 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCELOT 2023: Cell Detection from Cell-Tissue Interaction Challenge
Sep 11, 2025Pathologists routinely alternate between different magnifications when examining Whole-Slide Images, allowing them to evaluate both broad tissue morphology and intricate cellular details to form comprehensive diagnoses. However, existing deep learning-based cell detection models struggle to replicate these behaviors and learn the interdependent semantics between structures at different magnifications. A key barrier in the field is the lack of datasets with multi-scale overlapping cell and tissue annotations. The OCELOT 2023 challenge was initiated to gather insights from the community to validate the hypothesis that understanding cell and tissue (cell-tissue) interactions is crucial for achieving human-level performance, and to accelerate the research in this field. The challenge dataset includes overlapping cell detection and tissue segmentation annotations from six organs, comprising 673 pairs sourced from 306 The Cancer Genome Atlas (TCGA) Whole-Slide Images with hematoxylin and eosin staining, divided into training, validation, and test subsets. Participants presented models that significantly enhanced the understanding of cell-tissue relationships. Top entries achieved up to a 7.99 increase in F1-score on the test set compared to the baseline cell-only model that did not incorporate cell-tissue relationships. This is a substantial improvement in performance over traditional cell-only detection methods, demonstrating the need for incorporating multi-scale semantics into the models. This paper provides a comparative analysis of the methods used by participants, highlighting innovative strategies implemented in the OCELOT 2023 challenge.
* This is the accepted manuscript of an article published in Medical Image Analysis (Elsevier). The final version is available at: https://doi.org/10.1016/j.media.2025.103751
Group Activity Recognition using Unreliable Tracked Pose
Jan 06, 2024

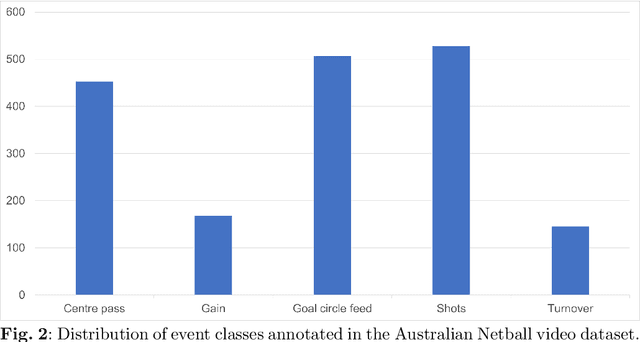

Group activity recognition in video is a complex task due to the need for a model to recognise the actions of all individuals in the video and their complex interactions. Recent studies propose that optimal performance is achieved by individually tracking each person and subsequently inputting the sequence of poses or cropped images/optical flow into a model. This helps the model to recognise what actions each person is performing before they are merged to arrive at the group action class. However, all previous models are highly reliant on high quality tracking and have only been evaluated using ground truth tracking information. In practice it is almost impossible to achieve highly reliable tracking information for all individuals in a group activity video. We introduce an innovative deep learning-based group activity recognition approach called Rendered Pose based Group Activity Recognition System (RePGARS) which is designed to be tolerant of unreliable tracking and pose information. Experimental results confirm that RePGARS outperforms all existing group activity recognition algorithms tested which do not use ground truth detection and tracking information.
Classifying Whole Slide Images: What Matters?
