 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCELOT 2023: Cell Detection from Cell-Tissue Interaction Challenge
Sep 11, 2025Pathologists routinely alternate between different magnifications when examining Whole-Slide Images, allowing them to evaluate both broad tissue morphology and intricate cellular details to form comprehensive diagnoses. However, existing deep learning-based cell detection models struggle to replicate these behaviors and learn the interdependent semantics between structures at different magnifications. A key barrier in the field is the lack of datasets with multi-scale overlapping cell and tissue annotations. The OCELOT 2023 challenge was initiated to gather insights from the community to validate the hypothesis that understanding cell and tissue (cell-tissue) interactions is crucial for achieving human-level performance, and to accelerate the research in this field. The challenge dataset includes overlapping cell detection and tissue segmentation annotations from six organs, comprising 673 pairs sourced from 306 The Cancer Genome Atlas (TCGA) Whole-Slide Images with hematoxylin and eosin staining, divided into training, validation, and test subsets. Participants presented models that significantly enhanced the understanding of cell-tissue relationships. Top entries achieved up to a 7.99 increase in F1-score on the test set compared to the baseline cell-only model that did not incorporate cell-tissue relationships. This is a substantial improvement in performance over traditional cell-only detection methods, demonstrating the need for incorporating multi-scale semantics into the models. This paper provides a comparative analysis of the methods used by participants, highlighting innovative strategies implemented in the OCELOT 2023 challenge.
* This is the accepted manuscript of an article published in Medical Image Analysis (Elsevier). The final version is available at: https://doi.org/10.1016/j.media.2025.103751
Classifying Whole Slide Images: What Matters?
Oct 05, 2023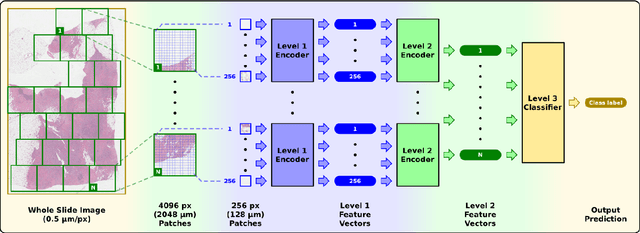
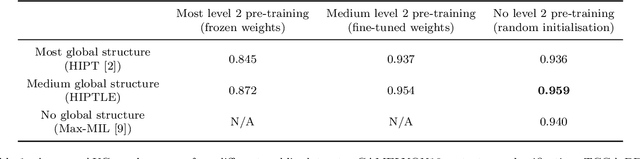
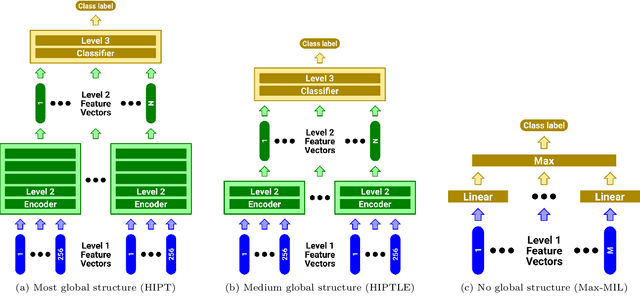
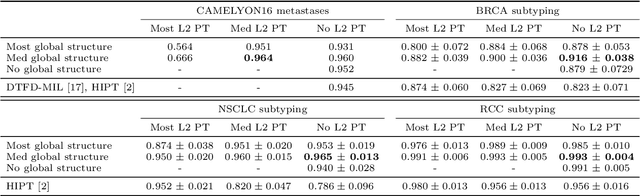
Recently there have been many algorithms proposed for the classification of very high resolution whole slide images (WSIs). These new algorithms are mostly focused on finding novel ways to combine the information from small local patches extracted from the slide, with an emphasis on effectively aggregating more global information for the final predictor. In this paper we thoroughly explore different key design choices for WSI classification algorithms to investigate what matters most for achieving high accuracy. Surprisingly, we found that capturing global context information does not necessarily mean better performance. A model that captures the most global information consistently performs worse than a model that captures less global information. In addition, a very simple multi-instance learning method that captures no global information performs almost as well as models that capture a lot of global information. These results suggest that the most important features for effective WSI classification are captured at the local small patch level, where cell and tissue micro-environment detail is most pronounced. Another surprising finding was that unsupervised pre-training on a larger set of 33 cancers gives significantly worse performance compared to pre-training on a smaller dataset of 7 cancers (including the target cancer). We posit that pre-training on a smaller, more focused dataset allows the feature extractor to make better use of the limited feature space to better discriminate between subtle differences in the input patch.