 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Activity Recognition using Unreliable Tracked Pose
Jan 06, 2024

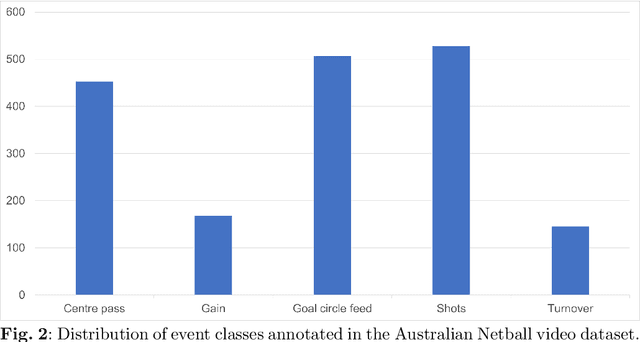

Group activity recognition in video is a complex task due to the need for a model to recognise the actions of all individuals in the video and their complex interactions. Recent studies propose that optimal performance is achieved by individually tracking each person and subsequently inputting the sequence of poses or cropped images/optical flow into a model. This helps the model to recognise what actions each person is performing before they are merged to arrive at the group action class. However, all previous models are highly reliant on high quality tracking and have only been evaluated using ground truth tracking information. In practice it is almost impossible to achieve highly reliable tracking information for all individuals in a group activity video. We introduce an innovative deep learning-based group activity recognition approach called Rendered Pose based Group Activity Recognition System (RePGARS) which is designed to be tolerant of unreliable tracking and pose information. Experimental results confirm that RePGARS outperforms all existing group activity recognition algorithms tested which do not use ground truth detection and tracking information.
Pose is all you need: The pose only group activity recognition system
Aug 09, 2021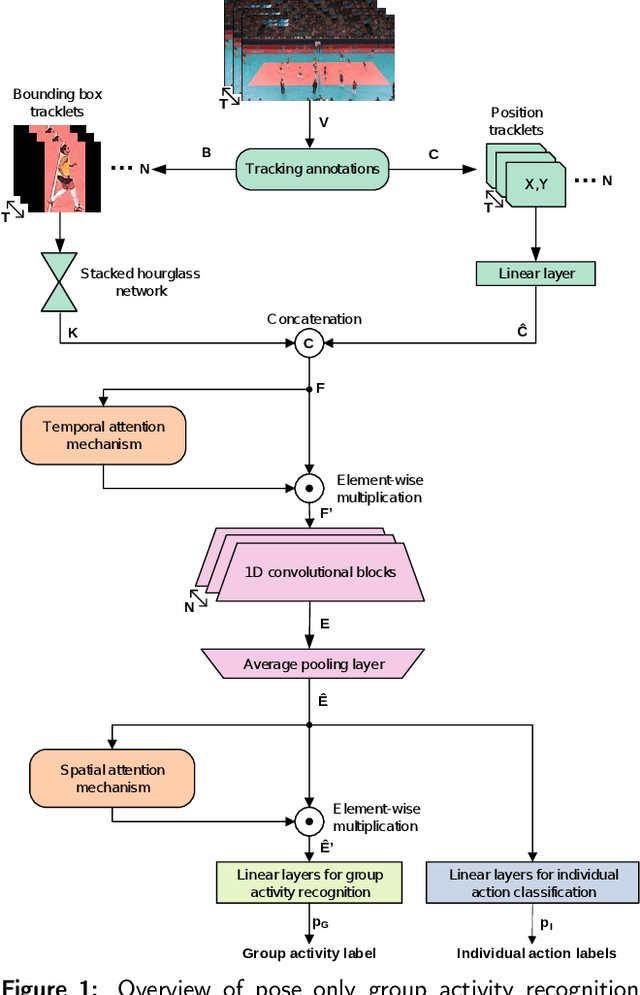