Oct 05, 2023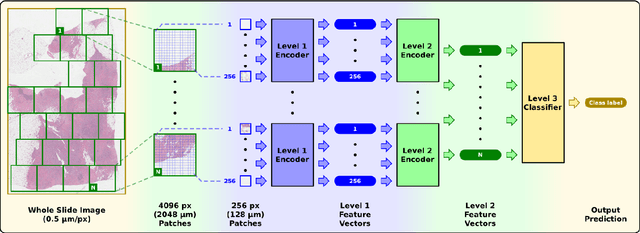
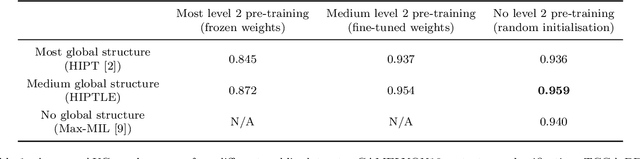
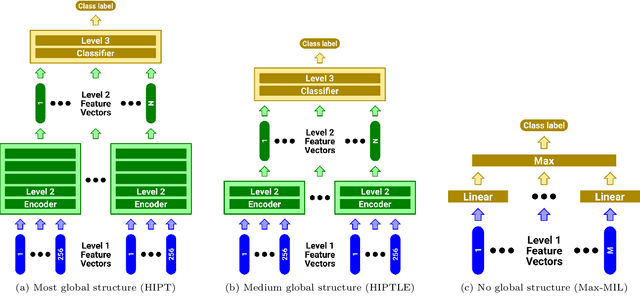
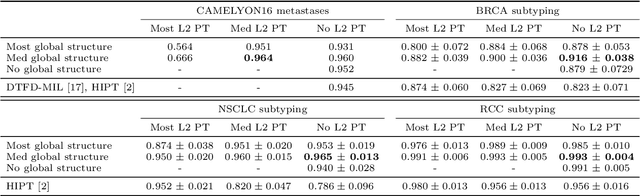
Recently there have been many algorithms proposed for the classification of very high resolution whole slide images (WSIs). These new algorithms are mostly focused on finding novel ways to combine the information from small local patches extracted from the slide, with an emphasis on effectively aggregating more global information for the final predictor. In this paper we thoroughly explore different key design choices for WSI classification algorithms to investigate what matters most for achieving high accuracy. Surprisingly, we found that capturing global context information does not necessarily mean better performance. A model that captures the most global information consistently performs worse than a model that captures less global information. In addition, a very simple multi-instance learning method that captures no global information performs almost as well as models that capture a lot of global information. These results suggest that the most important features for effective WSI classification are captured at the local small patch level, where cell and tissue micro-environment detail is most pronounced. Another surprising finding was that unsupervised pre-training on a larger set of 33 cancers gives significantly worse performance compared to pre-training on a smaller dataset of 7 cancers (including the target cancer). We posit that pre-training on a smaller, more focused dataset allows the feature extractor to make better use of the limited feature space to better discriminate between subtle differences in the input patch.
A systematic review of the use of Deep Learning in Satellite Imagery for Agriculture
