 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Event Detection as a Slot Filling Problem
Sep 13, 2021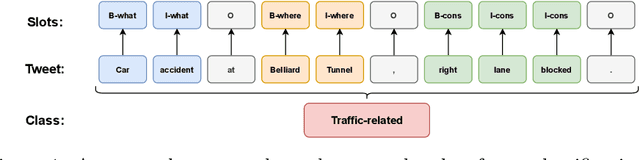
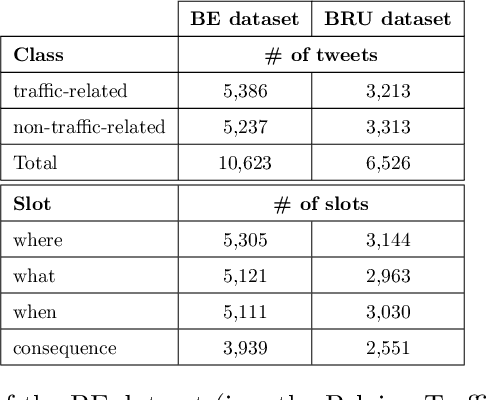
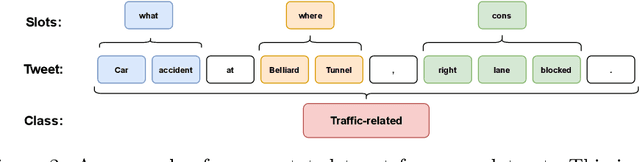

In this paper, we introduce the new problem of extracting fine-grained traffic information from Twitter streams by also making publicly available the two (constructed) traffic-related datasets from Belgium and the Brussels capital region. In particular, we experiment with several models to identify (i) whether a tweet is traffic-related or not, and (ii) in the case that the tweet is traffic-related to identify more fine-grained information regarding the event (e.g., the type of the event, where the event happened). To do so, we frame (i) the problem of identifying whether a tweet is a traffic-related event or not as a text classification subtask, and (ii) the problem of identifying more fine-grained traffic-related information as a slot filling subtask, where fine-grained information (e.g., where an event has happened) is represented as a slot/entity of a particular type. We propose the use of several methods that process the two subtasks either separately or in a joint setting, and we evaluate the effectiveness of the proposed methods for solving the traffic event detection problem. Experimental results indicate that the proposed architectures achieve high performance scores (i.e., more than 95% in terms of F$_{1}$ score) on the constructed datasets for both of the subtasks (i.e., text classification and slot filling) even in a transfer learning scenario. In addition, by incorporating tweet-level information in each of the tokens comprising the tweet (for the BERT-based model) can lead to a performance improvement for the joint setting.
Learned Gradient Compression for Distributed Deep Learning
Mar 17, 2021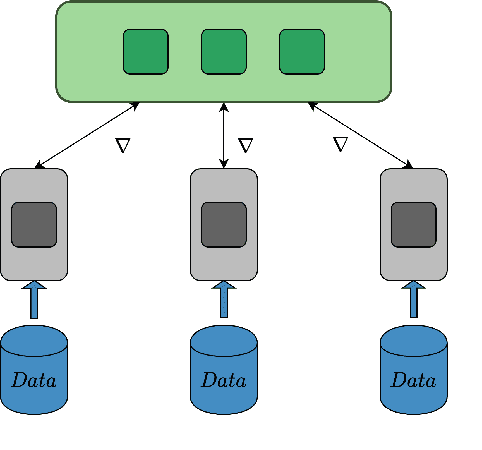
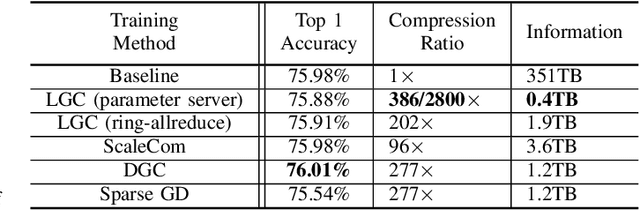
