 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Pose Estimation with 2D Marginal Heatmaps
Jun 05, 2018
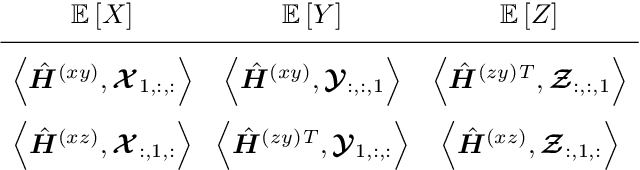
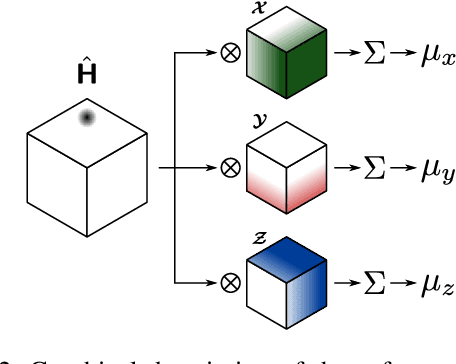
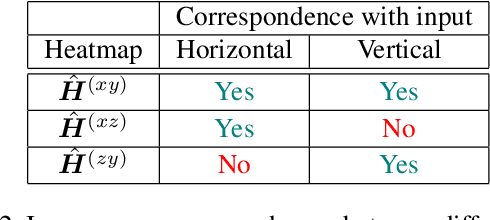
Automatically determining three-dimensional human pose from monocular RGB image data is a challenging problem. The two-dimensional nature of the input results in intrinsic ambiguities which make inferring depth particularly difficult. Recently, researchers have demonstrated that the flexible statistical modelling capabilities of deep neural networks are sufficient to make such inferences with reasonable accuracy. However, many of these models use coordinate output techniques which are memory-intensive, not differentiable, and/or do not spatially generalise well. We propose improvements to 3D coordinate prediction which avoid the aforementioned undesirable traits by predicting 2D marginal heatmaps under an augmented soft-argmax scheme. Our resulting model, MargiPose, produces visually coherent heatmaps whilst maintaining differentiability. We are also able to achieve state-of-the-art accuracy on publicly available 3D human pose estimation data.
Numerical Coordinate Regression with Convolutional Neural Networks
May 03, 2018
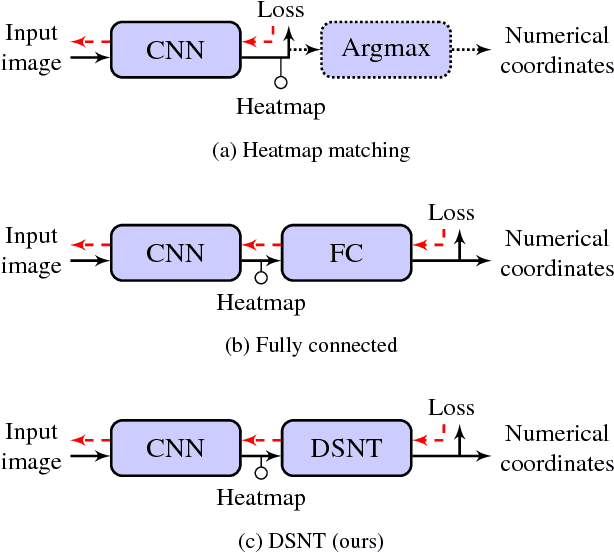


We study deep learning approaches to inferring numerical coordinates for points of interest in an input image. Existing convolutional neural network-based solutions to this problem either take a heatmap matching approach or regress to coordinates with a fully connected output layer. Neither of these approaches is ideal, since the former is not entirely differentiable, and the latter lacks inherent spatial generalization. We propose our differentiable spatial to numerical transform (DSNT) to fill this gap. The DSNT layer adds no trainable parameters, is fully differentiable, and exhibits good spatial generalization. Unlike heatmap matching, DSNT works well with low heatmap resolutions, so it can be dropped in as an output layer for a wide range of existing fully convolutional architectures. Consequently, DSNT offers a better trade-off between inference speed and prediction accuracy compared to existing techniques. When used to replace the popular heatmap matching approach used in almost all state-of-the-art methods for pose estimation, DSNT gives better prediction accuracy for all model architectures tested.