Oct 03, 2022

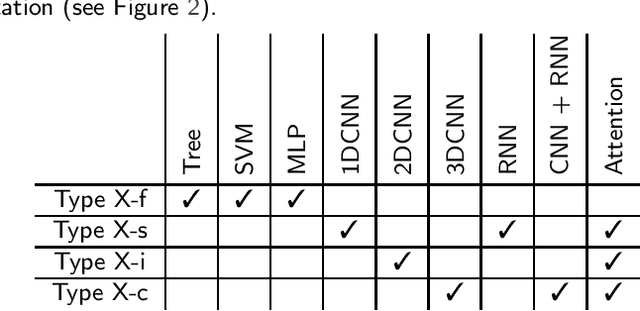
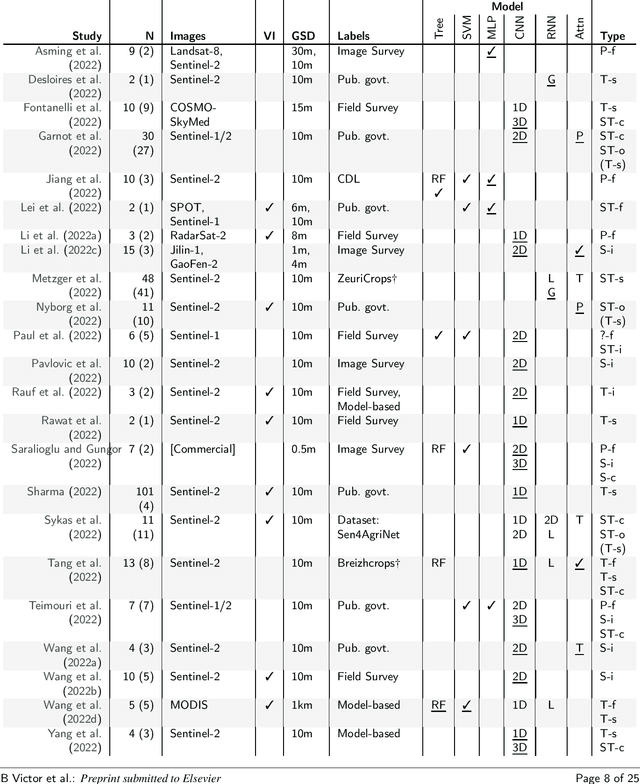
Agricultural research is essential for increasing food production to meet the requirements of an increasing population in the coming decades. Recently, satellite technology has been improving rapidly and deep learning has seen much success in generic computer vision tasks and many application areas which presents an important opportunity to improve analysis of agricultural land. Here we present a systematic review of 150 studies to find the current uses of deep learning on satellite imagery for agricultural research. Although we identify 5 categories of agricultural monitoring tasks, the majority of the research interest is in crop segmentation and yield prediction. We found that, when used, modern deep learning methods consistently outperformed traditional machine learning across most tasks; the only exception was that Long Short-Term Memory (LSTM) Recurrent Neural Networks did not consistently outperform Random Forests (RF) for yield prediction. The reviewed studies have largely adopted methodologies from generic computer vision, except for one major omission: benchmark datasets are not utilised to evaluate models across studies, making it difficult to compare results. Additionally, some studies have specifically utilised the extra spectral resolution available in satellite imagery, but other divergent properties of satellite images - such as the hugely different scales of spatial patterns - are not being taken advantage of in the reviewed studies.
Semi-supervised learning for medical image classification using imbalanced training data
Aug 20, 2021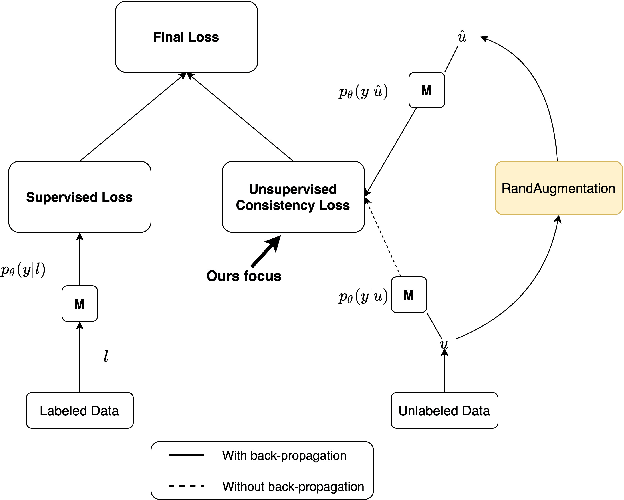
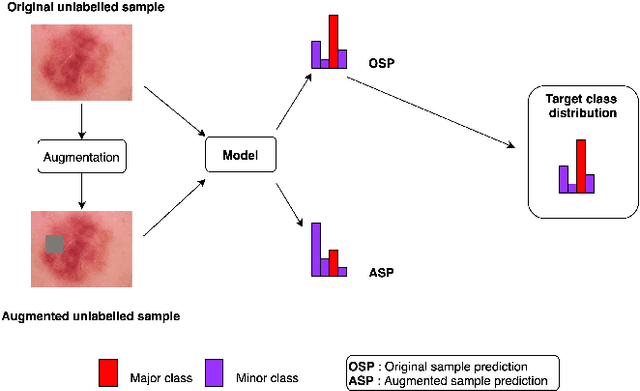
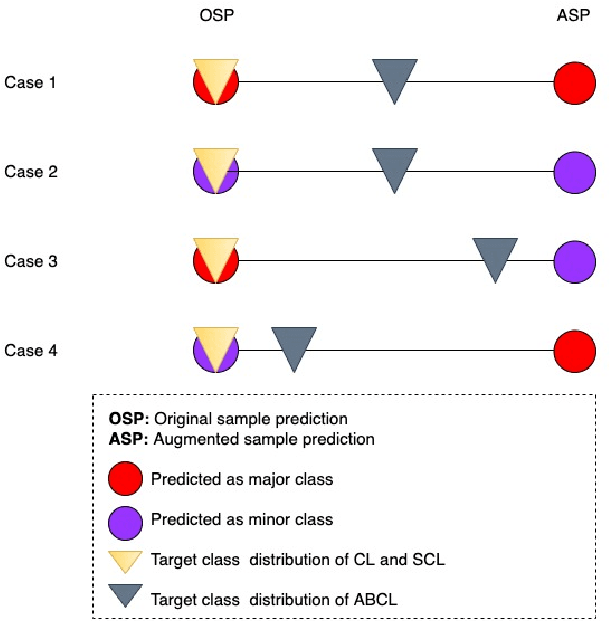
