 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned layered coding for Successive Refinement in the Wyner-Ziv Problem
Nov 06, 2023We propose a data-driven approach to explicitly learn the progressive encoding of a continuous source, which is successively decoded with increasing levels of quality and with the aid of correlated side information. This setup refers to the successive refinement of the Wyner-Ziv coding problem. Assuming ideal Slepian-Wolf coding, our approach employs recurrent neural networks (RNNs) to learn layered encoders and decoders for the quadratic Gaussian case. The models are trained by minimizing a variational bound on the rate-distortion function of the successively refined Wyner-Ziv coding problem. We demonstrate that RNNs can explicitly retrieve layered binning solutions akin to scalable nested quantization. Moreover, the rate-distortion performance of the scheme is on par with the corresponding monolithic Wyner-Ziv coding approach and is close to the rate-distortion bound.
Visualizing and Understanding Self-Supervised Vision Learning
Jun 20, 2022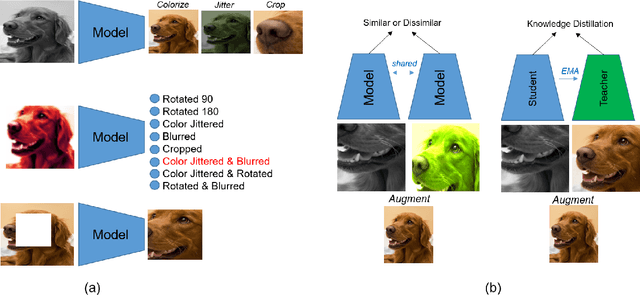
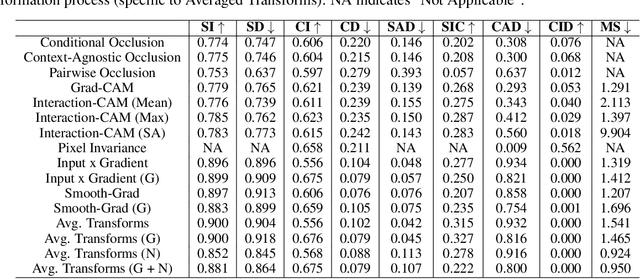
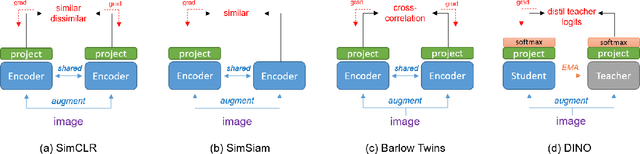
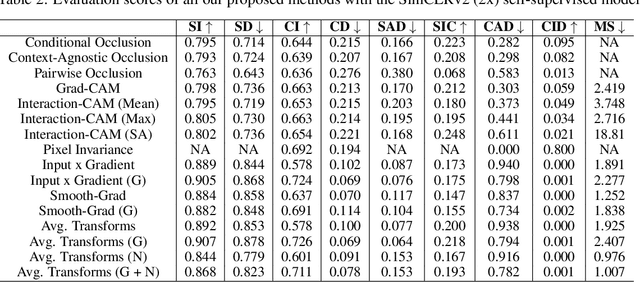
Self-Supervised vision learning has revolutionized deep learning, becoming the next big challenge in the domain and rapidly closing the gap with supervised methods on large computer vision benchmarks. With current models and training data exponentially growing, explaining and understanding these models becomes pivotal. We study the problem of explainable artificial intelligence in the domain of self-supervised learning for vision tasks, and present methods to understand networks trained with self-supervision and their inner workings. Given the huge diversity of self-supervised vision pretext tasks, we narrow our focus on understanding paradigms which learn from two views of the same image, and mainly aim to understand the pretext task. Our work focuses on explaining similarity learning, and is easily extendable to all other pretext