 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Negation Is a Geometry Problem in Vision-Language Models
Mar 20, 2026Joint Vision-Language Embedding models such as CLIP typically fail at understanding negation in text queries - for example, failing to distinguish "no" in the query: "a plain blue shirt with no logos". Prior work has largely addressed this limitation through data-centric approaches, fine-tuning CLIP on large-scale synthetic negation datasets. However, these efforts are commonly evaluated using retrieval-based metrics that cannot reliably reflect whether negation is actually understood. In this paper, we identify two key limitations of such evaluation metrics and investigate an alternative evaluation framework based on Multimodal LLMs-as-a-judge, which typically excel at understanding simple yes/no questions about image content, providing a fair evaluation of negation understanding in CLIP models. We then ask whether there already exists a direction in the CLIP embedding space associated with negation. We find evidence that such a direction exists, and show that it can be manipulated through test-time intervention via representation engineering to steer CLIP toward negation-aware behavior without any fine-tuning. Finally, we test negation understanding on non-common image-text samples to evaluate generalization under distribution shifts.
Temporal Concept Dynamics in Diffusion Models via Prompt-Conditioned Interventions
Dec 09, 2025Diffusion models are usually evaluated by their final outputs, gradually denoising random noise into meaningful images. Yet, generation unfolds along a trajectory, and analyzing this dynamic process is crucial for understanding how controllable, reliable, and predictable these models are in terms of their success/failure modes. In this work, we ask the question: when does noise turn into a specific concept (e.g., age) and lock in the denoising trajectory? We propose PCI (Prompt-Conditioned Intervention) to study this question. PCI is a training-free and model-agnostic framework for analyzing concept dynamics through diffusion time. The central idea is the analysis of Concept Insertion Success (CIS), defined as the probability that a concept inserted at a given timestep is preserved and reflected in the final image, offering a way to characterize the temporal dynamics of concept formation. Applied to several state-of-the-art text-to-image diffusion models and a broad taxonomy of concepts, PCI reveals diverse temporal behaviors across diffusion models, in which certain phases of the trajectory are more favorable to specific concepts even within the same concept type. These findings also provide actionable insights for text-driven image editing, highlighting when interventions are most effective without requiring access to model internals or training, and yielding quantitatively stronger edits that achieve a balance of semantic accuracy and content preservation than strong baselines. Code is available at: https://github.com/adagorgun/PCI-Prompt-Controlled-Interventions
Unlocking Open-Set Language Accessibility in Vision Models
Mar 14, 2025



Visual classifiers offer high-dimensional feature representations that are challenging to interpret and analyze. Text, in contrast, provides a more expressive and human-friendly interpretable medium for understanding and analyzing model behavior. We propose a simple, yet powerful method for reformulating any visual classifier so that it can be accessed with open-set text queries without compromising its original performance. Our approach is label-free, efficient, and preserves the underlying classifier's distribution and reasoning processes. We thus unlock several text-based interpretability applications for any classifier. We apply our method on 40 visual classifiers and demonstrate two primary applications: 1) building both label-free and zero-shot concept bottleneck models and therefore converting any classifier to be inherently-interpretable and 2) zero-shot decoding of visual features into natural language. In both applications, we achieve state-of-the-art results, greatly outperforming existing works. Our method enables text approaches for interpreting visual classifiers.
Interpreting and Analyzing CLIP's Zero-Shot Image Classification via Mutual Knowledge
Oct 16, 2024Contrastive Language-Image Pretraining (CLIP) performs zero-shot image classification by mapping images and textual class representation into a shared embedding space, then retrieving the class closest to the image. This work provides a new approach for interpreting CLIP models for image classification from the lens of mutual knowledge between the two modalities. Specifically, we ask: what concepts do both vision and language CLIP encoders learn in common that influence the joint embedding space, causing points to be closer or further apart? We answer this question via an approach of textual concept-based explanations, showing their effectiveness, and perform an analysis encompassing a pool of 13 CLIP models varying in architecture, size and pretraining datasets. We explore those different aspects in relation to mutual knowledge, and analyze zero-shot predictions. Our approach demonstrates an effective and human-friendly way of understanding zero-shot classification decisions with CLIP.