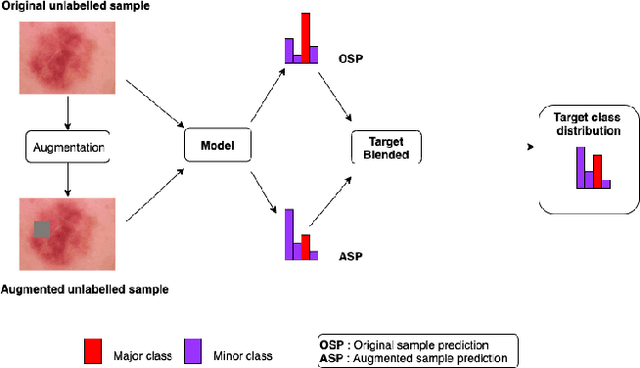
Medical image classification is often challenging for two reasons: a lack of labelled examples due to expensive and time-consuming annotation protocols, and imbalanced class labels due to the relative scarcity of disease-positive individuals in the wider population. Semi-supervised learning (SSL) methods exist for dealing with a lack of labels, but they generally do not address the problem of class imbalance. In this study we propose Adaptive Blended Consistency Loss (ABCL), a drop-in replacement for consistency loss in perturbation-based SSL methods. ABCL counteracts data skew by adaptively mixing the target class distribution of the consistency loss in accordance with class frequency. Our experiments with ABCL reveal improvements to unweighted average recall on two different imbalanced medical image classification datasets when compared with existing consistency losses that are not designed to counteract class imbalance.
Pose is all you need: The pose only group activity recognition system
Aug 09, 2021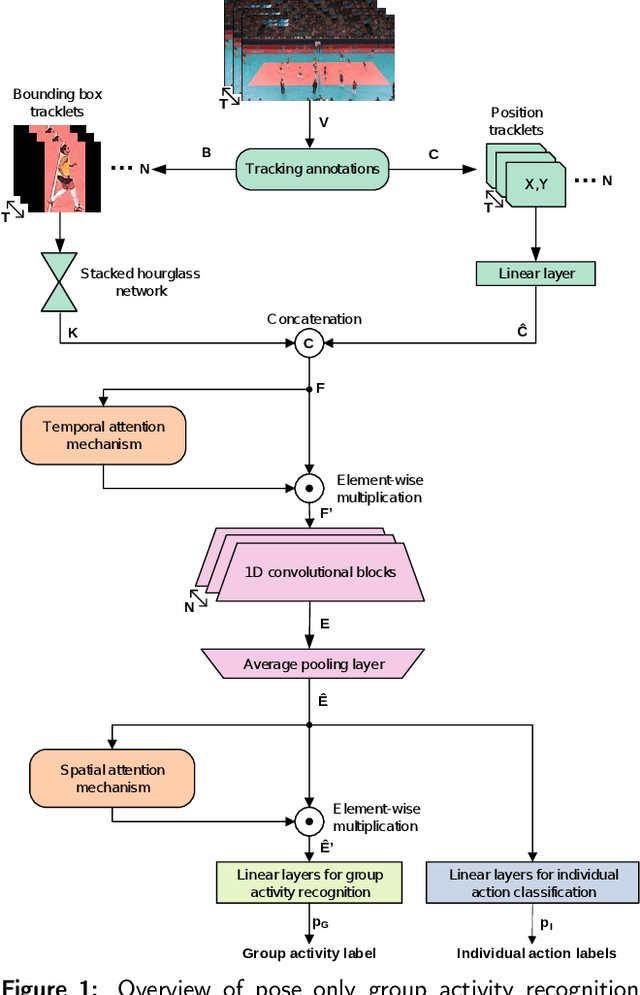

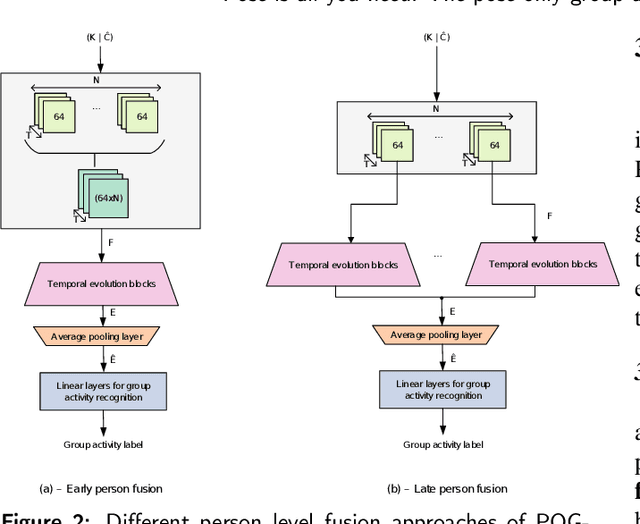

We introduce a novel deep learning based group activity recognition approach called the Pose Only Group Activity Recognition System (POGARS), designed to use only tracked poses of people to predict the performed group activity. In contrast to existing approaches for group activity recognition, POGARS uses 1D CNNs to learn spatiotemporal dynamics of individuals involved in a group activity and forgo learning features from pixel data. The proposed model uses a spatial and temporal attention mechanism to infer person-wise importance and multi-task learning for simultaneously performing group and individual action classification. Experimental results confirm that POGARS achieves