 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacEDiM: A Face Embedding Distribution Model for Few-Shot Biometric Authentication of Cattle
Feb 28, 2023This work proposes to solve the problem of few-shot biometric authentication by computing the Mahalanobis distance between testing embeddings and a multivariate Gaussian distribution of training embeddings obtained using pre-trained CNNs. Experimental results show that models pre-trained on the ImageNet dataset significantly outperform models pre-trained on human faces. With a VGG16 model, we obtain a FRR of 1.18% for a FAR of 1.25% on a dataset of 20 cattle identities.
On the Acceleration of Deep Neural Network Inference using Quantized Compressed Sensing
Aug 23, 2021Accelerating deep neural network (DNN) inference on resource-limited devices is one of the most important barriers to ensuring a wider and more inclusive adoption. To alleviate this, DNN binary quantization for faster convolution and memory savings is one of the most promising strategies despite its serious drop in accuracy. The present paper therefore proposes a novel binary quantization function based on quantized compressed sensing (QCS). Theoretical arguments conjecture that our proposal preserves the practical benefits of standard methods, while reducing the quantization error and the resulting drop in accuracy.
Efficient Convolutional Auto-Encoding via Random Convexification and Frequency-Domain Minimization
Nov 28, 2016
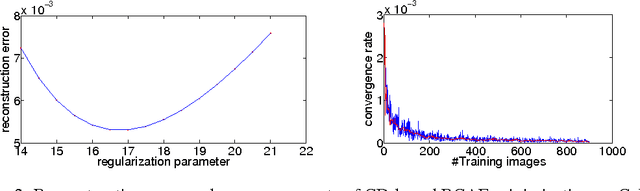

The omnipresence of deep learning architectures such as deep convolutional neural networks (CNN)s is fueled by the synergistic combination of ever-increasing labeled datasets and specialized hardware. Despite the indisputable success, the reliance on huge amounts of labeled data and specialized hardware can be a limiting factor when approaching new applications. To help alleviating these limitations, we propose an efficient learning strategy for layer-wise unsupervised training of deep CNNs on conventional hardware in acceptable time. Our proposed strategy consists of randomly convexifying the reconstruction contractive auto-encoding (RCAE) learning objective and solving the resulting large-scale convex minimization problem in the frequency domain via coordinate descent (CD). The main advantages of our proposed learning strategy are: (1) single tunable optimization parameter; (2) fast and guaranteed convergence; (3) possibilities for full parallelization. Numerical experiments show that our proposed learning strategy scales (in the worst case) linearly with image size, number of filters and filter size.