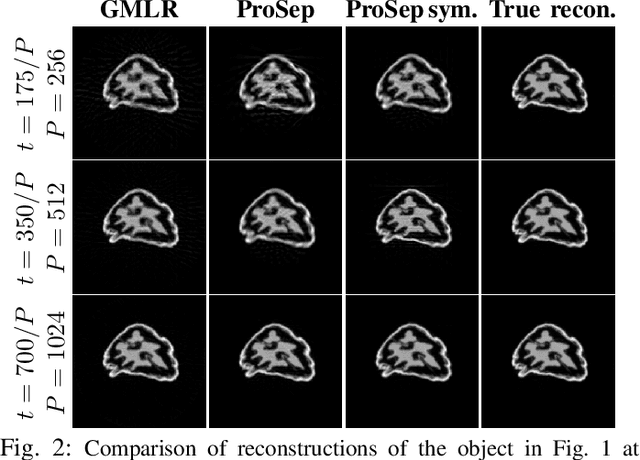

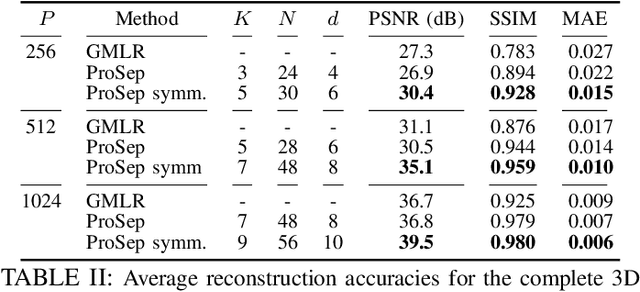
In dynamic tomography the object undergoes changes while projections are being acquired sequentially in time. The resulting inconsistent set of projections cannot be used directly to reconstruct an object corresponding to a time instant. Instead, the objective is to reconstruct a spatio-temporal representation of the object, which can be displayed as a movie. We analyze conditions for unique and stable solution of this ill-posed inverse problem, and present a recovery algorithm, validating it experimentally. We compare our approach to one based on the recently proposed GMLR variation on deep prior for video, demonstrating the advantages of the proposed approach.
High-Precision Inversion of Dynamic Radiography Using Hydrodynamic Features
Dec 02, 2021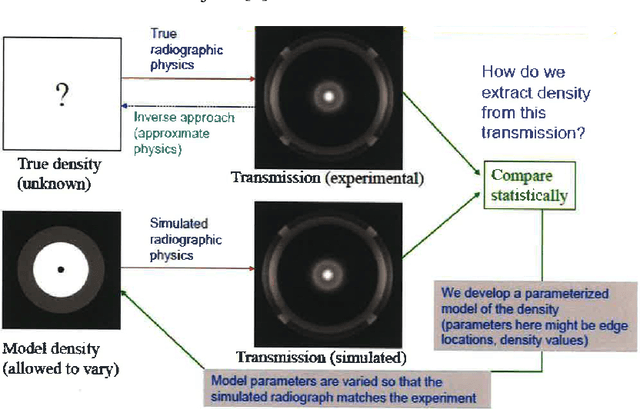

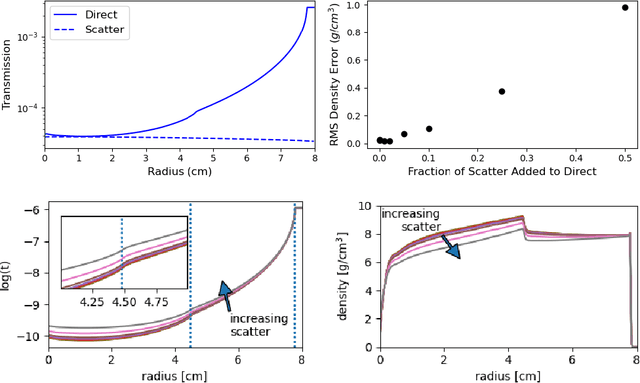
Radiography is often used to probe complex, evolving density fields in dynamic systems and in so doing gain insight into the underlying physics. This technique has been used in numerous fields including materials science, shock physics, inertial confinement fusion, and other national security applications. In many of these applications, however, complications resulting from noise, scatter, complex beam dynamics, etc. prevent the reconstruction of density from being accurate enough to identify the underlying physics with sufficient confidence. As such, density reconstruction from static/dynamic radiography has typically been limited to identifying discontinuous features such as cracks and voids in a number of these applications. In this work, we propose a fundamentally new approach to reconstructing density from a temporal sequence of radiographic images. Using only the robust features identifiable in radiographs, we combine them with the underlying hydrodynamic equations of motion using a machine learning approach, namely, conditional generative adversarial networks (cGAN), to determine the density fields from a dynamic sequence of radiographs. Next, we seek to further enhance the hydrodynamic consistency of the ML-based density reconstruction through a process of parameter estimation and projection onto a hydrodynamic manifold. In this context, we note that the distance from the hydrodynamic manifold given by the training data to the test data in the parameter space considered both serves as a diagnostic of the robustness of the predictions and serves to augment the training database, with the expectation that the latter will further reduce future density reconstruction errors. Finally, we demonstrate the ability of this method to outperform a traditional radiographic reconstruction in capturing allowable hydrodynamic paths even when relatively small amounts of scatter are present.