highly competitive results compared to state-of-the-art methods on a widely used public volleyball dataset despite only using tracked pose as input. Further our experiments show by using pose only as input, POGARS has better generalization capabilities compared to methods that use RGB as input.
Enhancing Trajectory Prediction using Sparse Outputs: Application to Team Sports
Jun 01, 2021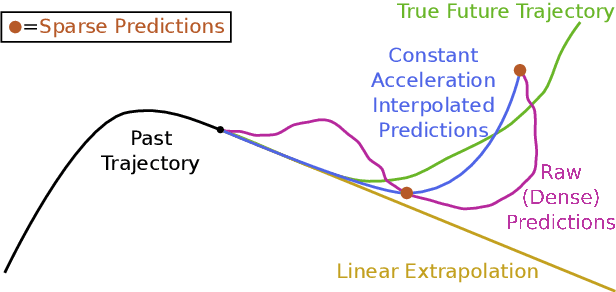

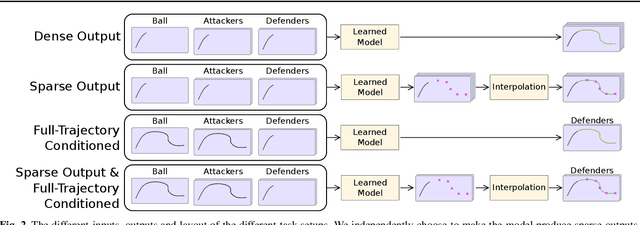
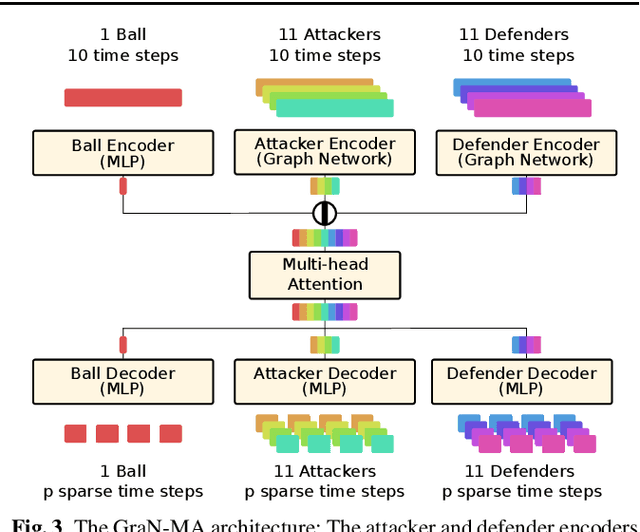
Sophisticated trajectory prediction models that effectively mimic team dynamics have many potential uses for sports coaches, broadcasters and spectators. However, through experiments on soccer data we found that it can be surprisingly challenging to train a deep learning model for player trajectory prediction which outperforms linear extrapolation on average distance between predicted and true future trajectories. We propose and test a novel method for improving training by predicting a sparse trajectory and interpolating using constant acceleration, which improves performance for several models. This interpolation can also be used on models that aren't trained with sparse outputs, and we find that this consistently improves performance for all tested models. Additionally, we find that the accuracy of predicted trajectories for a subset of players can be improved by conditioning on the full trajectories of the other players, and that this is further improved when combined with sparse predictions. We also propose a novel architecture using graph networks and multi-head attention (GraN-MA) which achieves better performance than other tested state-of-the-art models on our dataset and is trivially adapted for both sparse trajectories and full-trajectory conditioned trajectory prediction.