Uni-NLX: Unifying Textual Explanations for Vision and Vision-Language Tasks
Aug 17, 2023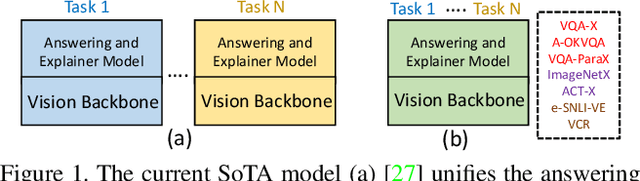
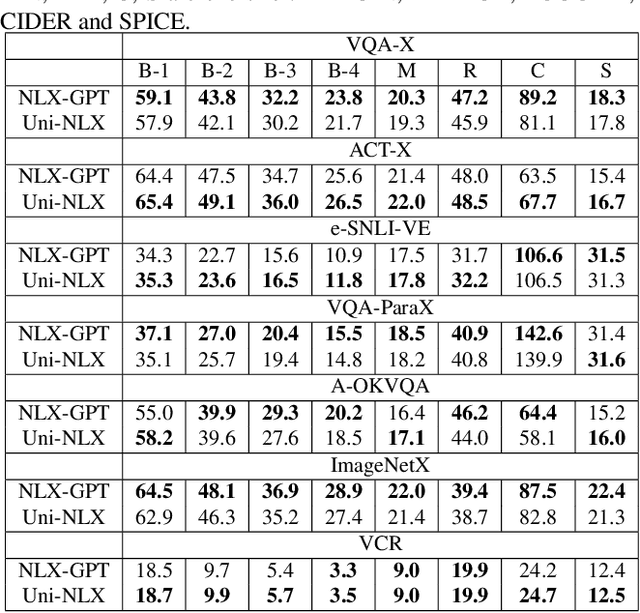

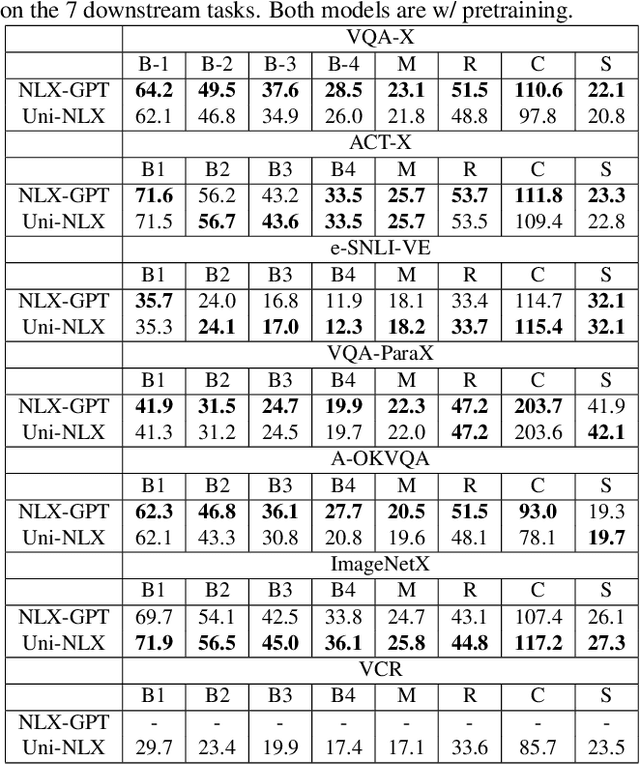
Natural Language Explanations (NLE) aim at supplementing the prediction of a model with human-friendly natural text. Existing NLE approaches involve training separate models for each downstream task. In this work, we propose Uni-NLX, a unified framework that consolidates all NLE tasks into a single and compact multi-task model using a unified training objective of text generation. Additionally, we introduce two new NLE datasets: 1) ImageNetX, a dataset of 144K samples for explaining ImageNet categories, and 2) VQA-ParaX, a dataset of 123K samples for explaining the task of Visual Question Answering (VQA). Both datasets are derived leveraging large language models (LLMs). By training on the 1M combined NLE samples, our single unified framework is capable of simultaneously performing seven NLE tasks including VQA, visual recognition and visual reasoning tasks with 7X fewer parameters, demonstrating comparable performance to the independent task-specific models in previous approaches, and in certain tasks even outperforming them. Code is at https://github.com/fawazsammani/uni-nlx
Visualizing and Understanding Self-Supervised Vision Learning
Jun 20, 2022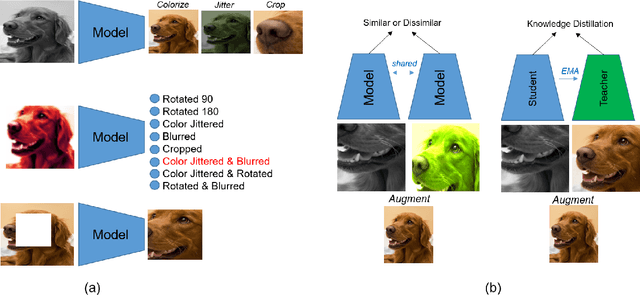
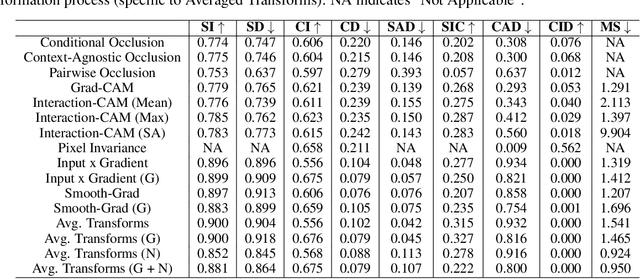
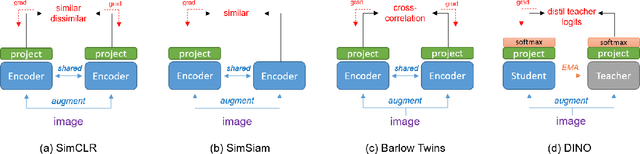
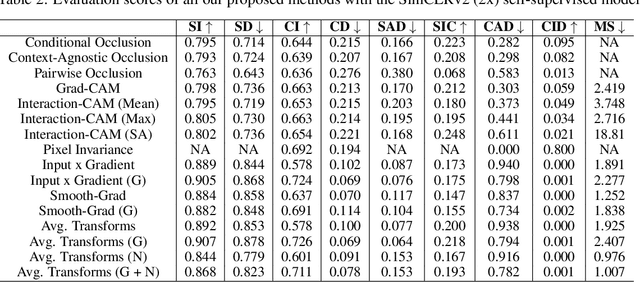
Self-Supervised vision learning has revolutionized deep learning, becoming the next big challenge in the domain and rapidly closing the gap with supervised methods on large computer vision benchmarks. With current models and training data exponentially growing, explaining and understanding these models becomes pivotal. We study the problem of explainable artificial intelligence in the domain of self-supervised learning for vision tasks, and present methods to understand networks trained with self-supervision and their inner workings. Given the huge diversity of self-supervised vision pretext tasks, we narrow our focus on understanding paradigms which learn from two views of the same image, and mainly aim to understand the pretext task. Our work focuses on explaining similarity learning, and is easily extendable to all other