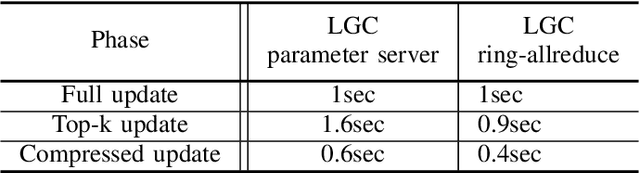
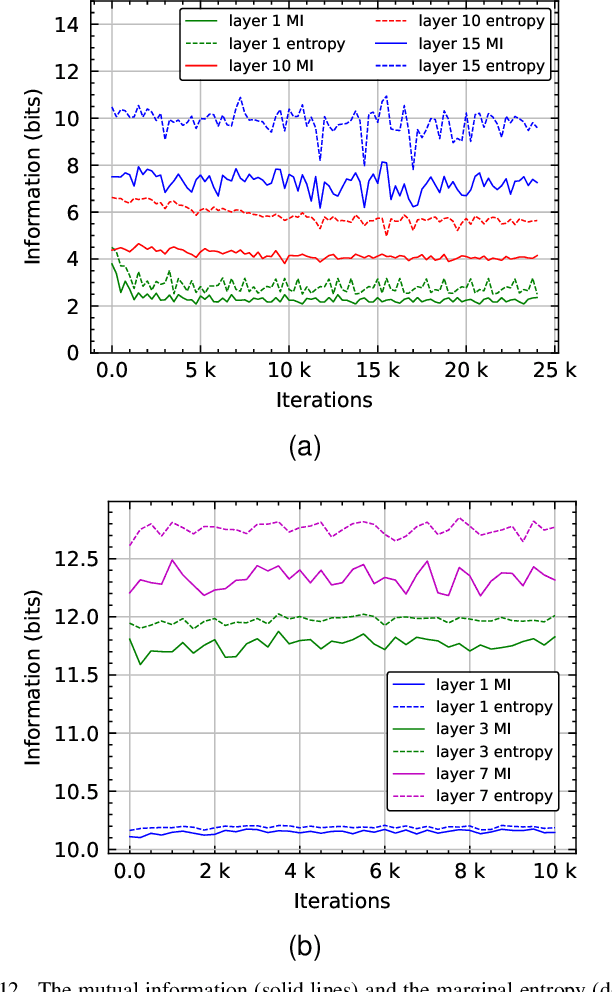
Training deep neural networks on large datasets containing high-dimensional data requires a large amount of computation. A solution to this problem is data-parallel distributed training, where a model is replicated into several computational nodes that have access to different chunks of the data. This approach, however, entails high communication rates and latency because of the computed gradients that need to be shared among nodes at every iteration. The problem becomes more pronounced in the case that there is wireless communication between the nodes (i.e. due to the limited network bandwidth). To address this problem, various compression methods have been proposed including sparsification, quantization, and entropy encoding of the gradients. Existing methods leverage the intra-node information redundancy, that is, they compress gradients at each node independently. In contrast, we advocate that the gradients across the nodes are correlated and propose methods to leverage this inter-node redundancy to improve compression efficiency. Depending on the node communication protocol (parameter server or ring-allreduce), we propose two instances of the LGC approach that we coin Learned Gradient Compression (LGC). Our methods exploit an autoencoder (i.e. trained during the first stages of the distributed training) to capture the common information that exists in the gradients of the distributed nodes. We have tested our LGC methods on the image classification and semantic segmentation tasks using different convolutional neural networks (ResNet50, ResNet101, PSPNet) and multiple datasets (ImageNet, Cifar10, CamVid). The ResNet101 model trained for image classification on Cifar10 achieved an accuracy of 93.57%, which is lower than the baseline distributed training with uncompressed gradients only by 0.18%.