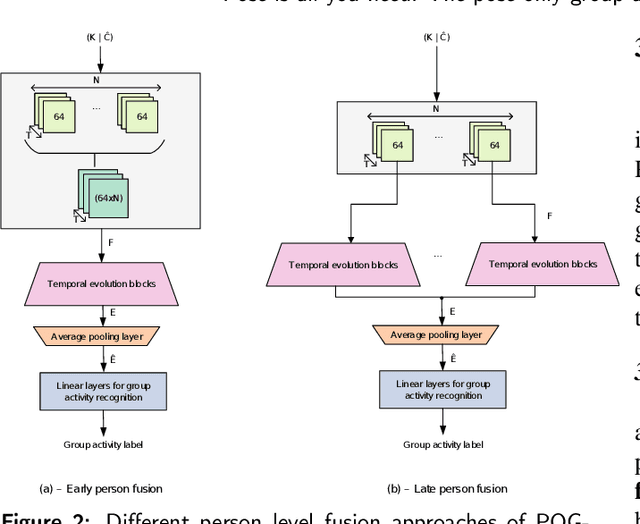

We introduce a novel deep learning based group activity recognition approach called the Pose Only Group Activity Recognition System (POGARS), designed to use only tracked poses of people to predict the performed group activity. In contrast to existing approaches for group activity recognition, POGARS uses 1D CNNs to learn spatiotemporal dynamics of individuals involved in a group activity and forgo learning features from pixel data. The proposed model uses a spatial and temporal attention mechanism to infer person-wise importance and multi-task learning for simultaneously performing group and individual action classification. Experimental results confirm that POGARS achieves highly competitive results compared to state-of-the-art methods on a widely used public volleyball dataset despite only using tracked pose as input. Further our experiments show by using pose only as input, POGARS has better generalization capabilities compared to methods that use RGB as input.
3D Human Pose Estimation with 2D Marginal Heatmaps
Jun 05, 2018
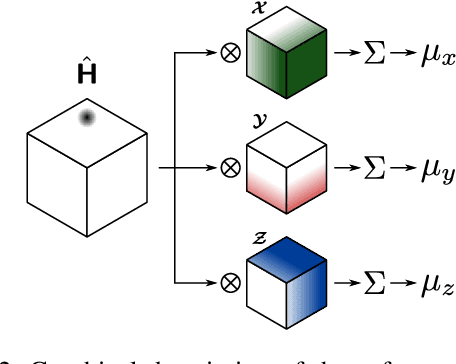
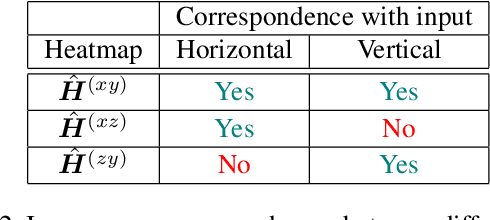
Automatically determining three-dimensional human pose from monocular RGB image data is a challenging problem. The two-dimensional nature of the input results in intrinsic ambiguities which make inferring depth particularly difficult. Recently, researchers have demonstrated that the flexible statistical modelling capabilities of deep neural networks are sufficient to make such inferences with reasonable accuracy. However, many of these models use coordinate output techniques which are memory-intensive, not differentiable, and/or do not spatially generalise well. We propose improvements to 3D coordinate prediction which avoid the aforementioned undesirable traits by predicting 2D marginal heatmaps under an augmented soft-argmax scheme. Our resulting model, MargiPose, produces visually coherent heatmaps whilst maintaining differentiability. We are also able to achieve state-of-the-art accuracy on publicly available 3D human pose estimation data.
Numerical Coordinate Regression with Convolutional Neural Networks
May 03, 2018
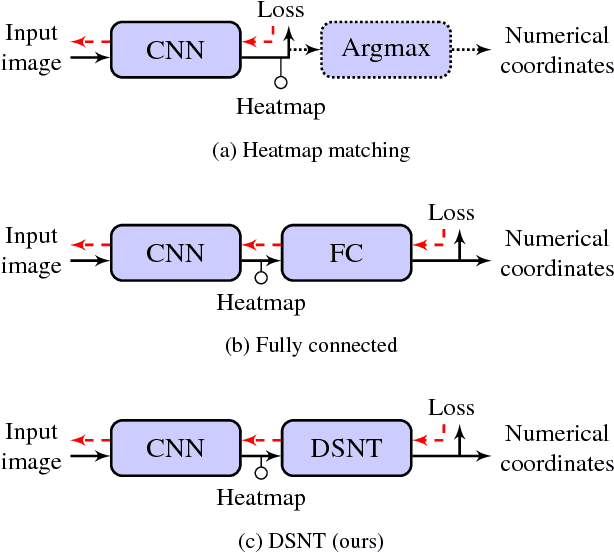


