 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Fact Extraction and VERification: The FEVER case
Paper and Code
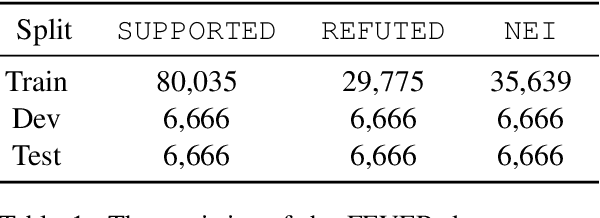
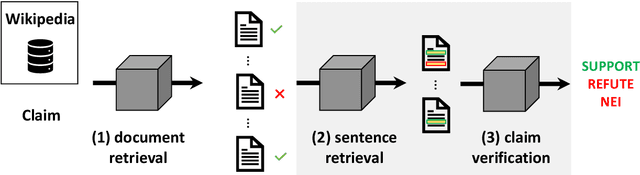
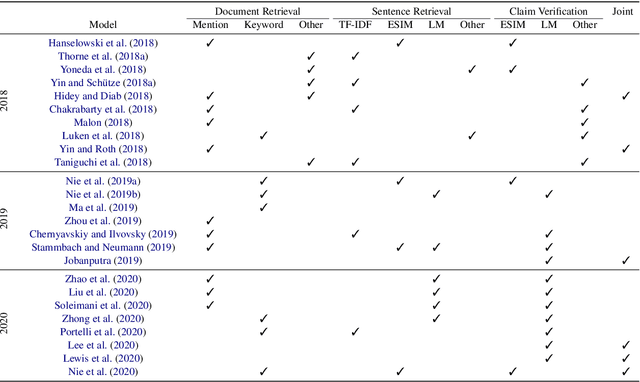
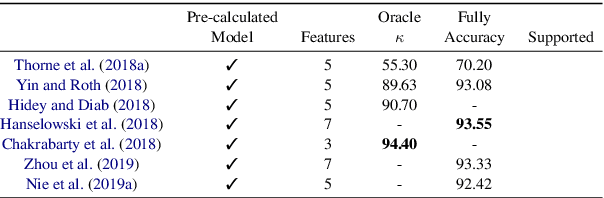
Fact Extraction and VERification (FEVER) is a recently introduced task which aims to identify the veracity of a given claim based on Wikipedia documents. A lot of methods have been proposed to address this problem which consists of the subtasks of (i) retrieving the relevant documents (and sentences) from Wikipedia and (ii) validating whether the information in the documents supports or refutes a given claim. This task is essential since it can be the building block of applications that require a deep understanding of the language such as fake news detection and medical claim verification. In this paper, we aim to get a better understanding of the challenges in the task by presenting the literature in a structured and comprehensive way. In addition, we describe the proposed methods by analyzing the technical perspectives of the different approaches and discussing the performance results on the FEVER dataset.