A Review on Fact Extraction and VERification: The FEVER case
Oct 19, 2020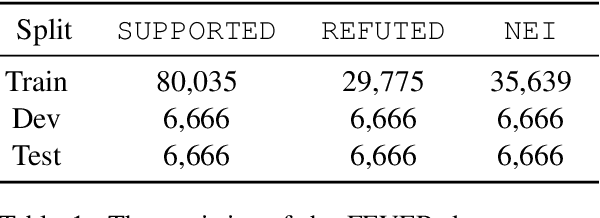
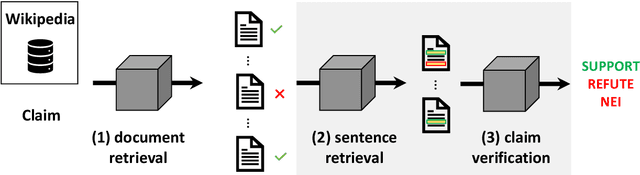
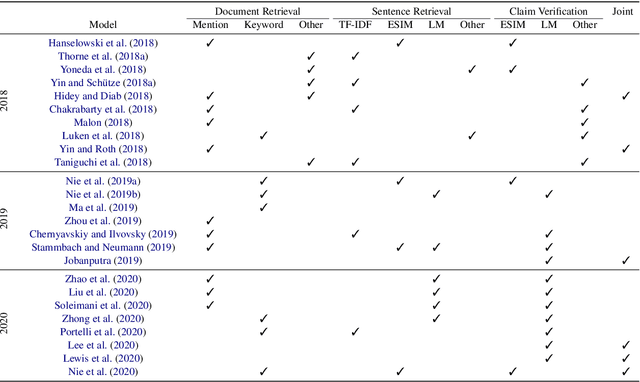
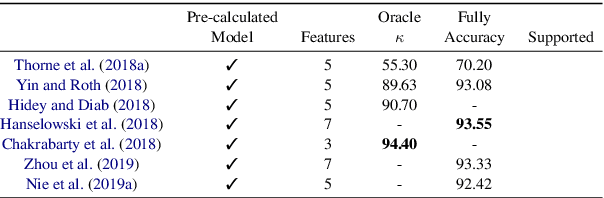
Fact Extraction and VERification (FEVER) is a recently introduced task which aims to identify the veracity of a given claim based on Wikipedia documents. A lot of methods have been proposed to address this problem which consists of the subtasks of (i) retrieving the relevant documents (and sentences) from Wikipedia and (ii) validating whether the information in the documents supports or refutes a given claim. This task is essential since it can be the building block of applications that require a deep understanding of the language such as fake news detection and medical claim verification. In this paper, we aim to get a better understanding of the challenges in the task by presenting the literature in a structured and comprehensive way. In addition, we describe the proposed methods by analyzing the technical perspectives of the different approaches and discussing the performance results on the FEVER dataset.
Solving Math Word Problems by Scoring Equations with Recursive Neural Networks
Sep 11, 2020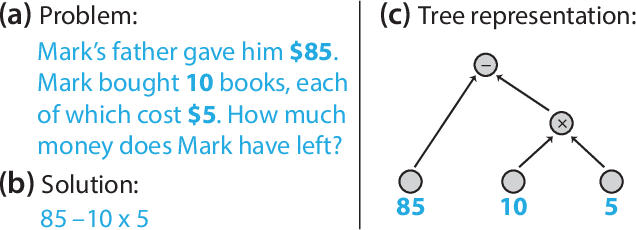

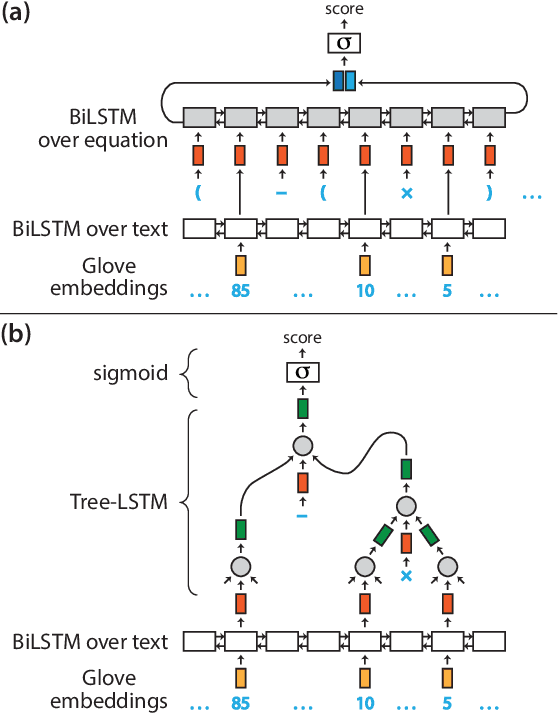
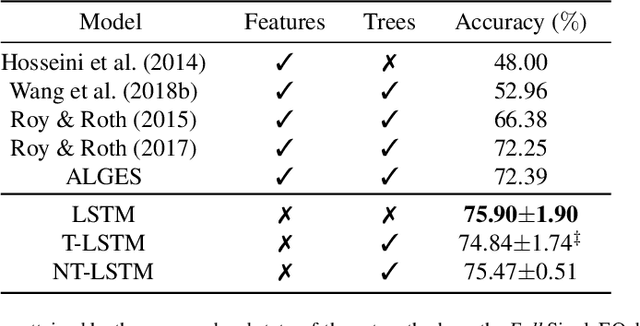
Solving math word problems is a cornerstone task in assessing language understanding and reasoning capabilities in NLP systems. Recent works use automatic extraction and ranking of candidate solution equations providing the answer to math word problems. In this work, we explore novel approaches to score such candidate solution equations using tree-structured recursive neural network (Tree-RNN) configurations. The advantage of this Tree-RNN approach over using more established