 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C
Fusing Event-based Camera and Radar for SLAM Using Spiking Neural Networks with Continual STDP Learning
Oct 09, 2022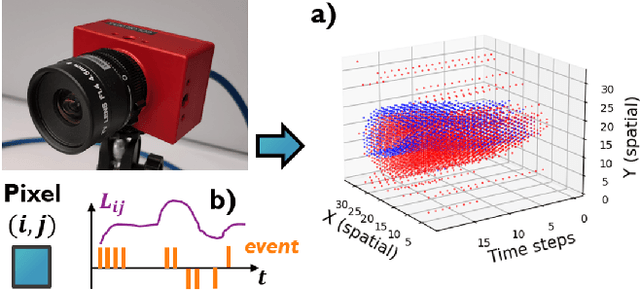

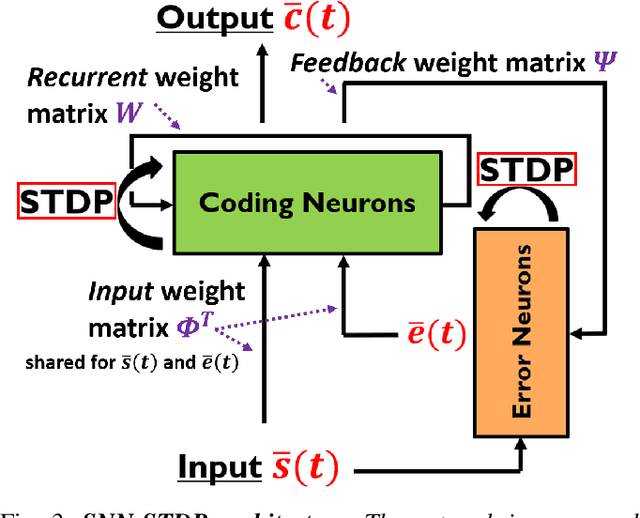
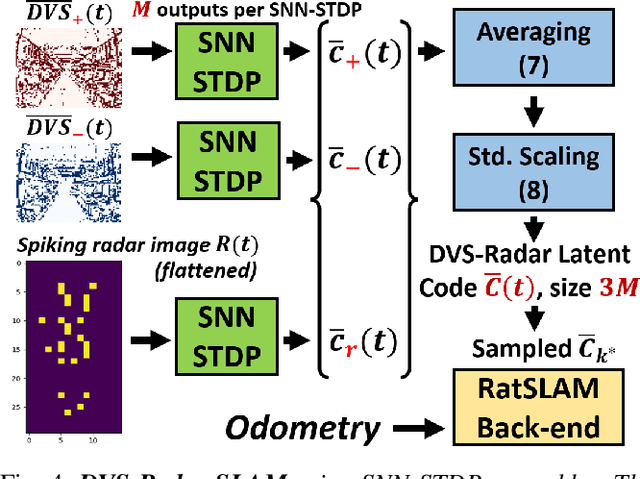
This work proposes a first-of-its-kind SLAM architecture fusing an event-based camera and a Frequency Modulated Continuous Wave (FMCW) radar for drone navigation. Each sensor is processed by a bio-inspired Spiking Neural Network (SNN) with continual Spike-Timing-Dependent Plasticity (STDP) learning, as observed in the brain. In contrast to most learning-based SLAM systems%, which a) require the acquisition of a representative dataset of the environment in which navigation must be performed and b) require an off-line training phase, our method does not require any offline training phase, but rather the SNN continuously learns features from the input data on the fly via STDP. At the same time, the SNN outputs are used as feature descriptors for loop closure detection and map correction. We conduct numerous experiments to benchmark our system against state-of-the-art RGB methods and we demonstrate the robustness of our DVS-Radar SLAM approach under strong lighting variations.