3D Human Pose Estimation with 2D Marginal Heatmaps
Jun 05, 2018
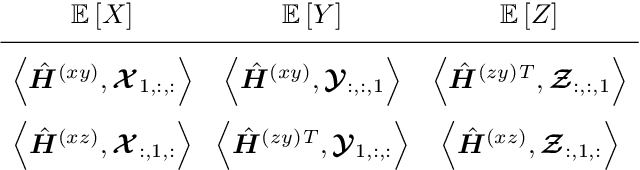
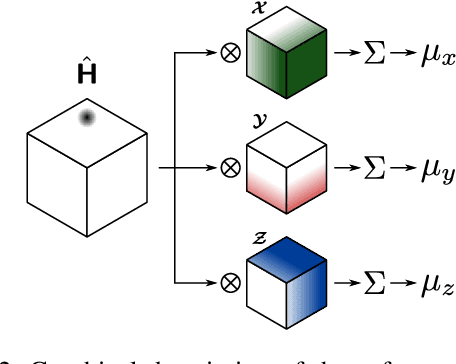
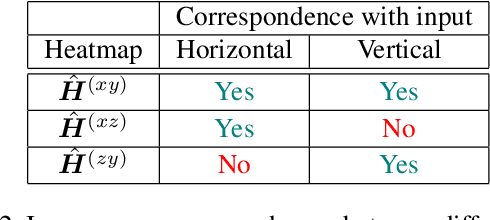
Automatically determining three-dimensional human pose from monocular RGB image data is a challenging problem. The two-dimensional nature of the input results in intrinsic ambiguities which make inferring depth particularly difficult. Recently, researchers have demonstrated that the flexible statistical modelling capabilities of deep neural networks are sufficient to make such inferences with reasonable accuracy. However, many of these models use coordinate output techniques which are memory-intensive, not differentiable, and/or do not spatially generalise well. We propose improvements to 3D coordinate prediction which avoid the aforementioned undesirable traits by predicting 2D marginal heatmaps under an augmented soft-argmax scheme. Our resulting model, MargiPose, produces visually coherent heatmaps whilst maintaining differentiability. We are also able to achieve state-of-the-art accuracy on publicly available 3D human pose estimation data.
