 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook and Modify: Modification Networks for Image Captioning
Paper and Code
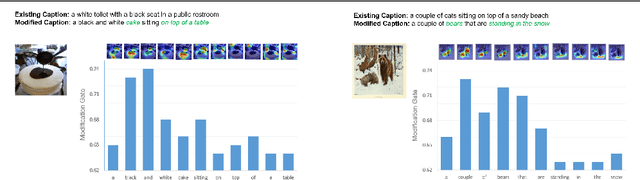
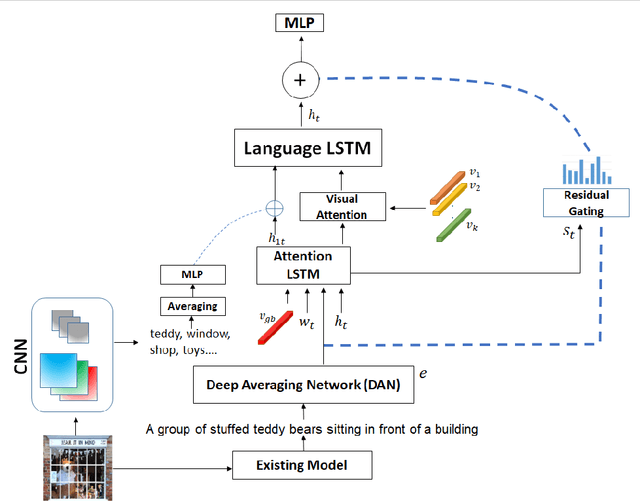


Attention-based neural encoder-decoder frameworks have been widely used for image captioning. Many of these frameworks deploy their full focus on generating the caption from scratch by relying solely on the image features or the object detection regional features. In this paper, we introduce a novel framework that learns to modify existing captions from a given framework by modeling the residual information, where at each timestep the model learns what to keep, remove or add to the existing caption allowing the model to fully focus on "what to modify" rather than on "what to predict". We evaluate our method on the COCO dataset, trained on top of several image captioning frameworks and show that our model successfully modifies captions yielding better ones with better evaluation scores.