We study deep learning approaches to inferring numerical coordinates for points of interest in an input image. Existing convolutional neural network-based solutions to this problem either take a heatmap matching approach or regress to coordinates with a fully connected output layer. Neither of these approaches is ideal, since the former is not entirely differentiable, and the latter lacks inherent spatial generalization. We propose our differentiable spatial to numerical transform (DSNT) to fill this gap. The DSNT layer adds no trainable parameters, is fully differentiable, and exhibits good spatial generalization. Unlike heatmap matching, DSNT works well with low heatmap resolutions, so it can be dropped in as an output layer for a wide range of existing fully convolutional architectures. Consequently, DSNT offers a better trade-off between inference speed and prediction accuracy compared to existing techniques. When used to replace the popular heatmap matching approach used in almost all state-of-the-art methods for pose estimation, DSNT gives better prediction accuracy for all model architectures tested.
Continuous Video to Simple Signals for Swimming Stroke Detection with Convolutional Neural Networks
May 28, 2017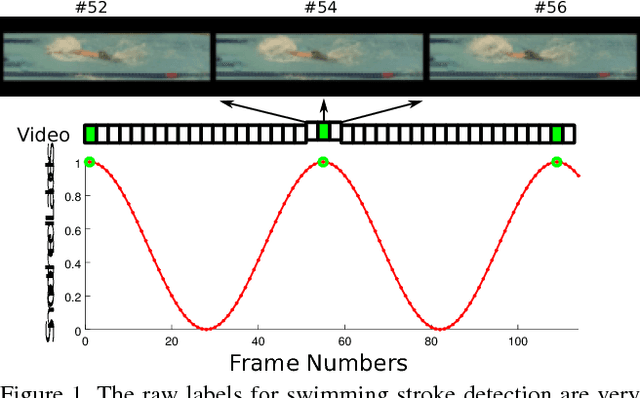