Learning to SLAM on the Fly in Unknown Environments: A Continual Learning Approach for Drones in Visually Ambiguous Scenes
Aug 27, 2022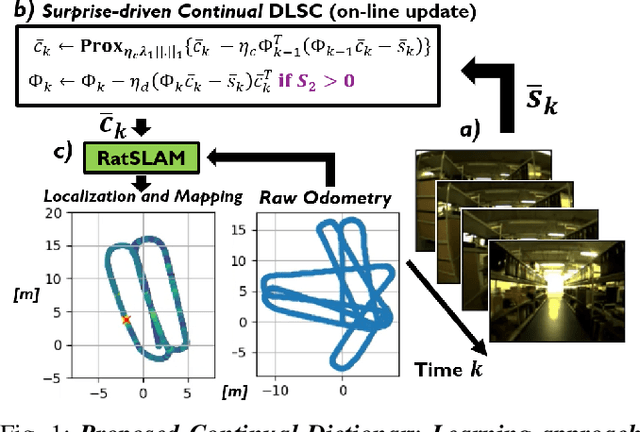

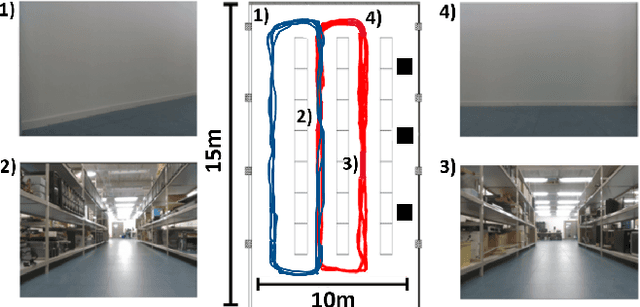
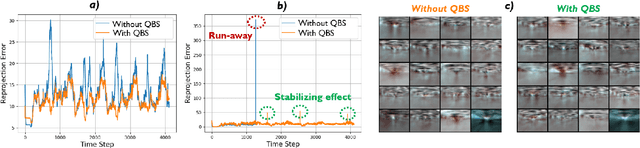
Learning to safely navigate in unknown environments is an important task for autonomous drones used in surveillance and rescue operations. In recent years, a number of learning-based Simultaneous Localisation and Mapping (SLAM) systems relying on deep neural networks (DNNs) have been proposed for applications where conventional feature descriptors do not perform well. However, such learning-based SLAM systems rely on DNN feature encoders trained offline in typical deep learning settings. This makes them less suited for drones deployed in environments unseen during training, where continual adaptation is paramount. In this paper, we present a new method for learning to SLAM on the fly in unknown environments, by modulating a low-complexity Dictionary Learning and Sparse Coding (DLSC) pipeline with a newly proposed Quadratic Bayesian Surprise (QBS) factor. We experimentally validate our approach with data collected by a drone in a challenging warehouse scenario, where the high number of ambiguous scenes makes visual disambiguation hard.
Representation Learning with Information Theory for COVID-19 Detection
Jul 04, 2022


Successful data representation is a fundamental factor in machine learning based medical imaging analysis. Deep Learning (DL) has taken an essential role in robust representation learning. However, the inability of deep models to generalize to unseen data can quickly overfit intricate patterns. Thereby, we can conveniently implement strategies to aid deep models in discovering useful priors from data to learn their intrinsic properties. Our model, which we call a dual role network (DRN), uses a dependency maximization approach based on Least Squared Mutual Information (LSMI). The LSMI leverages dependency measures to ensure representation invariance and local smoothness. While prior works have used information theory measures like mutual information, known to be computationally expensive due to a density estimation step, our LSMI formulation alleviates the issues of intractable mutual information estimation and can be used to approximate it. Experiments on CT based COVID-19 Detection and COVID-19 Severity Detection benchmarks demonstrate the effectiveness of our method.
