 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing and Understanding Self-Supervised Vision Learning
Paper and Code
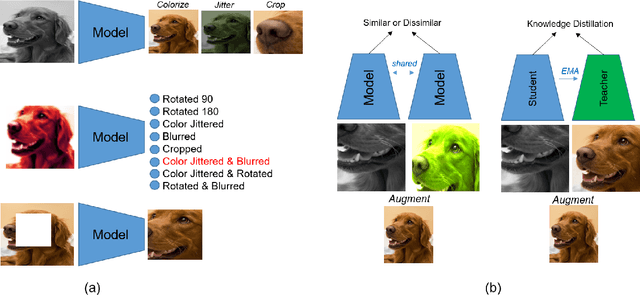
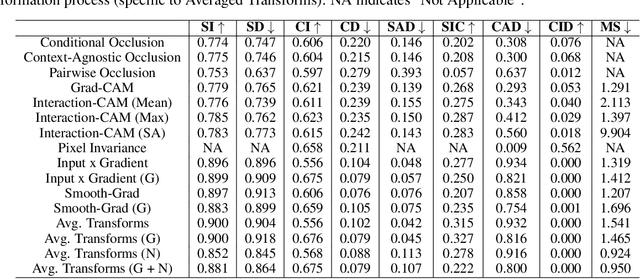
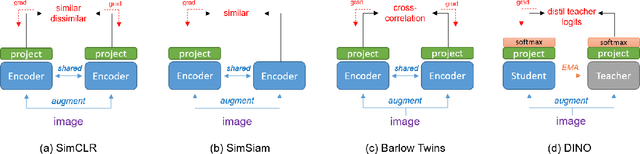
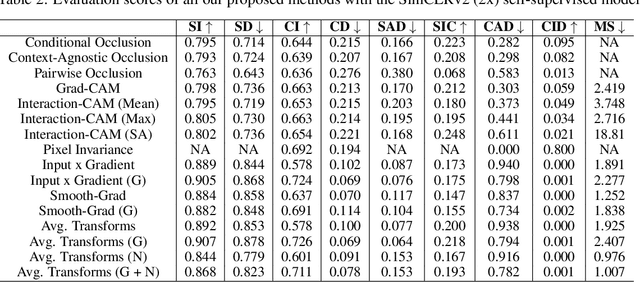
Self-Supervised vision learning has revolutionized deep learning, becoming the next big challenge in the domain and rapidly closing the gap with supervised methods on large computer vision benchmarks. With current models and training data exponentially growing, explaining and understanding these models becomes pivotal. We study the problem of explainable artificial intelligence in the domain of self-supervised learning for vision tasks, and present methods to understand networks trained with self-supervision and their inner workings. Given the huge diversity of self-supervised vision pretext tasks, we narrow our focus on understanding paradigms which learn from two views of the same image, and mainly aim to understand the pretext task. Our work focuses on explaining similarity learning, and is easily extendable to all other pretext tasks. We study two popular self-supervised vision models: SimCLR and Barlow Twins. We develop a total of six methods for visualizing and understanding these models: Perturbation-based methods (conditional occlusion, context-agnostic conditional occlusion and pairwise occlusion), Interaction-CAM, Feature Visualization, Model Difference Visualization, Averaged Transforms and Pixel Invaraince. Finally, we evaluate these explanations by translating well-known evaluation metrics tailored towards supervised image classification systems involving a single image, into the domain of self-supervised learning where two images are involved. Code is at: https://github.com/fawazsammani/xai-ssl