sequential representations, is that it can naturally capture the structure of the equations. Our proposed method consists in transforming the mathematical expression of the equation into an expression tree. Further, we encode this tree into a Tree-RNN by using different Tree-LSTM architectures. Experimental results show that our proposed method (i) improves overall performance with more than 3% accuracy points compared to previous state-of-the-art, and with over 18% points on a subset of problems that require more complex reasoning, and (ii) outperforms sequential LSTMs by 4% accuracy points on such more complex problems.
Graph Convolutional Neural Networks with Node Transition Probability-based Message Passing and DropNode Regularization
Aug 28, 2020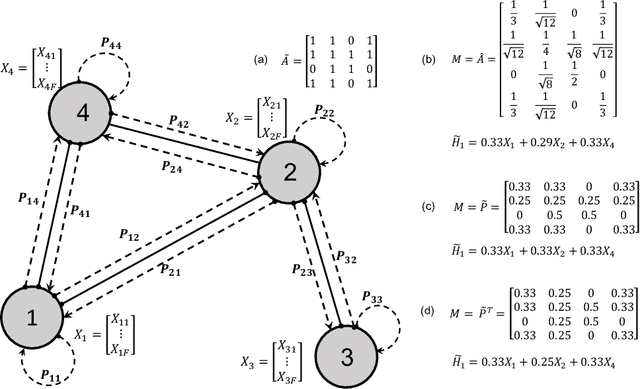
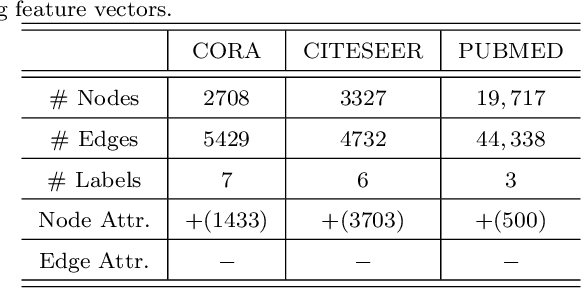
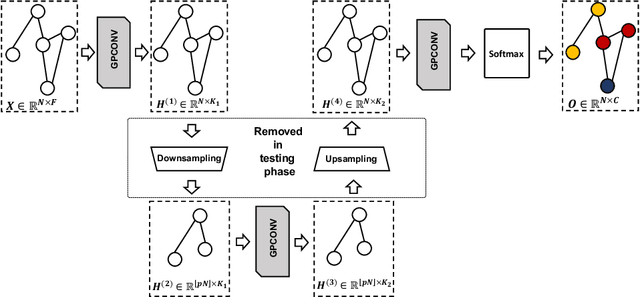
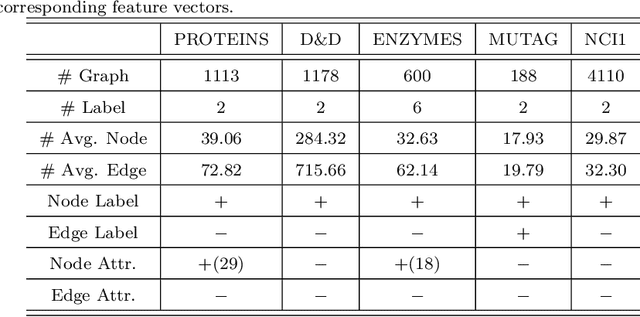
Graph convolutional neural networks (GCNNs) have received much attention recently, owing to their capability in handling graph-structured data. Among the existing GCNNs, many methods can be viewed as instances of a neural message passing motif; features of nodes are passed around their neighbors, aggregated and transformed to produce better nodes' representations. Nevertheless, these methods seldom use node transition probabilities, a measure that has been found useful in exploring graphs. Furthermore, when the transition probabilities are used, their transition direction is often improperly considered in the feature aggregation step, resulting in an inefficient weighting scheme. In addition, although a great number of GCNN models with increasing level of complexity have been introduced, the GCNNs often suffer from over-fitting when being trained on small graphs. Another issue of the GCNNs is over-smoothing, which tends to