Continuously Learning to Detect People on the Fly: A Bio-inspired Visual System for Drones
Feb 20, 2022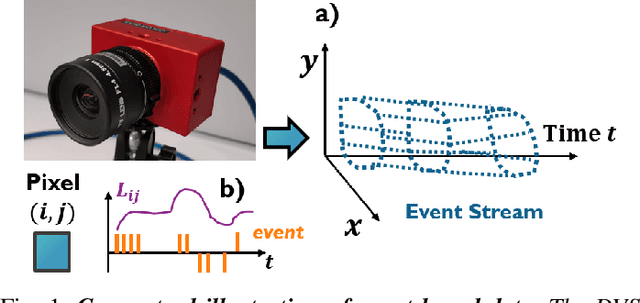
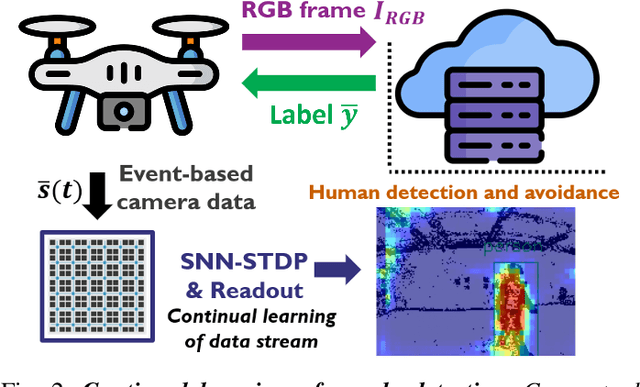
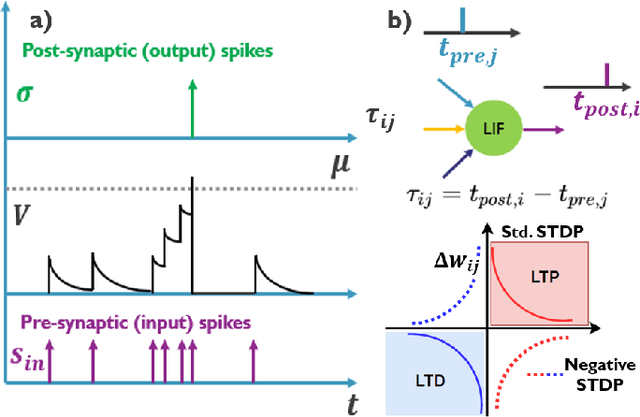
This paper demonstrates for the first time that a biologically-plausible spiking neural network (SNN) equipped with Spike-Timing-Dependent Plasticity (STDP) can continuously learn to detect walking people on the fly using retina-inspired, event-based cameras. Our pipeline works as follows. First, a short sequence of event data ($<2$ minutes), capturing a walking human by a flying drone, is forwarded to a convolutional SNNSTDP system which also receives teacher spiking signals from a readout (forming a semi-supervised system). Then, STDP adaptation is stopped and the learned system is assessed on testing sequences. We conduct several experiments to study the effect of key parameters in our system and to compare it against conventionally-trained CNNs. We show that our system reaches a higher peak $F_1$ score (+19%) compared to CNNs with event-based camera frames, while enabling on-line adaptation.
Learning Event-based Spatio-Temporal Feature Descriptors via Local Synaptic Plasticity: A Biologically-realistic Perspective of Computer Vision
Nov 04, 2021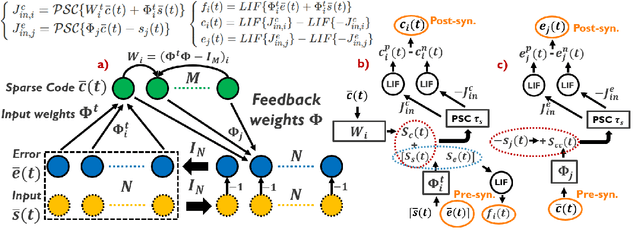
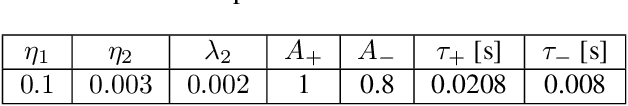
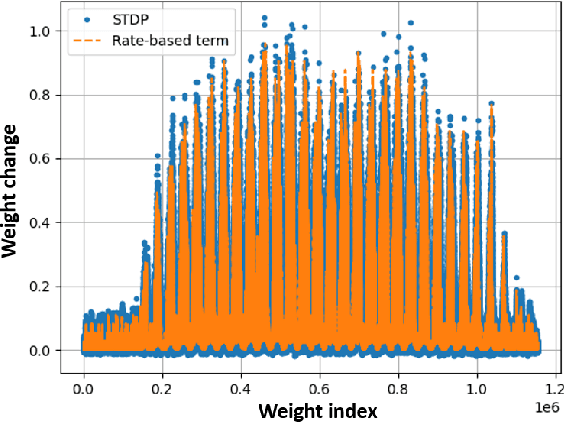
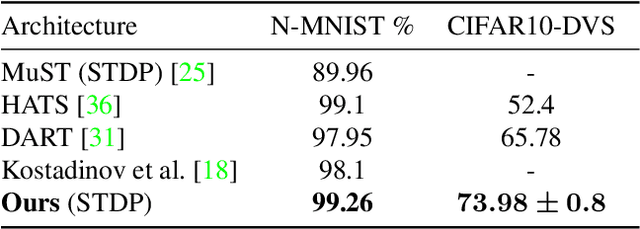
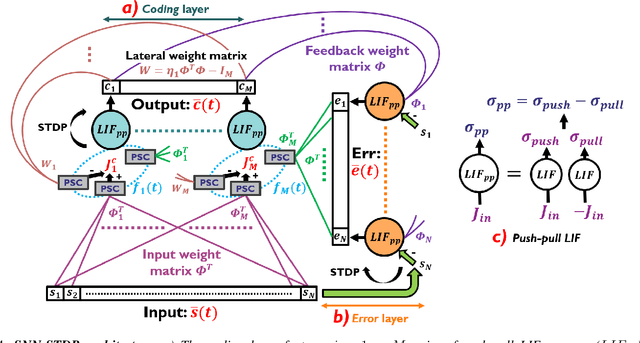
We present an optimization-based theory describing spiking cortical ensembles equipped with Spike-Timing-Dependent Plasticity (STDP) learning, as empirically observed in the visual cortex. Using our methods, we build a class of fully-connected, convolutional and action-based feature descriptors for event-based camera that we respectively assess on N-MNIST, challenging CIFAR10-DVS and on the IBM DVS128 gesture dataset. We report significant accuracy improvements compared to conventional state-of-the-art event-based feature descriptors (+8% on CIFAR10-DVS). We report large improvements in accuracy compared to state-of-the-art STDP-based systems (+10% on N-MNIST, +7.74% on IBM DVS128 Gesture). In addition to ultra-low-power learning in neuromorphic edge devices, our work helps paving the way towards a biologically-realistic, optimization-based theory of cortical vision.