Numerical Coordinate Regression with Convolutional Neural Networks
May 03, 2018
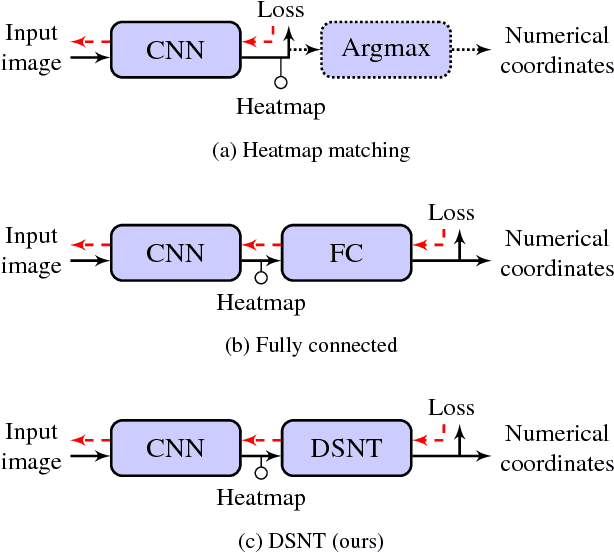


We study deep learning approaches to inferring numerical coordinates for points of interest in an input image. Existing convolutional neural network-based solutions to this problem either take a heatmap matching approach or regress to coordinates with a fully connected output layer. Neither of these approaches is ideal, since the former is not entirely differentiable, and the latter lacks inherent spatial generalization. We propose our differentiable spatial to numerical transform (DSNT) to fill this gap. The DSNT layer adds no trainable parameters, is fully differentiable, and exhibits good spatial generalization. Unlike heatmap matching, DSNT works well with low heatmap resolutions, so it can be dropped in as an output layer for a wide range of existing fully convolutional architectures. Consequently, DSNT offers a better trade-off between inference speed and prediction accuracy compared to existing techniques. When used to replace the popular heatmap matching approach used in almost all state-of-the-art methods for pose estimation, DSNT gives better prediction accuracy for all model architectures tested.
Extraction and Classification of Diving Clips from Continuous Video Footage
May 25, 2017
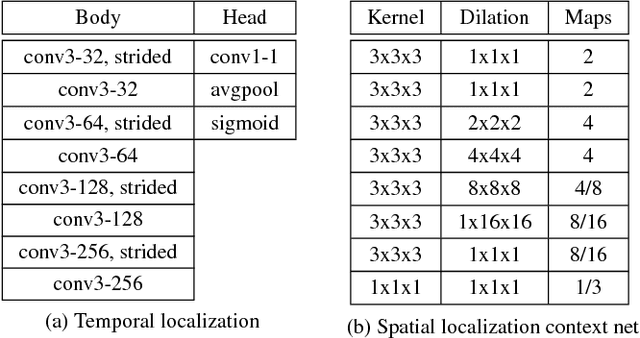
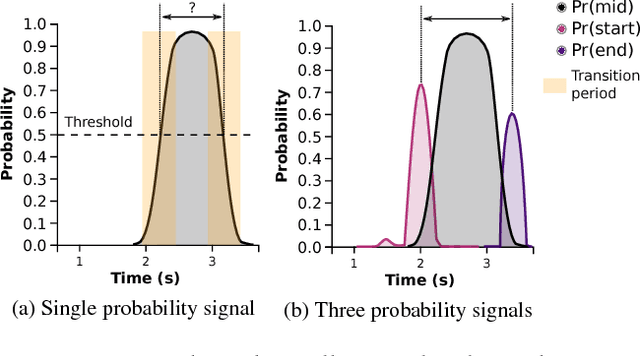

Due to recent advances in technology, the recording and analysis of video data has become an increasingly common component of athlete training programmes. Today it is incredibly easy and affordable to set up a fixed camera and record athletes in a wide range of sports, such as diving, gymnastics, golf, tennis, etc. However, the manual analysis of the obtained footage is a time-consuming task which involves isolating actions of interest and categorizing them using domain-specific knowledge. In order to automate this kind of task, three challenging sub-problems are often encountered: 1) temporally cropping events/actions of interest from continuous video; 2) tracking the object of interest; and 3) classifying the events/actions of interest. Most previous work has focused on solving just one of the above sub-problems in isolation. In contrast, this paper provides a complete solution to the overall action monitoring task in the context of a challenging real-world exemplar. Specifically, we address the problem of diving classification. This is a challenging problem since the person (diver) of interest typically occupies fewer than 1% of the pixels in each frame. The model is required to learn the temporal boundaries of a dive, even though other divers and bystanders may be in view. Finally, the model must be sensitive to subtle changes in body pose over a large number of frames to determine the classification code. We provide effective solutions to each of the sub-problems which combine to provide a highly functional solution to the task as a whole. The techniques proposed can be easily generalized to video footage recorded from other sports.