make nodes' representations indistinguishable. This work presents a new method to improve the message passing process based on node transition probabilities by properly considering the transition direction, leading to a better weighting scheme in nodes' features aggregation compared to the existing counterpart. Moreover, we propose a novel regularization method termed DropNode to address the over-fitting and over-smoothing issues simultaneously. DropNode randomly discards part of a graph, thus it creates multiple deformed versions of the graph, leading to data augmentation regularization effect. Additionally, DropNode lessens the connectivity of the graph, mitigating the effect of over-smoothing in deep GCNNs. Extensive experiments on eight benchmark datasets for node and graph classification tasks demonstrate the effectiveness of the proposed methods in comparison with the state of the art.
Zero-Shot Cross-Lingual Transfer with Meta Learning
Apr 02, 2020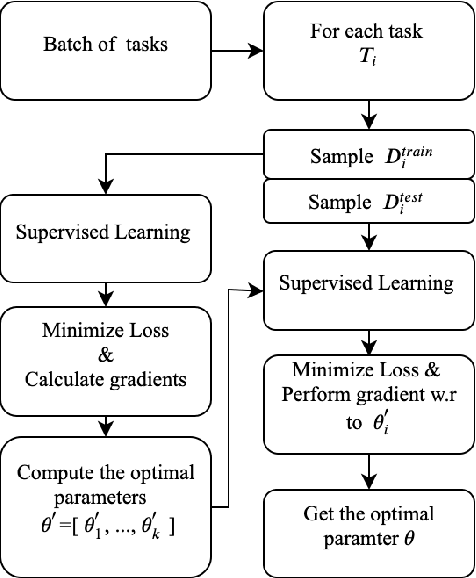
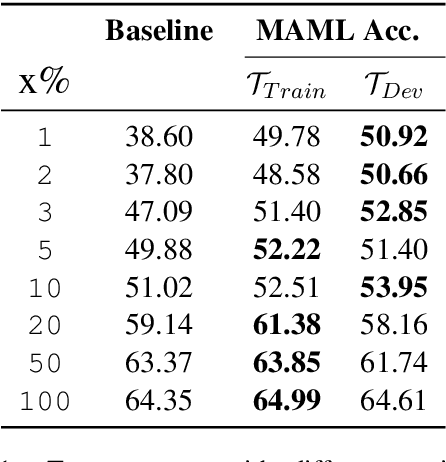
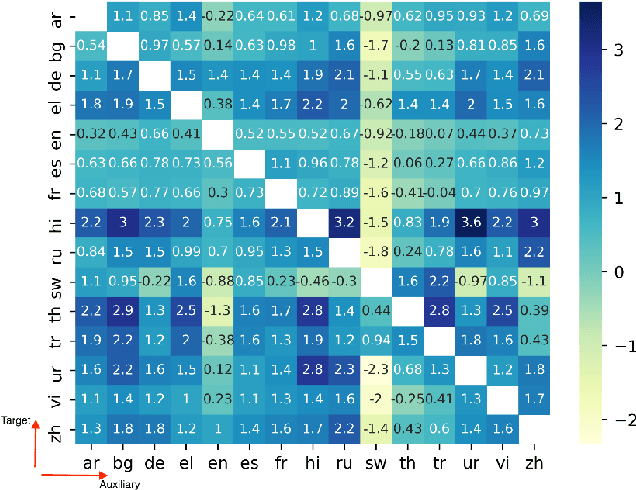
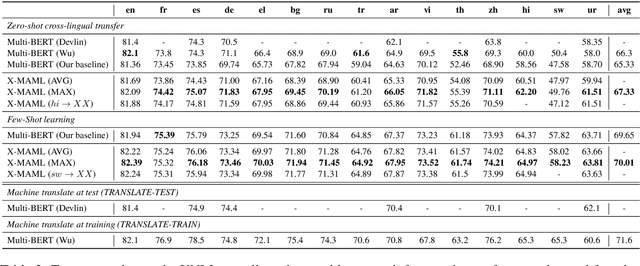
Learning what to share between tasks has been a topic of great importance recently, as strategic sharing of knowledge has been shown to improve the performance of downstream tasks. In multilingual applications, sharing of knowledge between languages is important when considering the fact that most languages in the world suffer from being under-resourced. In this paper, we consider the setting of training models on multiple different languages at the same time, when English training data, but little or no in-language data is available. We show that this challenging setup can be approached using meta-learning, where, in addition to training a source language model, another model learns to select which training instances