tasks. We study two popular self-supervised vision models: SimCLR and Barlow Twins. We develop a total of six methods for visualizing and understanding these models: Perturbation-based methods (conditional occlusion, context-agnostic conditional occlusion and pairwise occlusion), Interaction-CAM, Feature Visualization, Model Difference Visualization, Averaged Transforms and Pixel Invaraince. Finally, we evaluate these explanations by translating well-known evaluation metrics tailored towards supervised image classification systems involving a single image, into the domain of self-supervised learning where two images are involved. Code is at: https://github.com/fawazsammani/xai-ssl
Explainable-by-design Semi-Supervised Representation Learning for COVID-19 Diagnosis from CT Imaging
Dec 02, 2020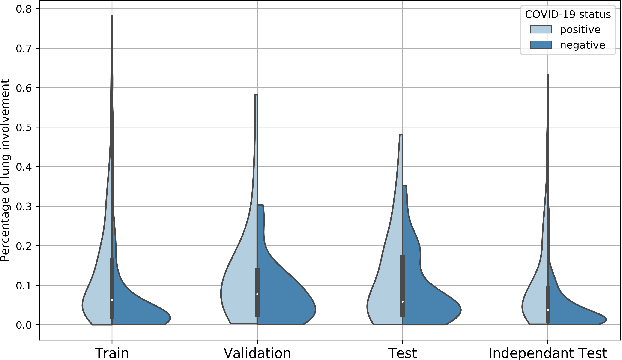
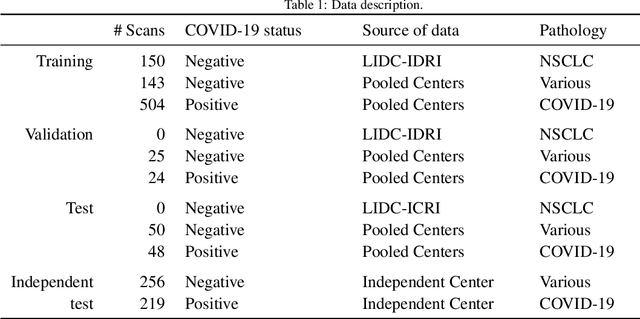
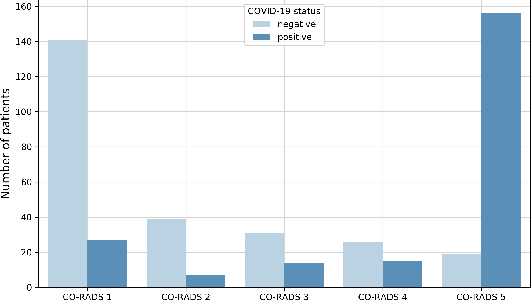
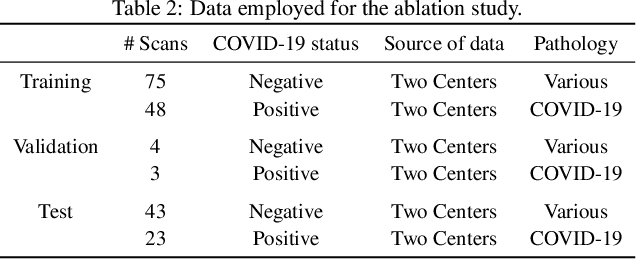
Our motivating application is a real-world problem: COVID-19 classification from CT imaging, for which we present an explainable Deep Learning approach based on a semi-supervised classification pipeline that employs variational autoencoders to extract efficient feature embedding. We have optimized the architecture of two different networks for CT images: (i) a novel conditional variational autoencoder (CVAE) with a specific architecture that integrates the class labels inside the encoder layers and uses side information with shared attention layers for the encoder, which make the most of the contextual clues for representation learning, and (ii) a downstream convolutional neural network for supervised classification using the encoder structure of the CVAE. With the explainable classification results, the proposed diagnosis system is very effective for COVID-19 classification. Based on the promising results obtained qualitatively and quantitatively, we envisage a wide deployment of our developed technique in large-scale clinical studies.Code is available at https://git.etrovub.be/AVSP/ct-based-covid-19-diagnostic-tool.git.