Explainable-by-design Semi-Supervised Representation Learning for COVID-19 Diagnosis from CT Imaging
Dec 02, 2020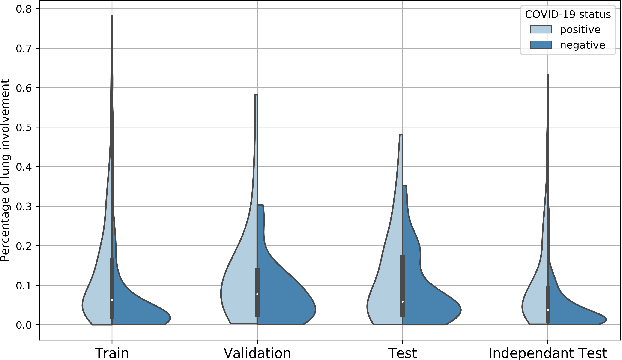
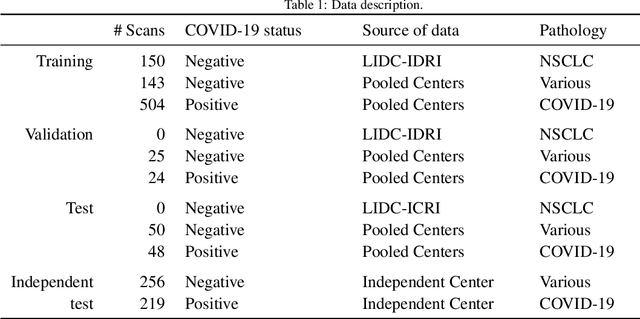
Our motivating application is a real-world problem: COVID-19 classification from CT imaging, for which we present an explainable Deep Learning approach based on a semi-supervised classification pipeline that employs variational autoencoders to extract efficient feature embedding. We have optimized the architecture of two different networks for CT images: (i) a novel conditional variational autoencoder (CVAE) with a specific architecture that integrates the class labels inside the encoder layers and uses side information with shared attention layers for the encoder, which make the most of the contextual clues for representation learning, and (ii) a downstream convolutional neural network for supervised classification using the encoder structure of the CVAE. With the explainable classification results, the proposed diagnosis system is very effective for COVID-19 classification. Based on the promising results obtained qualitatively and quantitatively, we envisage a wide deployment of our developed technique in large-scale clinical studies.Code is available at https://git.etrovub.be/AVSP/ct-based-covid-19-diagnostic-tool.git.
Efficient Convolutional Auto-Encoding via Random Convexification and Frequency-Domain Minimization
Nov 28, 2016
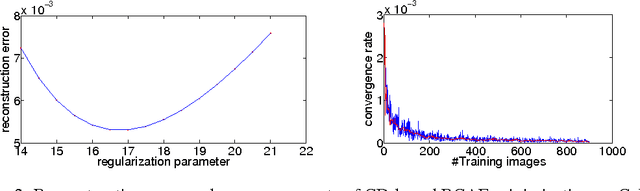

The omnipresence of deep learning architectures such as deep convolutional neural networks (CNN)s is fueled by the synergistic combination of ever-increasing labeled datasets and specialized hardware. Despite the indisputable success, the reliance on huge amounts of labeled data and specialized hardware can be a limiting factor when approaching new applications. To help alleviating these limitations, we propose an efficient learning strategy for layer-wise unsupervised training of deep CNNs on conventional hardware in acceptable time. Our proposed strategy consists of randomly convexifying the reconstruction contractive auto-encoding (RCAE) learning objective and solving the resulting large-scale convex minimization problem in the frequency domain via coordinate descent (CD). The main advantages of our proposed learning strategy are: (1) single tunable optimization parameter; (2) fast and guaranteed convergence; (3) possibilities for full parallelization. Numerical experiments show that our proposed learning strategy scales (in the worst case) linearly with image size, number of filters and filter size.