are the most beneficial. We experiment using standard supervised, zero-shot cross-lingual, as well as few-shot cross-lingual settings for different natural language understanding tasks (natural language inference, question answering). Our extensive experimental setup demonstrates the consistent effectiveness of meta-learning in a total of 16 languages. We improve upon the state-of-the-art for zero-shot and few-shot NLI and QA tasks on two NLI datasets (i.e., MultiNLI and XNLI), and on the X-WikiRE dataset, respectively. We further conduct a comprehensive analysis, which indicates that the correlation of typological features between languages can further explain when parameter sharing learned via meta-learning is beneficial.
Sub-event detection from Twitter streams as a sequence labeling problem
Mar 13, 2019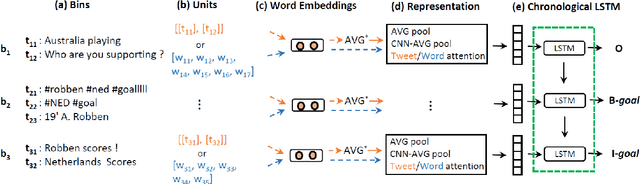

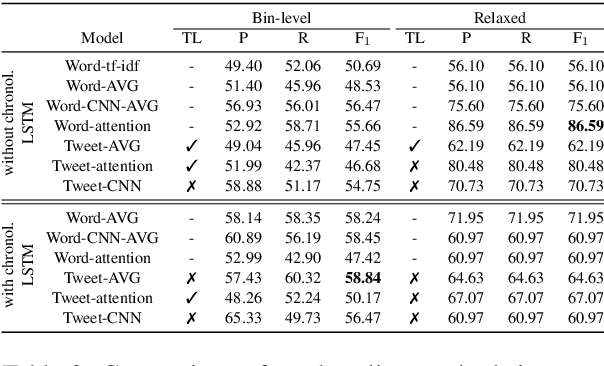

This paper introduces improved methods for sub-event detection in social media streams, by applying neural sequence models not only on the level of individual posts, but also directly on the stream level. Current approaches to identify sub-events within a given event, such as a goal during a soccer match, essentially do not exploit the sequential nature of social media streams. We address this shortcoming by framing the sub-event detection problem in social media streams as a sequence labeling task and adopt a neural sequence architecture that explicitly accounts for the chronological order of posts. Specifically, we (i) establish a neural baseline that outperforms a graph-based state-of-the-art method for binary sub-event detection (2.7% micro-F1 improvement), as well as (ii) demonstrate superiority of a recurrent neural network model on the posts sequence level for labeled sub-events (2.4% bin-level F1 improvement over non-sequential models).