A Deep-Unfolded Reference-Based RPCA Network For Video Foreground-Background Separation
Oct 02, 2020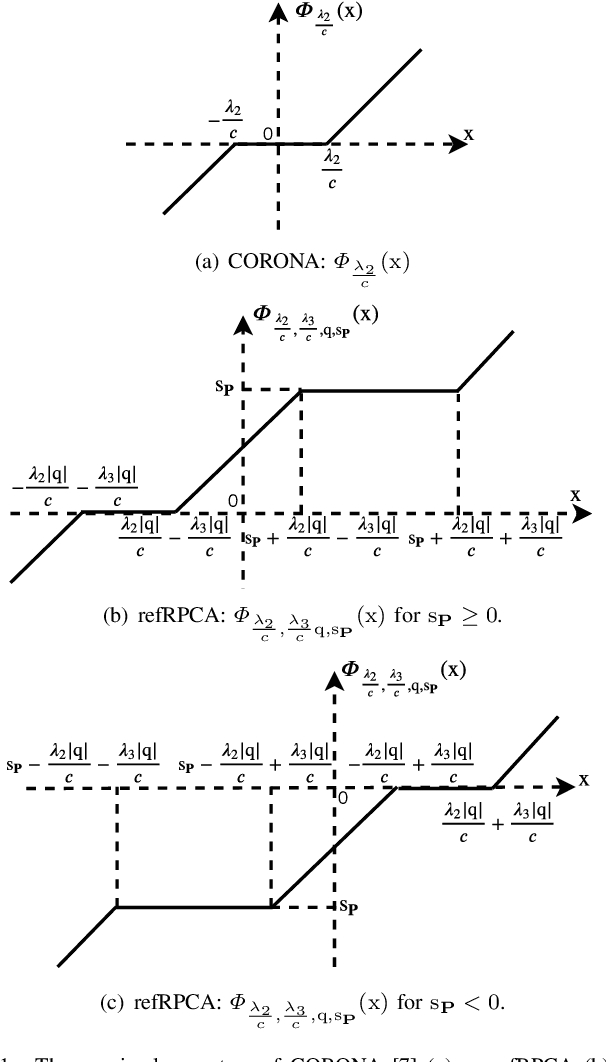
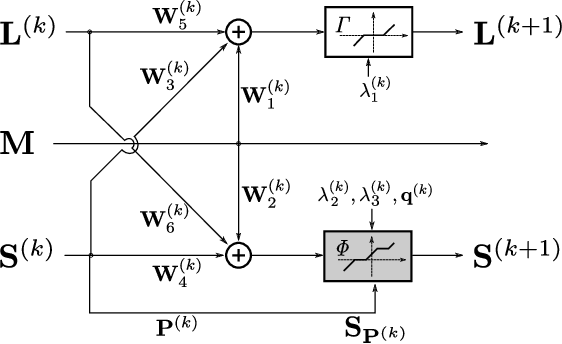
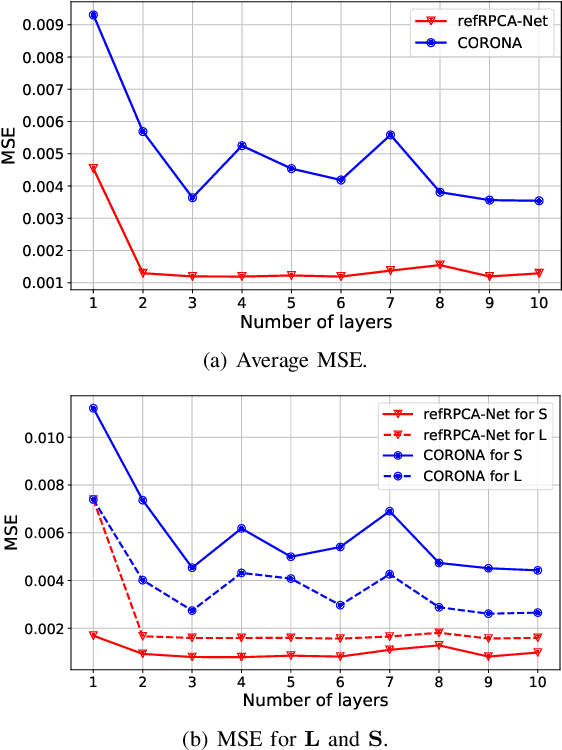

Deep unfolded neural networks are designed by unrolling the iterations of optimization algorithms. They can be shown to achieve faster convergence and higher accuracy than their optimization counterparts. This paper proposes a new deep-unfolding-based network design for the problem of Robust Principal Component Analysis (RPCA) with application to video foreground-background separation. Unlike existing designs, our approach focuses on modeling the temporal correlation between the sparse representations of consecutive video frames. To this end, we perform the unfolding of an iterative algorithm for solving reweighted $\ell_1$-$\ell_1$ minimization; this unfolding leads to a different proximal operator (a.k.a. different activation function) adaptively learned per