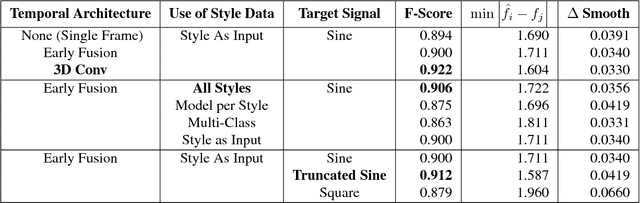
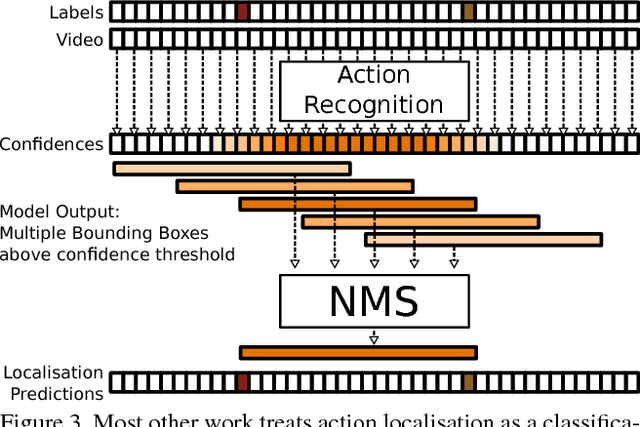
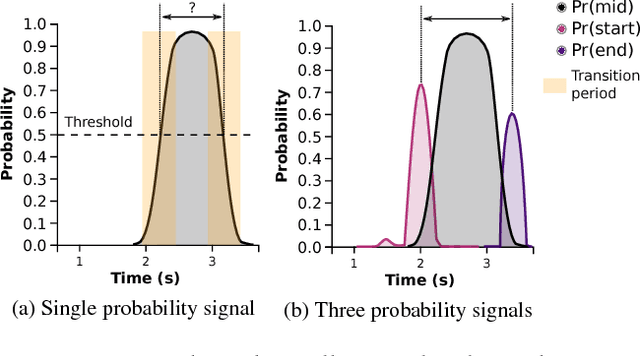
In many sports, it is useful to analyse video of an athlete in competition for training purposes. In swimming, stroke rate is a common metric used by coaches; requiring a laborious labelling of each individual stroke. We show that using a Convolutional Neural Network (CNN) we can automatically detect discrete events in continuous video (in this case, swimming strokes). We create a CNN that learns a mapping from a window of frames to a point on a smooth 1D target signal, with peaks denoting the location of a stroke, evaluated as a sliding window. To our knowledge this process of training and utilizing a CNN has not been investigated before; either in sports or fundamental computer vision research. Most research has been focused on action recognition and using it to classify many clips in continuous video for action localisation. In this paper we demonstrate our process works well on the task of detecting swimming strokes in the wild. However, without modifying the model architecture or training method, the process is also shown to work equally well on detecting tennis strokes, implying that this is a general process. The outputs of our system are surprisingly smooth signals that predict an arbitrary event at least as accurately as humans (manually evaluated from a sample of negative results). A number of different architectures are evaluated, pertaining to slightly different problem formulations and signal targets.
Extraction and Classification of Diving Clips from Continuous Video Footage
May 25, 2017
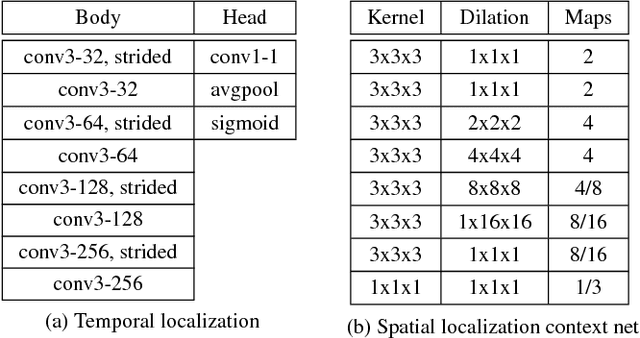

Due to recent advances in technology, the recording and analysis of video data has become an increasingly common component of athlete training programmes. Today it is incredibly easy and affordable to set up a fixed camera and record athletes in a wide range of sports, such as diving, gymnastics, golf, tennis, etc. However, the manual analysis of the obtained footage is a time-consuming task which involves isolating actions of interest and categorizing them using domain-specific knowledge. In order to automate this kind of task, three challenging sub-problems are often encountered: 1) temporally cropping events/actions of interest from continuous video; 2) tracking the object of interest; and 3) classifying the events/actions of interest. Most previous work has focused on solving just one of the above sub-problems in isolation. In contrast, this paper provides a complete solution to the overall action monitoring task in the context of a challenging real-world exemplar. Specifically, we address the problem of diving classification. This is a challenging problem since the person (diver) of interest typically occupies fewer than 1% of the pixels in each frame. The model is required to learn the temporal boundaries of a dive, even though other divers and bystanders may be in view. Finally, the model must be sensitive to subtle changes in body pose over a large number of frames to determine the classification code. We provide effective solutions to each of the sub-problems which combine to provide a highly functional solution to the task as a whole. The techniques proposed can be easily generalized to video footage recorded from other sports.