 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Event Detection as a Slot Filling Problem
Paper and Code
Sep 13, 2021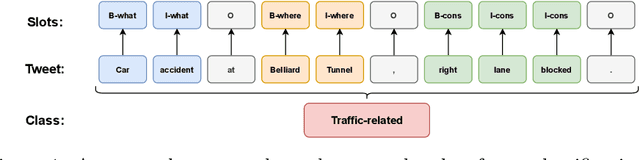
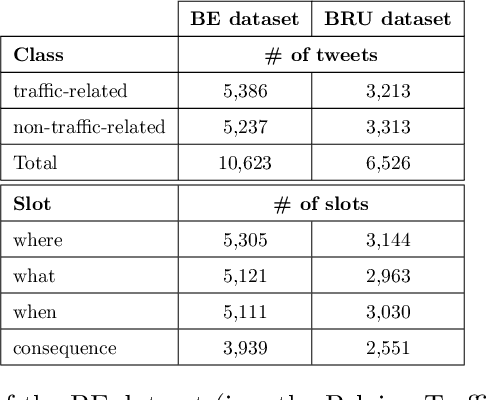
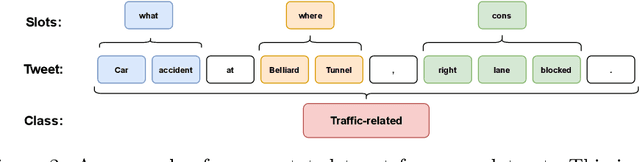

In this paper, we introduce the new problem of extracting fine-grained traffic information from Twitter streams by also making publicly available the two (constructed) traffic-related datasets from Belgium and the Brussels capital region. In particular, we experiment with several models to identify (i) whether a tweet is traffic-related or not, and (ii) in the case that the tweet is traffic-related to identify more fine-grained information regarding the event (e.g., the type of the event, where the event happened). To do so, we frame (i) the problem of identifying whether a tweet is a traffic-related event or not as a text classification subtask, and (ii) the problem of identifying more fine-grained traffic-related information as a slot filling subtask, where fine-grained information (e.g., where an event has happened) is represented as a slot/entity of a particular type. We propose the use of several methods that process the two subtasks either separately or in a joint setting, and we evaluate the effectiveness of the proposed methods for solving the traffic event detection problem. Experimental results indicate that the proposed architectures achieve high performance scores (i.e., more than 95% in terms of F$_{1}$ score) on the constructed datasets for both of the subtasks (i.e., text classification and slot filling) even in a transfer learning scenario. In addition, by incorporating tweet-level information in each of the tokens comprising the tweet (for the BERT-based model) can lead to a performance improvement for the joint setting.