pretext tasks. We study two popular self-supervised vision models: SimCLR and Barlow Twins. We develop a total of six methods for visualizing and understanding these models: Perturbation-based methods (conditional occlusion, context-agnostic conditional occlusion and pairwise occlusion), Interaction-CAM, Feature Visualization, Model Difference Visualization, Averaged Transforms and Pixel Invaraince. Finally, we evaluate these explanations by translating well-known evaluation metrics tailored towards supervised image classification systems involving a single image, into the domain of self-supervised learning where two images are involved. Code is at: https://github.com/fawazsammani/xai-ssl
NLX-GPT: A Model for Natural Language Explanations in Vision and Vision-Language Tasks
Mar 09, 2022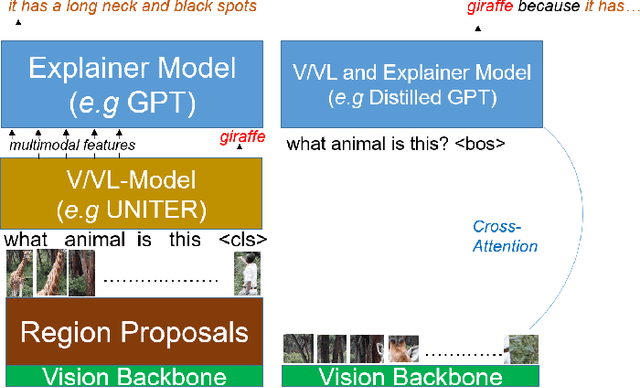


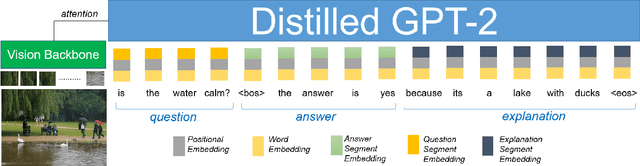
Natural language explanation (NLE) models aim at explaining the decision-making process of a black box system via generating natural language sentences which are human-friendly, high-level and fine-grained. Current NLE models explain the decision-making process of a vision or vision-language model (a.k.a., task model), e.g., a VQA model, via a language model (a.k.a., explanation model), e.g., GPT. Other than the additional memory resources and inference time required by the task model, the task and explanation models are completely independent, which disassociates the explanation from the reasoning process made to predict the answer. We introduce NLX-GPT, a general, compact and faithful language model that can simultaneously predict an answer and explain it. We first conduct pre-training on large scale data of image-caption pairs for general understanding of images, and then formulate the answer as a text prediction task along with the explanation. Without region proposals nor a task model, our resulting overall framework attains better evaluation scores, contains much less parameters and is 15$\times$ faster than the current SoA model. We then address the problem of evaluating the explanations which can be in many times generic, data-biased and can come in several forms. We therefore design 2 new evaluation measures: (1) explain-predict and (2) retrieval-based attack, a self-evaluation framework that requires no labels. Code is at: https://github.com/fawazsammani/nlxgpt.