neuron. Experimentation using the moving MNIST dataset shows that the proposed network outperforms a recently proposed state-of-the-art RPCA network in the task of video foreground-background separation.
Interpretable Deep Recurrent Neural Networks via Unfolding Reweighted $\ell_1$-$\ell_1$ Minimization: Architecture Design and Generalization Analysis
Mar 18, 2020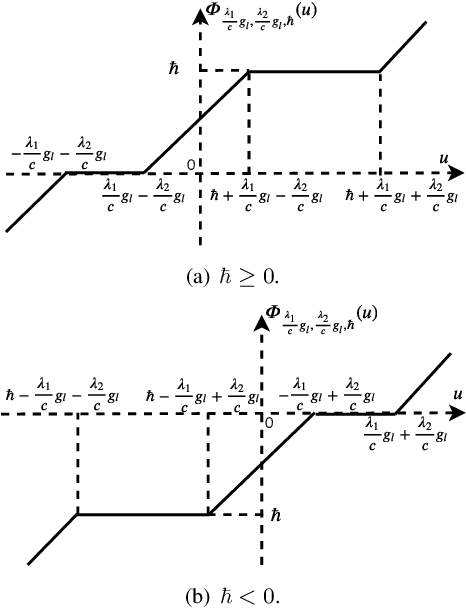

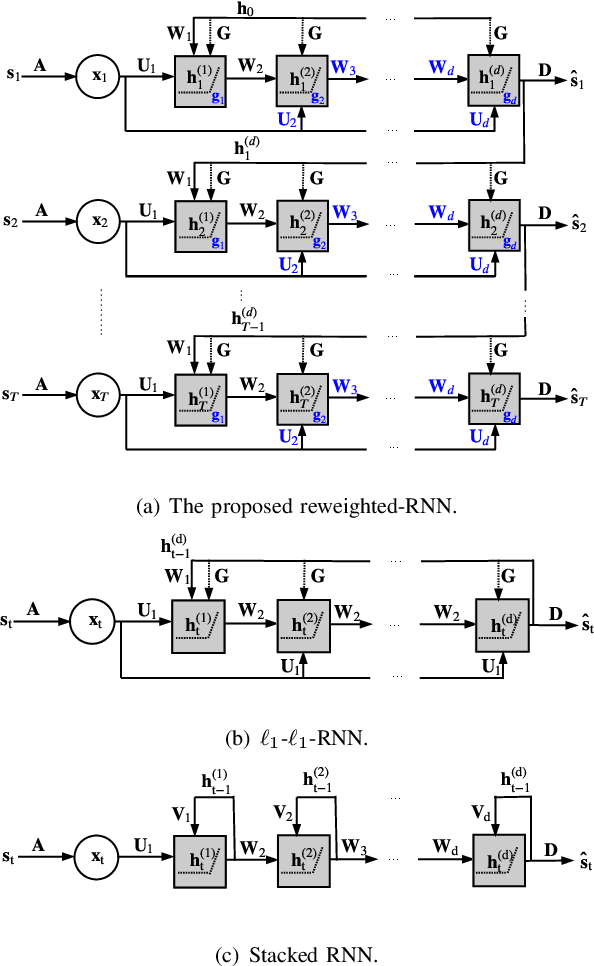
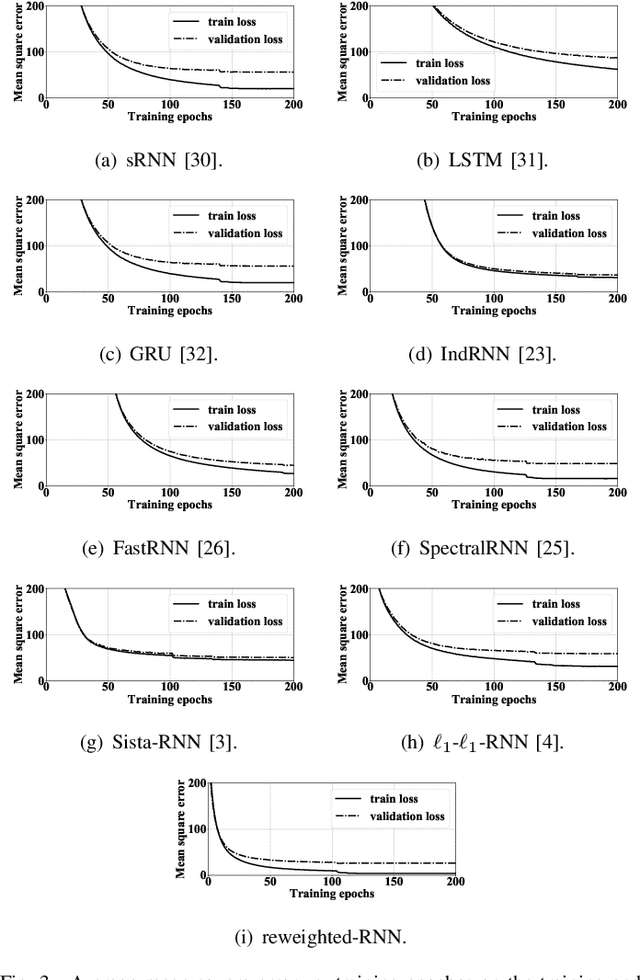
Deep unfolding methods---for example, the learned iterative shrinkage thresholding algorithm (LISTA)---design deep neural networks as learned variations of optimization methods. These networks have been shown to achieve faster convergence and higher accuracy than the original optimization methods. In this line of research, this paper develops a novel deep recurrent neural network (coined reweighted-RNN) by the unfolding of a reweighted $\ell_1$-$\ell_1$ minimization algorithm and applies it to the task of sequential signal reconstruction. To the best of our knowledge, this is the first deep unfolding method that explores reweighted minimization. Due to the underlying reweighted minimization model, our RNN has a different soft-thresholding function (alias, different activation functions) for each hidden unit in each layer. Furthermore, it has higher network expressivity than existing deep unfolding RNN models due to the over-parameterizing weights. Importantly, we establish theoretical generalization error bounds for the proposed reweighted-RNN model by means of Rademacher complexity. The bounds reveal that the parameterization of the proposed reweighted-RNN ensures good generalization. We apply the proposed reweighted-RNN to the problem of video frame reconstruction from low-dimensional measurements, that is, sequential frame reconstruction. The experimental results on the moving MNIST dataset demonstrate that the proposed deep reweighted-RNN significantly outperforms existing RNN models.