 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Cross-Lingual Transfer with Meta Learning
Paper and Code
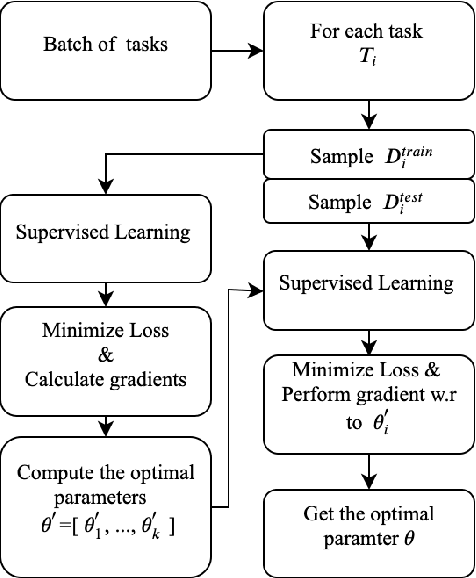
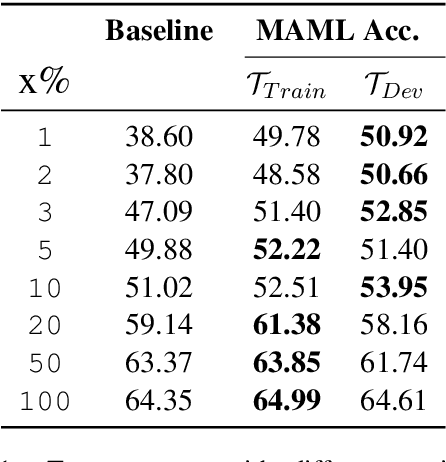
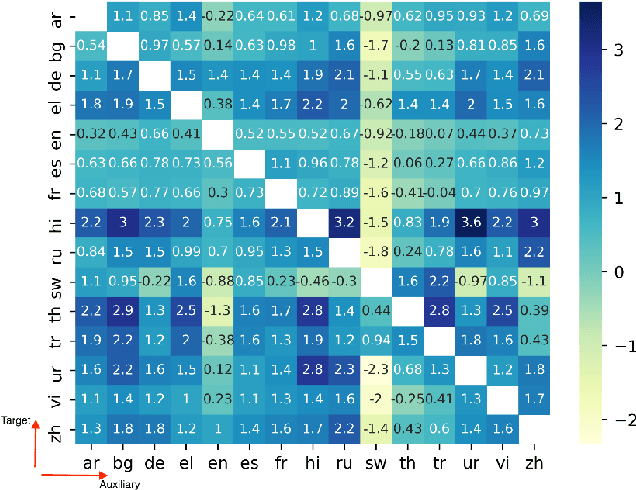
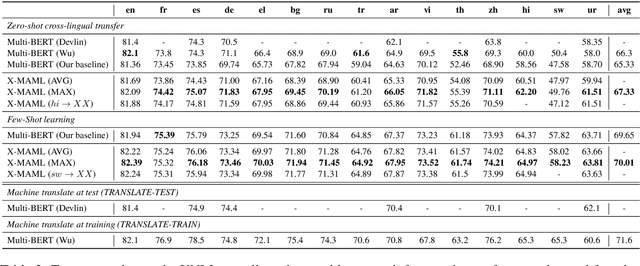
Learning what to share between tasks has been a topic of great importance recently, as strategic sharing of knowledge has been shown to improve the performance of downstream tasks. In multilingual applications, sharing of knowledge between languages is important when considering the fact that most languages in the world suffer from being under-resourced. In this paper, we consider the setting of training models on multiple different languages at the same time, when English training data, but little or no in-language data is available. We show that this challenging setup can be approached using meta-learning, where, in addition to training a source language model, another model learns to select which training instances are the most beneficial. We experiment using standard supervised, zero-shot cross-lingual, as well as few-shot cross-lingual settings for different natural language understanding tasks (natural language inference, question answering). Our extensive experimental setup demonstrates the consistent effectiveness of meta-learning in a total of 16 languages. We improve upon the state-of-the-art for zero-shot and few-shot NLI and QA tasks on two NLI datasets (i.e., MultiNLI and XNLI), and on the X-WikiRE dataset, respectively. We further conduct a comprehensive analysis, which indicates that the correlation of typological features between languages can further explain when parameter sharing learned via meta-learning is beneficial.