Adversarial training for multi-context joint entity and relation extraction
Aug 21, 2018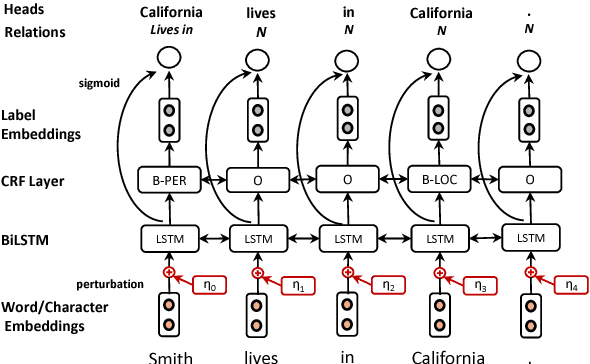
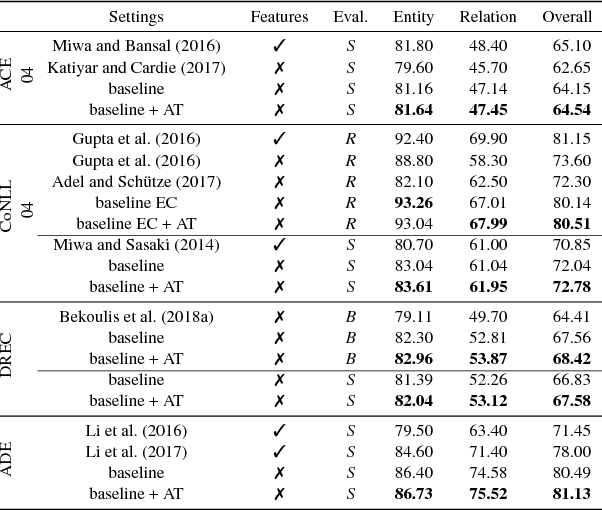
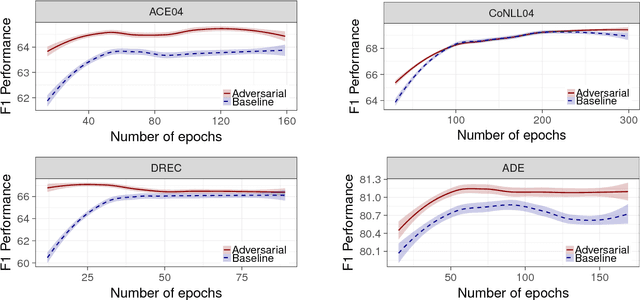
Adversarial training (AT) is a regularization method that can be used to improve the robustness of neural network methods by adding small perturbations in the training data. We show how to use AT for the tasks of entity recognition and relation extraction. In particular, we demonstrate that applying AT to a general purpose baseline model for jointly extracting entities and relations, allows improving the state-of-the-art effectiveness on several datasets in different contexts (i.e., news, biomedical, and real estate data) and for different languages (English and Dutch).
Joint entity recognition and relation extraction as a multi-head selection problem
Aug 16, 2018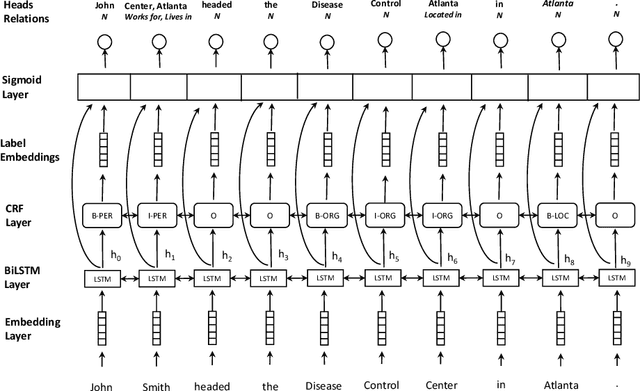
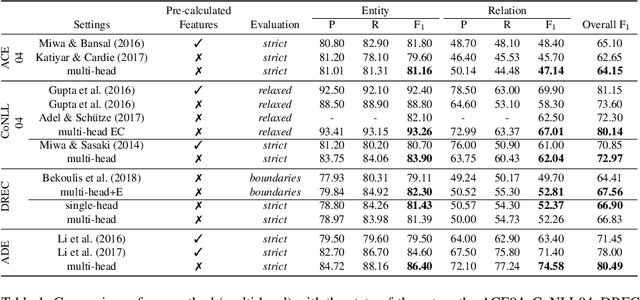
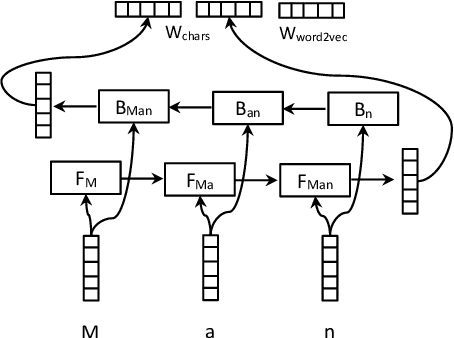
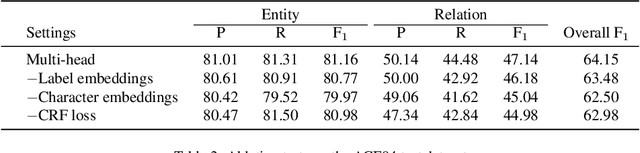
State-of-the-art models for joint entity recognition and relation extraction strongly rely on external natural language processing (NLP) tools such as POS (part-of-speech) taggers and dependency parsers. Thus, the performance of such joint models depends on the quality of the features obtained from these NLP tools. However, these features are not always accurate for various languages and contexts. In this paper, we propose a joint neural model which performs entity recognition and relation extraction simultaneously, without the need of any manually extracted features or the use of any external tool. Specifically, we model the entity recognition task using a CRF (Conditional Random Fields) layer and the relation extraction task as a multi-head selection problem (i.e., potentially identify multiple relations for each entity). We present an extensive experimental setup, to demonstrate the effectiveness of our method using datasets from various contexts (i.e., news, biomedical, real estate) and languages (i.e., English, Dutch). Our model outperforms the previous neural models that use automatically extracted features, while it performs within a reasonable margin of feature-based neural models, or even beats them.