Show, Edit and Tell: A Framework for Editing Image Captions
Mar 06, 2020
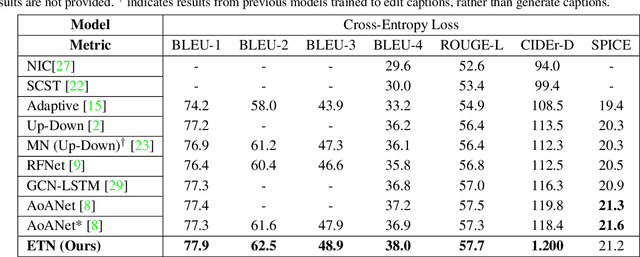

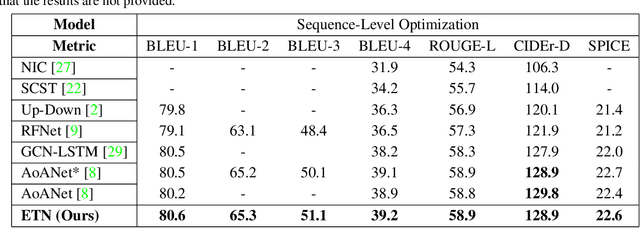
Most image captioning frameworks generate captions directly from images, learning a mapping from visual features to natural language. However, editing existing captions can be easier than generating new ones from scratch. Intuitively, when editing captions, a model is not required to learn information that is already present in the caption (i.e. sentence structure), enabling it to focus on fixing details (e.g. replacing repetitive words). This paper proposes a novel approach to image captioning based on iterative adaptive refinement of an existing caption. Specifically, our caption-editing model consisting of two sub-modules: (1) EditNet, a language module with an adaptive copy mechanism (Copy-LSTM) and a Selective Copy Memory Attention mechanism (SCMA), and (2) DCNet, an LSTM-based denoising auto-encoder. These components enable our model to directly copy from and modify existing captions. Experiments demonstrate that our new approach achieves state-of-art performance on the MS COCO dataset both with and without sequence-level training.
Look and Modify: Modification Networks for Image Captioning
Sep 07, 2019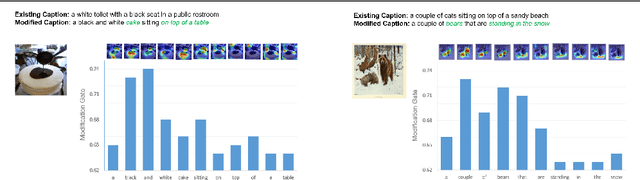
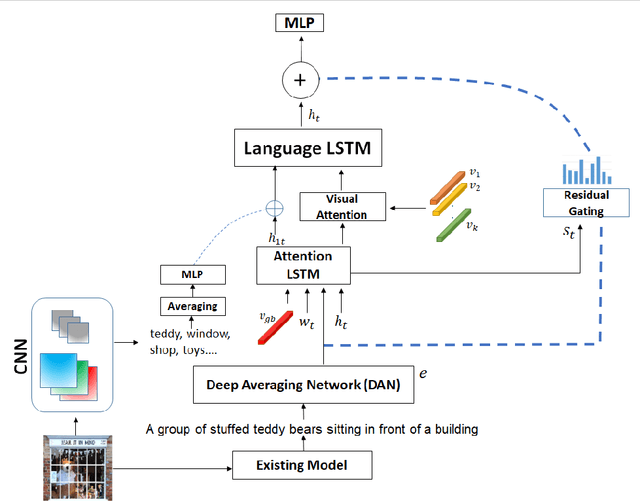


Attention-based neural encoder-decoder frameworks have been widely used for image captioning. Many of these frameworks deploy their full focus on generating the caption from scratch by relying solely on the image features or the object detection regional features. In this paper, we introduce a novel framework that learns to modify existing captions from a given framework by modeling the residual information, where at each timestep the model learns what to keep, remove or add to the existing caption allowing the model to fully focus on "what to modify" rather than on "what to predict". We evaluate our method on the COCO dataset, trained on top of several image captioning frameworks and show that our model successfully modifies captions yielding better ones with better evaluation scores.