* Preprint - Accepted for publication in Expert Systems with Applications
An attentive neural architecture for joint segmentation and parsing and its application to real estate ads
Mar 19, 2018

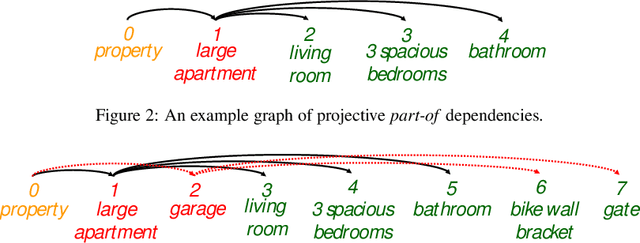
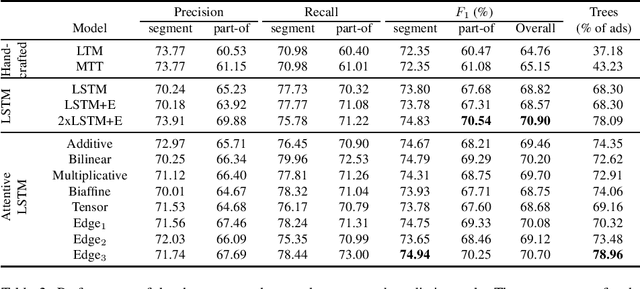
In processing human produced text using natural language processing (NLP) techniques, two fundamental subtasks that arise are (i) segmentation of the plain text into meaningful subunits (e.g., entities), and (ii) dependency parsing, to establish relations between subunits. In this paper, we develop a relatively simple and effective neural joint model that performs both segmentation and dependency parsing together, instead of one after the other as in most state-of-the-art works. We will focus in particular on the real estate ad setting, aiming to convert an ad to a structured description, which we name property tree, comprising the tasks of (1) identifying important entities of a property (e.g., rooms) from classifieds and (2) structuring them into a tree format. In this work, we propose a new joint model that is able to tackle the two tasks simultaneously and construct the property tree by (i) avoiding the error propagation that would arise from the subtasks one after the other in a pipelined fashion, and (ii) exploiting the interactions between the subtasks. For this purpose, we perform an extensive comparative study of the pipeline methods and the new proposed joint model, reporting an improvement of over three percentage points in the overall edge F1 score of the property tree. Also, we propose attention methods, to encourage our model to focus on salient tokens during the construction of the property tree. Thus we experimentally demonstrate the usefulness of attentive neural architectures for the proposed joint model, showcasing a further improvement of two percentage points in edge F1 score for our application.
* Preprint - Accepted for publication in Expert Systems with Applications